 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!
Feb 11, 2025Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-of-thoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training techniques and data requirements to elicit Long CoT remain poorly understood. In this work, we find that a Large Language model (LLM) can effectively learn Long CoT reasoning through data-efficient supervised fine-tuning (SFT) and parameter-efficient low-rank adaptation (LoRA). With just 17k long CoT training samples, the Qwen2.5-32B-Instruct model achieves significant improvements on a wide range of math and coding benchmarks, including 56.7% (+40.0%) on AIME 2024 and 57.0% (+8.1%) on LiveCodeBench, competitive to the proprietary o1-preview model's score of 44.6% and 59.1%. More importantly, we find that the structure of Long CoT is critical to the learning process, whereas the content of individual reasoning steps has minimal impact. Perturbations affecting content, such as training on incorrect samples or removing reasoning keywords, have little impact on performance. In contrast, structural modifications that disrupt logical consistency in the Long CoT, such as shuffling or deleting reasoning steps, significantly degrade accuracy. For example, a model trained on Long CoT samples with incorrect answers still achieves only 3.2% lower accuracy compared to training with fully correct samples. These insights deepen our understanding of how to elicit reasoning capabilities in LLMs and highlight key considerations for efficiently training the next generation of reasoning models. This is the academic paper of our previous released Sky-T1-32B-Preview model. Codes are available at https://github.com/NovaSky-AI/SkyThought.
Pie: Pooling CPU Memory for LLM Inference
Nov 14, 2024



The rapid growth of LLMs has revolutionized natural language processing and AI analysis, but their increasing size and memory demands present significant challenges. A common solution is to spill over to CPU memory; however, traditional GPU-CPU memory swapping often results in higher latency and lower throughput. This paper introduces Pie, an LLM inference framework that addresses these challenges with performance-transparent swapping and adaptive expansion. By leveraging predictable memory access patterns and the high bandwidth of modern hardware like the NVIDIA GH200 Grace Hopper Superchip, Pie enables concurrent data swapping without affecting foreground computation, expanding effective memory without added latency. Adaptive expansion dynamically adjusts CPU memory allocation based on real-time information, optimizing memory usage and performance under varying conditions. Pie maintains low computation latency, high throughput, and high elasticity. Our experimental evaluation demonstrates that Pie achieves optimal swapping policy during cache warmup and effectively balances increased memory capacity with negligible impact on computation. With its extended capacity, Pie outperforms vLLM by up to 1.9X in throughput and 2X in latency. Additionally, Pie can reduce GPU memory usage by up to 1.67X while maintaining the same performance. Compared to FlexGen, an offline profiling-based swapping solution, Pie achieves magnitudes lower latency and 9.4X higher throughput.
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Jun 20, 2024



Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Optimizing LLM Queries in Relational Workloads
Mar 09, 2024



