 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Adaptive Detection Transformer for Single-Source Domain Generalized Object Detection
Apr 29, 2025



Single-source Domain Generalization (SDG) in object detection aims to develop a detector using only data from a source domain that can exhibit strong generalization capability when applied to unseen target domains. Existing methods are built upon CNN-based detectors and primarily improve robustness by employing carefully designed data augmentation strategies integrated with feature alignment techniques. However, data augmentation methods have inherent drawbacks; they are only effective when the augmented sample distribution approximates or covers the unseen scenarios, thus failing to enhance generalization across all unseen domains. Furthermore, while the recent Detection Transformer (DETR) has demonstrated superior generalization capability in domain adaptation tasks due to its efficient global information extraction, its potential in SDG tasks remains unexplored. To this end, we introduce a strong DETR-based detector named the Style-Adaptive Detection Transformer (SA-DETR) for SDG in object detection. Specifically, we present a domain style adapter that projects the style representation of the unseen target domain into the training domain, enabling dynamic style adaptation. Then, we propose an object-aware contrastive learning module to guide the detector in extracting domain-invariant features through contrastive learning. By using object-aware gating masks to constrain feature aggregation in both spatial and semantic dimensions, this module achieves cross-domain contrast of instance-level features, thereby enhancing generalization. Extensive experiments demonstrate the superior performance and generalization capability of SA-DETR across five different weather scenarios. Code is released at https://github.com/h751410234/SA-DETR.
Decoupled Global-Local Alignment for Improving Compositional Understanding
Apr 23, 2025Contrastive Language-Image Pre-training (CLIP) has achieved success on multiple downstream tasks by aligning image and text modalities. However, the nature of global contrastive learning limits CLIP's ability to comprehend compositional concepts, such as relations and attributes. Although recent studies employ global hard negative samples to improve compositional understanding, these methods significantly compromise the model's inherent general capabilities by forcibly distancing textual negative samples from images in the embedding space. To overcome this limitation, we introduce a Decoupled Global-Local Alignment (DeGLA) framework that improves compositional understanding while substantially mitigating losses in general capabilities. To optimize the retention of the model's inherent capabilities, we incorporate a self-distillation mechanism within the global alignment process, aligning the learnable image-text encoder with a frozen teacher model derived from an exponential moving average. Under the constraint of self-distillation, it effectively mitigates the catastrophic forgetting of pretrained knowledge during fine-tuning. To improve compositional understanding, we first leverage the in-context learning capability of Large Language Models (LLMs) to construct about 2M high-quality negative captions across five types. Subsequently, we propose the Image-Grounded Contrast (IGC) loss and Text-Grounded Contrast (TGC) loss to enhance vision-language compositionally. Extensive experimental results demonstrate the effectiveness of the DeGLA framework. Compared to previous state-of-the-art methods, DeGLA achieves an average enhancement of 3.5% across the VALSE, SugarCrepe, and ARO benchmarks. Concurrently, it obtains an average performance improvement of 13.0% on zero-shot classification tasks across eleven datasets. Our code will be released at https://github.com/xiaoxing2001/DeGLA
Earth-Adapter: Bridge the Geospatial Domain Gaps with Mixture of Frequency Adaptation
Apr 09, 2025



Parameter-Efficient Fine-Tuning (PEFT) is a technique that allows us to adapt powerful Foundation Models (FMs) to diverse downstream tasks while preserving and unleashing their inherent capabilities. However, we have observed that existing PEFT methods, which are often designed with natural imagery in mind, struggle when applied to Remote Sensing (RS) scenarios. This is primarily due to their inability to handle artifact influences, a problem particularly severe in RS image features. To tackle this challenge, we introduce Earth-Adapter, the first PEFT method specifically designed for RS artifacts conquering. Earth-Adapter introduces a novel Mixture of Frequency Adaptation process that combines a Mixture of Adapter (MoA) with Discrete Fourier Transformation (DFT). By utilizing DFT, Earth-Adapter can decompose features into different frequency components, precisely separating artifacts from original features. The MoA then dynamically assigns weights to each adapter expert, allowing for the combination of features across various frequency domains. These simple-yet-effective approaches enable Earth-Adapter to more efficiently overcome the disturbances caused by artifacts than previous PEFT methods, significantly enhancing the FMs' performance on RS scenarios. Experiments on Domain Adaptation (DA), and Domain Generalization (DG) semantic segmentation benchmarks showcase the Earth-Adapter's effectiveness. Compared with baseline Rein, Earth-Adapter significantly improves 9.0% mIoU in DA and 3.1% mIoU in DG benchmarks. Our code will be released at https://github.com/VisionXLab/Earth-Adapter.
Beyond Agreement: Diagnosing the Rationale Alignment of Automated Essay Scoring Methods based on Linguistically-informed Counterfactuals
May 29, 2024



