 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedunCut: Measurement-Driven Sampling and Accuracy Performance Modeling for Low-Cost Live Video Analytics
Dec 30, 2025Live video analytics (LVA) runs continuously across massive camera fleets, but inference cost with modern vision models remains high. To address this, dynamic model size selection (DMSS) is an attractive approach: it is content-aware but treats models as black boxes, and could potentially reduce cost by up to 10x without model retraining or modification. Without ground truth labels at runtime, we observe that DMSS methods use two stages per segment: (i) sampling a few models to calculate prediction statistics (e.g., confidences), then (ii) selection of the model size from those statistics. Prior systems fail to generalize to diverse workloads, particularly to mobile videos and lower accuracy targets. We identify that the failure modes stem from inefficient sampling whose cost exceeds its benefit, and inaccurate per-segment accuracy prediction. In this work, we present RedunCut, a new DMSS system that addresses both: It uses a measurement-driven planner that estimates the cost-benefit tradeoff of sampling, and a lightweight, data-driven performance model to improve accuracy prediction. Across road-vehicle, drone, and surveillance videos and multiple model families and tasks, RedunCut reduces compute cost by 14-62% at fixed accuracy and remains robust to limited historical data and to drift.
SpiderGen: Towards Procedure Generation For Carbon Life Cycle Assessments with Generative AI
Nov 18, 2025Investigating the effects of climate change and global warming caused by GHG emissions have been a key concern worldwide. These emissions are largely contributed to by the production, use and disposal of consumer products. Thus, it is important to build tools to estimate the environmental impact of consumer goods, an essential part of which is conducting Life Cycle Assessments (LCAs). LCAs specify and account for the appropriate processes involved with the production, use, and disposal of the products. We present SpiderGen, an LLM-based workflow which integrates the taxonomy and methodology of traditional LCA with the reasoning capabilities and world knowledge of LLMs to generate graphical representations of the key procedural information used for LCA, known as Product Category Rules Process Flow Graphs (PCR PFGs). We additionally evaluate the output of SpiderGen by comparing it with 65 real-world LCA documents. We find that SpiderGen provides accurate LCA process information that is either fully correct or has minor errors, achieving an F1-Score of 65% across 10 sample data points, as compared to 53% using a one-shot prompting method. We observe that the remaining errors occur primarily due to differences in detail between LCA documents, as well as differences in the "scope" of which auxiliary processes must also be included. We also demonstrate that SpiderGen performs better than several baselines techniques, such as chain-of-thought prompting and one-shot prompting. Finally, we highlight SpiderGen's potential to reduce the human effort and costs for estimating carbon impact, as it is able to produce LCA process information for less than \$1 USD in under 10 minutes as compared to the status quo LCA, which can cost over \$25000 USD and take up to 21-person days.
FUELVISION: A Multimodal Data Fusion and Multimodel Ensemble Algorithm for Wildfire Fuels Mapping
Mar 19, 2024Accurate assessment of fuel conditions is a prerequisite for fire ignition and behavior prediction, and risk management. The method proposed herein leverages diverse data sources including Landsat-8 optical imagery, Sentinel-1 (C-band) Synthetic Aperture Radar (SAR) imagery, PALSAR (L-band) SAR imagery, and terrain features to capture comprehensive information about fuel types and distributions. An ensemble model was trained to predict landscape-scale fuels such as the 'Scott and Burgan 40' using the as-received Forest Inventory and Analysis (FIA) field survey plot data obtained from the USDA Forest Service. However, this basic approach yielded relatively poor results due to the inadequate amount of training data. Pseudo-labeled and fully synthetic datasets were developed using generative AI approaches to address the limitations of ground truth data availability. These synthetic datasets were used for augmenting the FIA data from California to enhance the robustness and coverage of model training. The use of an ensemble of methods including deep learning neural networks, decision trees, and gradient boosting offered a fuel mapping accuracy of nearly 80\%. Through extensive experimentation and evaluation, the effectiveness of the proposed approach was validated for regions of the 2021 Dixie and Caldor fires. Comparative analyses against high-resolution data from the National Agriculture Imagery Program (NAIP) and timber harvest maps affirmed the robustness and reliability of the proposed approach, which is capable of near-real-time fuel mapping.
