 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedunCut: Measurement-Driven Sampling and Accuracy Performance Modeling for Low-Cost Live Video Analytics
Dec 30, 2025Live video analytics (LVA) runs continuously across massive camera fleets, but inference cost with modern vision models remains high. To address this, dynamic model size selection (DMSS) is an attractive approach: it is content-aware but treats models as black boxes, and could potentially reduce cost by up to 10x without model retraining or modification. Without ground truth labels at runtime, we observe that DMSS methods use two stages per segment: (i) sampling a few models to calculate prediction statistics (e.g., confidences), then (ii) selection of the model size from those statistics. Prior systems fail to generalize to diverse workloads, particularly to mobile videos and lower accuracy targets. We identify that the failure modes stem from inefficient sampling whose cost exceeds its benefit, and inaccurate per-segment accuracy prediction. In this work, we present RedunCut, a new DMSS system that addresses both: It uses a measurement-driven planner that estimates the cost-benefit tradeoff of sampling, and a lightweight, data-driven performance model to improve accuracy prediction. Across road-vehicle, drone, and surveillance videos and multiple model families and tasks, RedunCut reduces compute cost by 14-62% at fixed accuracy and remains robust to limited historical data and to drift.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022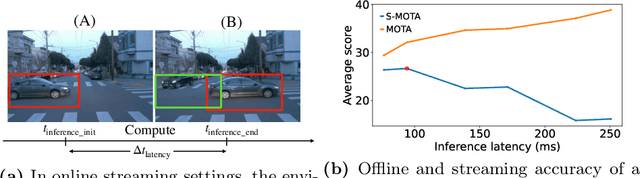
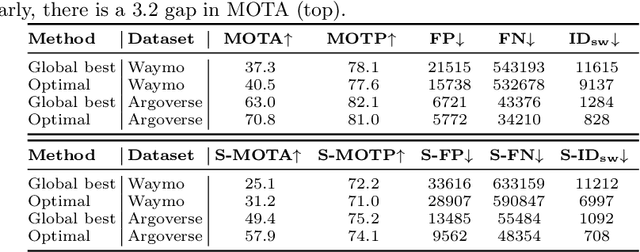
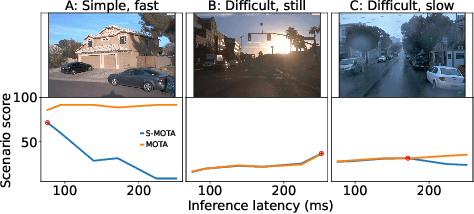
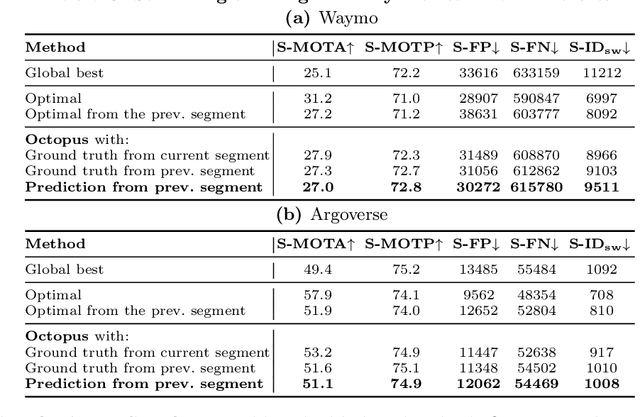