While current automated essay scoring (AES) methods show high agreement with human raters, their scoring mechanisms are not fully explored. Our proposed method, using counterfactual intervention assisted by Large Language Models (LLMs), reveals that when scoring essays, BERT-like models primarily focus on sentence-level features, while LLMs are attuned to conventions, language complexity, as well as organization, indicating a more comprehensive alignment with scoring rubrics. Moreover, LLMs can discern counterfactual interventions during feedback. Our approach improves understanding of neural AES methods and can also apply to other domains seeking transparency in model-driven decisions. The codes and data will be released at GitHub.
DATR: Unsupervised Domain Adaptive Detection Transformer with Dataset-Level Adaptation and Prototypical Alignment
May 20, 2024



Object detectors frequently encounter significant performance degradation when confronted with domain gaps between collected data (source domain) and data from real-world applications (target domain). To address this task, numerous unsupervised domain adaptive detectors have been proposed, leveraging carefully designed feature alignment techniques. However, these techniques primarily align instance-level features in a class-agnostic manner, overlooking the differences between extracted features from different categories, which results in only limited improvement. Furthermore, the scope of current alignment modules is often restricted to a limited batch of images, failing to learn the entire dataset-level cues, thereby severely constraining the detector's generalization ability to the target domain. To this end, we introduce a strong DETR-based detector named Domain Adaptive detection TRansformer (DATR) for unsupervised domain adaptation of object detection. Firstly, we propose the Class-wise Prototypes Alignment (CPA) module, which effectively aligns cross-domain features in a class-aware manner by bridging the gap between object detection task and domain adaptation task. Then, the designed Dataset-level Alignment Scheme (DAS) explicitly guides the detector to achieve global representation and enhance inter-class distinguishability of instance-level features across the entire dataset, which spans both domains, by leveraging contrastive learning. Moreover, DATR incorporates a mean-teacher based self-training framework, utilizing pseudo-labels generated by the teacher model to further mitigate domain bias. Extensive experimental results demonstrate superior performance and generalization capabilities of our proposed DATR in multiple domain adaptation scenarios. Code is released at https://github.com/h751410234/DATR.
MS-Net: A Multi-modal Self-supervised Network for Fine-Grained Classification of Aircraft in SAR Images
Aug 28, 2023



Synthetic aperture radar (SAR) imaging technology is commonly used to provide 24-hour all-weather earth observation. However, it still has some drawbacks in SAR target classification, especially in fine-grained classification of aircraft: aircrafts in SAR images have large intra-class diversity and inter-class similarity; the number of effective samples is insufficient and it's hard to annotate. To address these issues, this article proposes a novel multi-modal self-supervised network (MS-Net) for fine-grained classification of aircraft. Firstly, in order to entirely exploit the potential of multi-modal information, a two-sided path feature extraction network (TSFE-N) is constructed to enhance the image feature of the target and obtain the domain knowledge feature of text mode. Secondly, a contrastive self-supervised learning (CSSL) framework is employed to effectively learn useful label-independent feature from unbalanced data, a similarity per-ception loss (SPloss) is proposed to avoid network overfitting. Finally, TSFE-N is used as the encoder of CSSL to obtain the classification results. Through a large number of experiments, our MS-Net can effectively reduce the difficulty of classifying similar types of aircrafts. In the case of no label, the proposed algorithm achieves an accuracy of 88.46% for 17 types of air-craft classification task, which has pioneering significance in the field of fine-grained classification of aircraft in SAR images.
SSAP: Single-Shot Instance Segmentation With Affinity Pyramid
Sep 04, 2019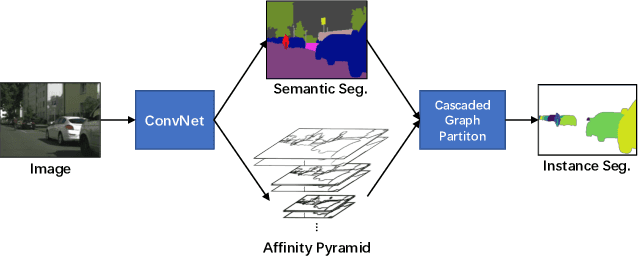
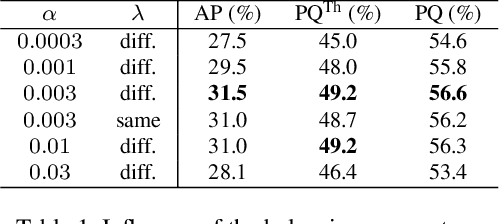
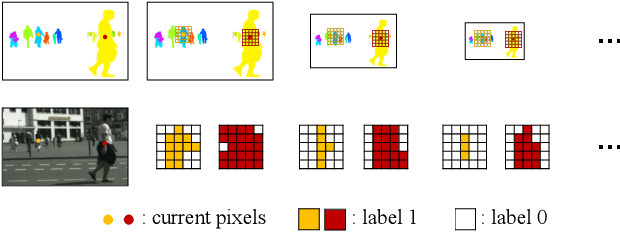
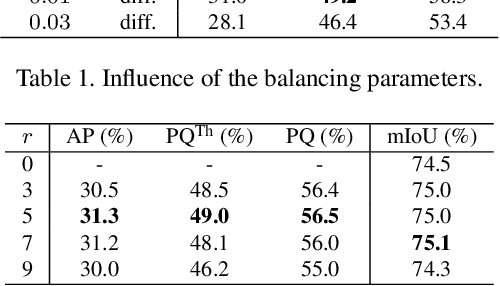
Recently, proposal-free instance segmentation has received increasing attention due to its concise and efficient pipeline. Generally, proposal-free methods generate instance-agnostic semantic segmentation labels and instance-aware features to group pixels into different object instances. However, previous methods mostly employ separate modules for these two sub-tasks and require multiple passes for inference. We argue that treating these two sub-tasks separately is suboptimal. In fact, employing multiple separate modules significantly reduces the potential for application. The mutual benefits between the two complementary sub-tasks are also unexplored. To this end, this work proposes a single-shot proposal-free instance segmentation method that requires only one single pass for prediction. Our method is based on a pixel-pair affinity pyramid, which computes the probability that two pixels belong to the same instance in a hierarchical manner. The affinity pyramid can also be jointly learned with the semantic class labeling and achieve mutual benefits. Moreover, incorporating with the learned affinity pyramid, a novel cascaded graph partition module is presented to sequentially generate instances from coarse to fine. Unlike previous time-consuming graph partition methods, this module achieves $5\times$ speedup and 9% relative improvement on Average-Precision (AP). Our approach achieves state-of-the-art results on the challenging Cityscapes dataset.
Deep Crisp Boundaries: From Boundaries to Higher-level Tasks
Oct 09, 2018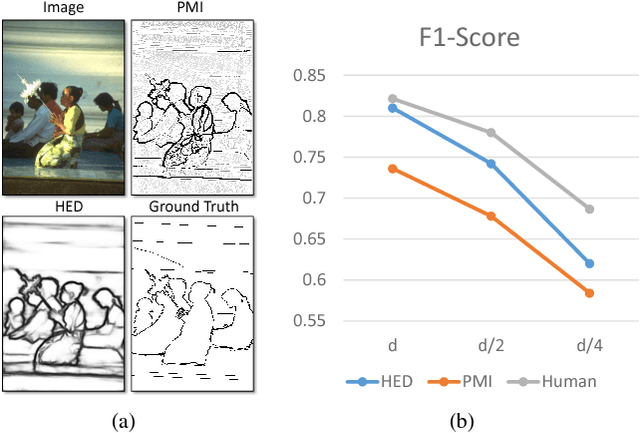