OptiState: State Estimation of Legged Robots using Gated Networks with Transformer-based Vision and Kalman Filtering
Jan 31, 2024State estimation for legged robots is challenging due to their highly dynamic motion and limitations imposed by sensor accuracy. By integrating Kalman filtering, optimization, and learning-based modalities, we propose a hybrid solution that combines proprioception and exteroceptive information for estimating the state of the robot's trunk. Leveraging joint encoder and IMU measurements, our Kalman filter is enhanced through a single-rigid body model that incorporates ground reaction force control outputs from convex Model Predictive Control optimization. The estimation is further refined through Gated Recurrent Units, which also considers semantic insights and robot height from a Vision Transformer autoencoder applied on depth images. This framework not only furnishes accurate robot state estimates, including uncertainty evaluations, but can minimize the nonlinear errors that arise from sensor measurements and model simplifications through learning. The proposed methodology is evaluated in hardware using a quadruped robot on various terrains, yielding a 65% improvement on the Root Mean Squared Error compared to our VIO SLAM baseline. Code example: https://github.com/AlexS28/OptiState
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023



Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.
B2RL: An open-source Dataset for Building Batch Reinforcement Learning
Sep 30, 2022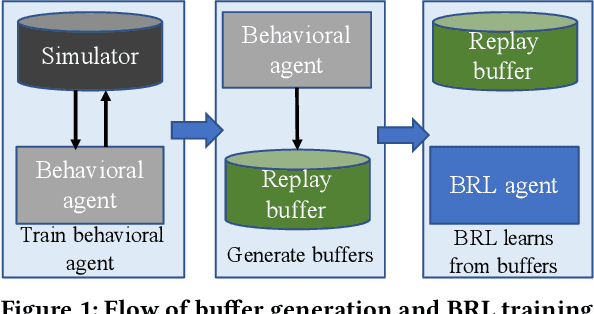
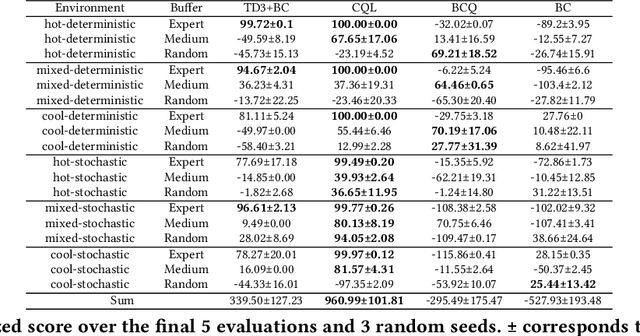
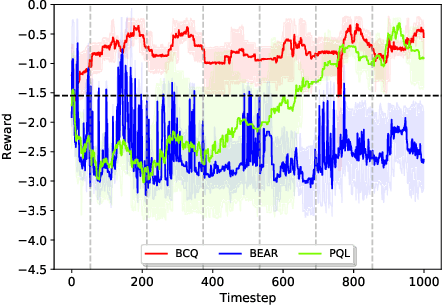
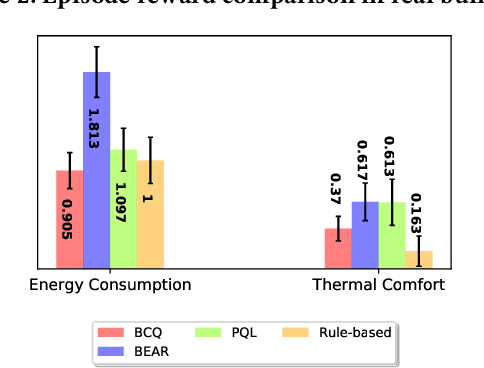
Batch reinforcement learning (BRL) is an emerging research area in the RL community. It learns exclusively from static datasets (i.e. replay buffers) without interaction with the environment. In the offline settings, existing replay experiences are used as prior knowledge for BRL models to find the optimal policy. Thus, generating replay buffers is