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Online Learning Demands in Max-min Fairness
Dec 15, 2020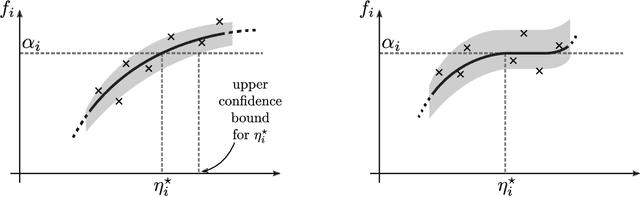

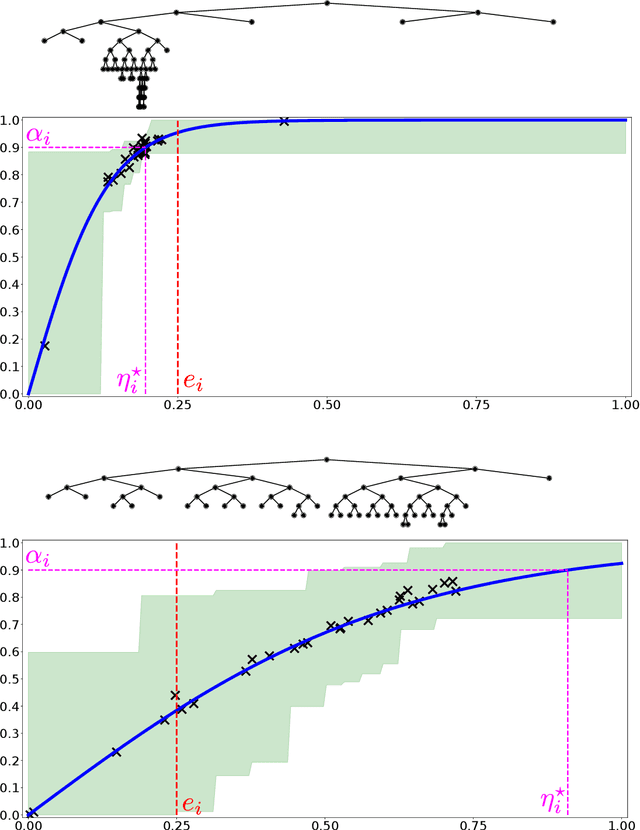
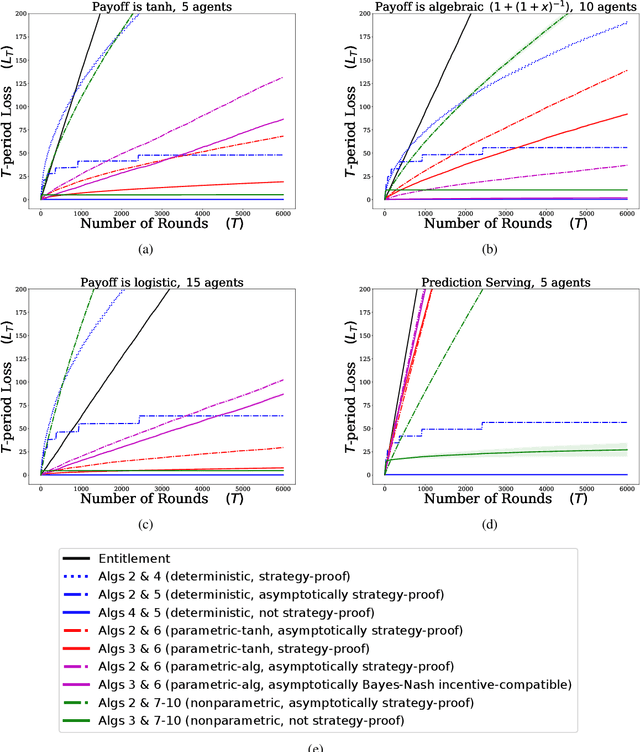
We describe mechanisms for the allocation of a scarce resource among multiple users in a way that is efficient, fair, and strategy-proof, but when users do not know their resource requirements. The mechanism is repeated for multiple rounds and a user's requirements can change on each round. At the end of each round, users provide feedback about the allocation they received, enabling the mechanism to learn user preferences over time. Such situations are common in the shared usage of a compute cluster among many users in an organisation, where all teams may not precisely know the amount of resources needed to execute their jobs. By understating their requirements, users will receive less than they need and consequently not achieve their goals. By overstating them, they may siphon away precious resources that could be useful to others in the organisation. We formalise this task of online learning in fair division via notions of efficiency, fairness, and strategy-proofness applicable to this setting, and study this problem under three types of feedback: when the users' observations are deterministic, when they are stochastic and follow a parametric model, and when they are stochastic and nonparametric. We derive mechanisms inspired by the classical max-min fairness procedure that achieve these requisites, and quantify the extent to which they are achieved via asymptotic rates. We corroborate these insights with an experimental evaluation on synthetic problems and a web-serving task.