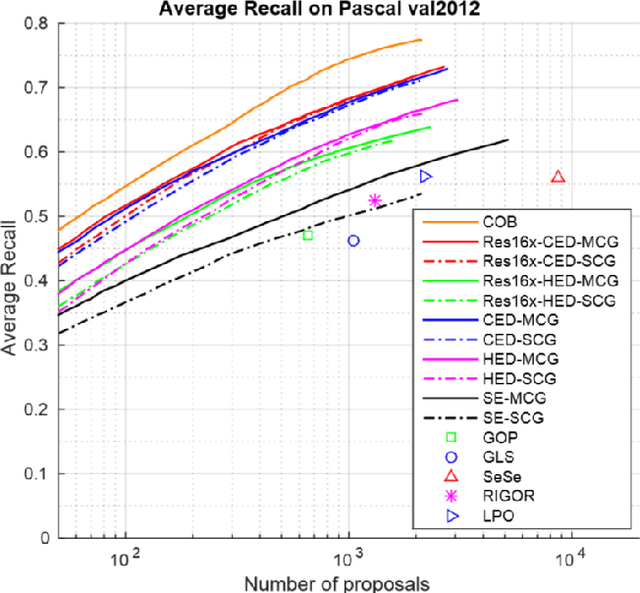
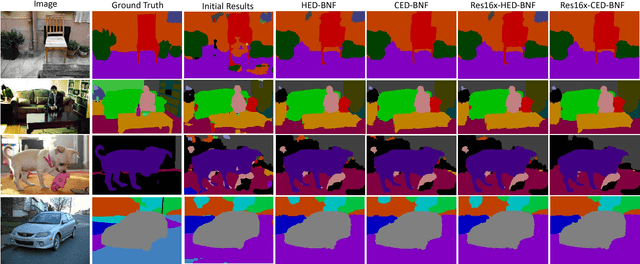
Edge detection has made significant progress with the help of deep Convolutional Networks (ConvNet). These ConvNet based edge detectors have approached human level performance on standard benchmarks. We provide a systematical study of these detectors' outputs. We show that the detection results did not accurately localize edge pixels, which can be adversarial for tasks that require crisp edge inputs. As a remedy, we propose a novel refinement architecture to address the challenging problem of learning a crisp edge detector using ConvNet. Our method leverages a top-down backward refinement pathway, and progressively increases the resolution of feature maps to generate crisp edges. Our results achieve superior performance, surpassing human accuracy when using standard criteria on BSDS500, and largely outperforming state-of-the-art methods when using more strict criteria. More importantly, we demonstrate the benefit of crisp edge maps for several important applications in computer vision, including optical flow estimation, object proposal generation and semantic segmentation.