crucial for BRL model benchmark. In our B2RL (Building Batch RL) dataset, we collected real-world data from our building management systems, as well as buffers generated by several behavioral policies in simulation environments. We believe it could help building experts on BRL research. To the best of our knowledge, we are the first to open-source building datasets for the purpose of BRL learning.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022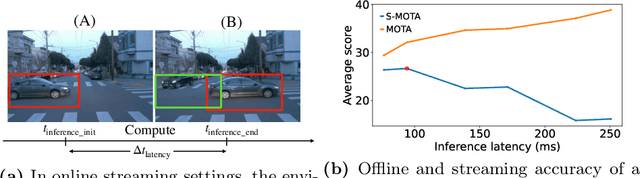
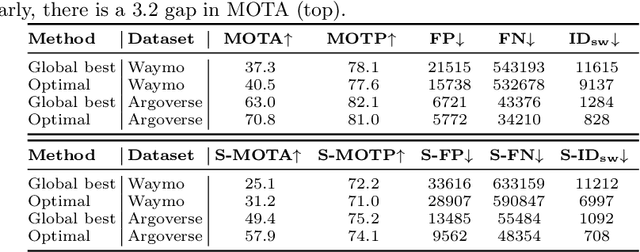
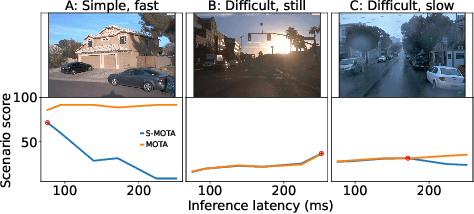
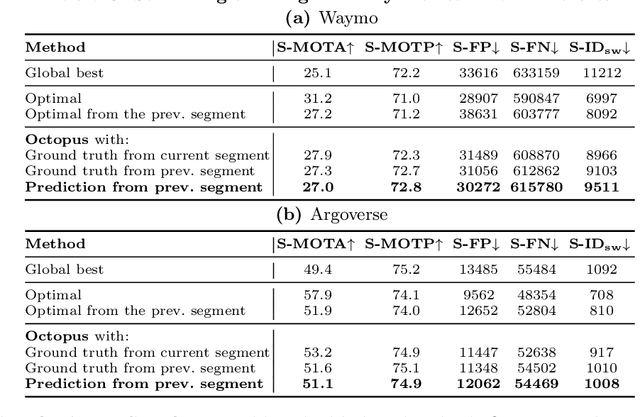
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Quick Question: Interrupting Users for Microtasks with Reinforcement Learning
Jul 18, 2020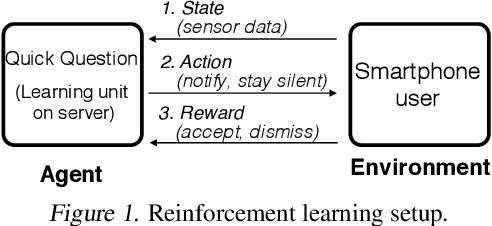
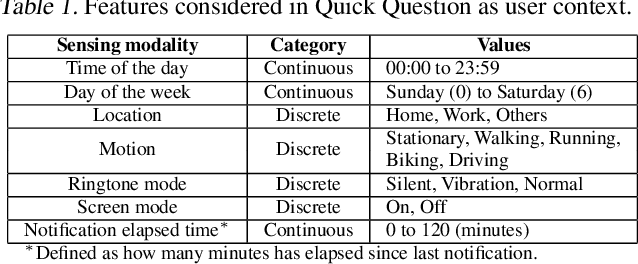
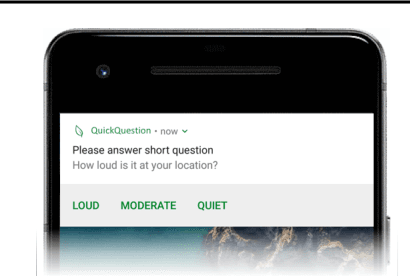

Human attention is a scarce resource in modern computing. A multitude of microtasks vie for user attention to crowdsource information, perform momentary assessments, personalize services, and execute actions with a single touch. A lot gets done when these tasks take up the invisible free moments of the day. However, an interruption at an inappropriate time degrades productivity and causes annoyance. Prior works have exploited contextual cues and behavioral data to identify interruptibility for microtasks with much success. With Quick Question, we explore use of reinforcement learning (RL) to schedule microtasks while minimizing user annoyance and compare its performance with supervised learning. We model the problem as a Markov decision process and use Advantage Actor Critic algorithm to identify interruptible moments based on context and history of user interactions. In our 5-week, 30-participant study, we compare the proposed RL algorithm against supervised learning methods. While the mean number of responses between both methods is commensurate, RL is more effective at avoiding dismissal of notifications and improves user experience over time.
ORL: Reinforcement Learning Benchmarks for Online Stochastic Optimization Problems
Dec 01, 2019
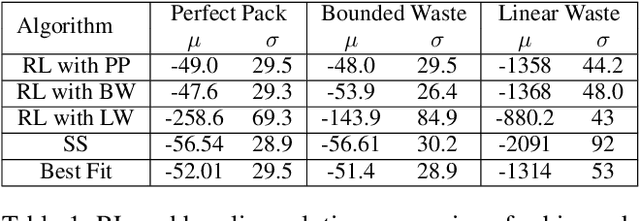
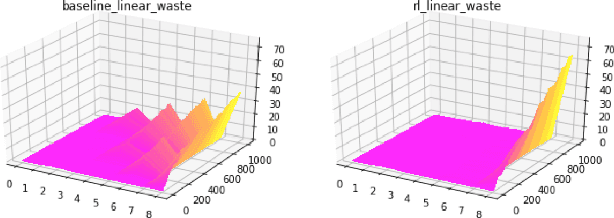
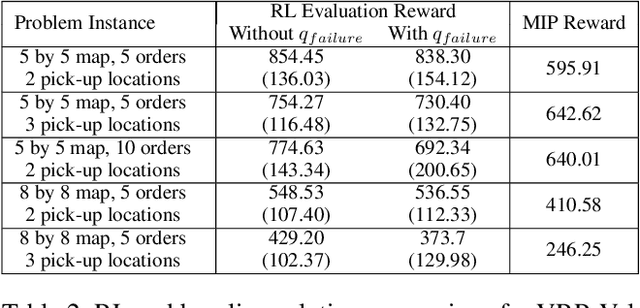
Reinforcement Learning (RL) has achieved state-of-the-art results in domains such as robotics and games. We build on this previous work by applying RL algorithms to a selection of canonical online stochastic optimization problems with a range of practical applications: Bin Packing, Newsvendor, and Vehicle Routing. While there is a nascent literature that applies RL to these problems, there are no commonly accepted benchmarks which can be used to compare proposed approaches rigorously in terms of performance, scale, or generalizability. This paper aims to fill that gap. For each problem we apply both standard approaches as well as newer RL algorithms and analyze results. In each case, the performance of the trained RL policy is competitive with or superior to the corresponding baselines, while not requiring much in the way of domain knowledge. This highlights the potential of RL in real-world dynamic resource allocation problems.
DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning
Nov 05, 2019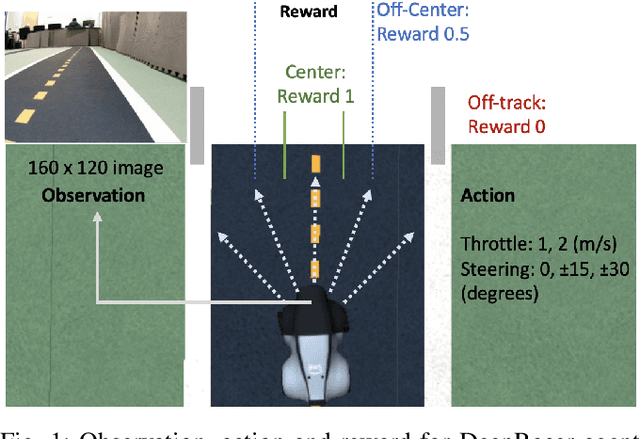



DeepRacer is a platform for end-to-end experimentation with RL and can be used to systematically investigate the key challenges in developing intelligent control systems. Using the platform, we demonstrate how a 1/18th scale car can learn to drive autonomously using RL with a monocular camera. It is trained in simulation with no additional tuning in physical world and demonstrates: 1) formulation and solution of a robust reinforcement learning algorithm, 2) narrowing the reality gap through joint perception and dynamics, 3) distributed on-demand compute architecture for training optimal policies, and 4) a robust evaluation method to identify when to stop training. It is the first successful large-scale deployment of deep reinforcement learning on a robotic control agent that uses only raw camera images as observations and a model-free learning method to perform robust path planning. We open source our code and video demo on GitHub: https://git.io/fjxoJ.