Analytical database providers (e.g., Redshift, Databricks, BigQuery) have rapidly added support for invoking Large Language Models (LLMs) through native user-defined functions (UDFs) to help users perform natural language tasks, such as classification, entity extraction, and translation, inside analytical workloads. For instance, an analyst might want to extract customer sentiments on millions of product reviews. However, LLM inference is highly expensive in both computational and economic terms: for example, an NVIDIA L4 GPU running Llama2-7B can only process 6 KB of text per second. In this paper, we explore how to optimize LLM inference for analytical workloads that invoke LLMs within relational queries. We show that relational queries present novel opportunities for accelerating LLM inference, including reordering rows to maximize key-value (KV) cache reuse within the LLM inference engine, reordering columns within a row to further increase cache reuse, and deduplicating redundant inference requests. We implement these optimizations in Apache Spark, with vLLM as the model serving backend and achieve up to 4.4x improvement in end-to-end latency on a benchmark of diverse LLM-based queries on real datasets. To the best of our knowledge, this is the first work to explicitly address the problem of optimizing LLM invocations within SQL queries.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022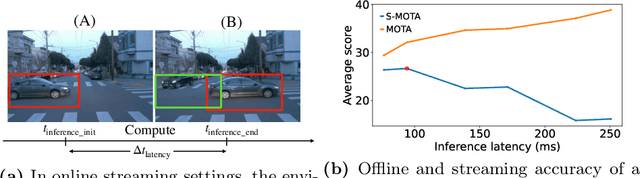
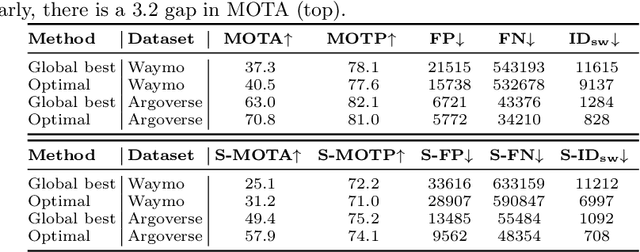
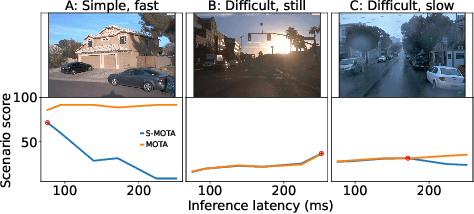
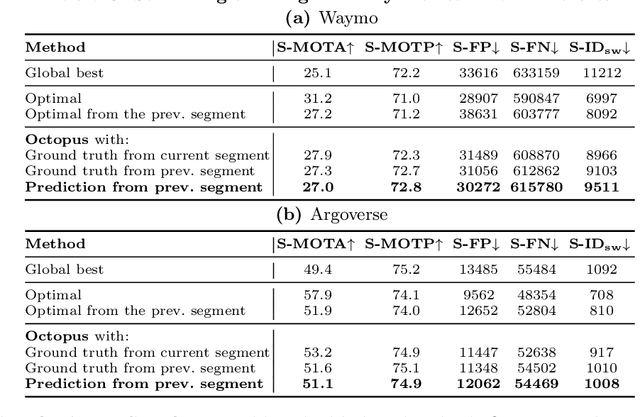
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Pay Attention to Convolution Filters: Towards Fast and Accurate Fine-Grained Transfer Learning
Jun 12, 2019
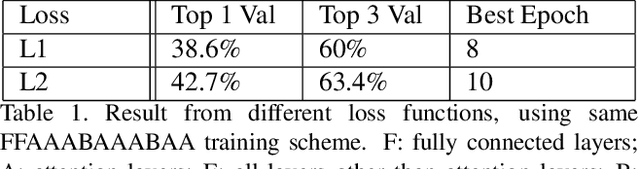
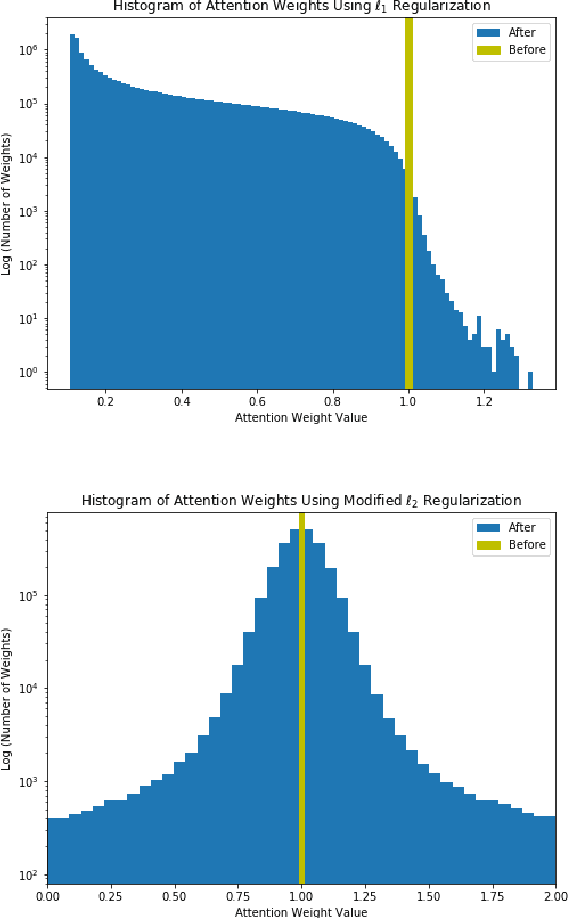
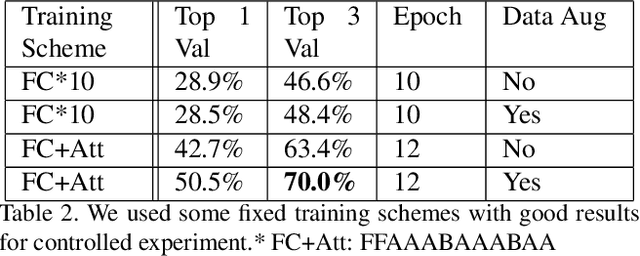
We propose an efficient transfer learning method for adapting ImageNet pre-trained Convolutional Neural Network (CNN) to fine-grained image classification task. Conventional transfer learning methods typically face the trade-off between training time and accuracy. By adding "attention module" to each convolutional filters of the pre-trained network, we are able to rank and adjust the importance of each convolutional signal in an end-to-end pipeline. In this report, we show our method can adapt a pre-trianed ResNet50 for a fine-grained transfer learning task within few epochs and achieve accuracy above conventional transfer learning methods and close to models trained from scratch. Our model also offer interpretable result because the rank of the convolutional signal shows which convolution channels are utilized and amplified to achieve better classification result, as well as which signal should be treated as noise for the specific transfer learning task, which could be pruned to lower model size.
The OoO VLIW JIT Compiler for GPU Inference
Jan 31, 2019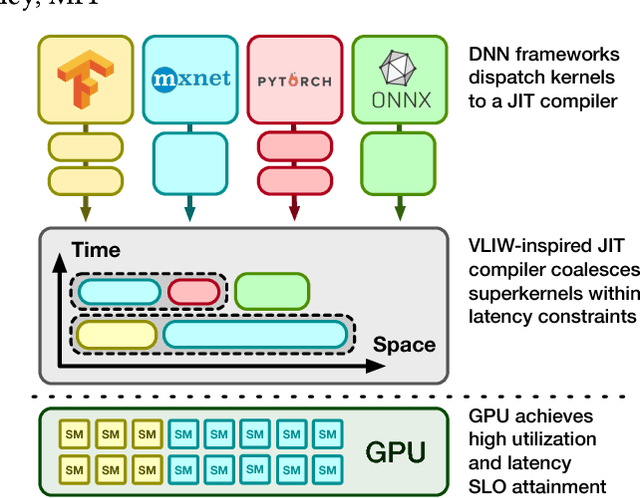

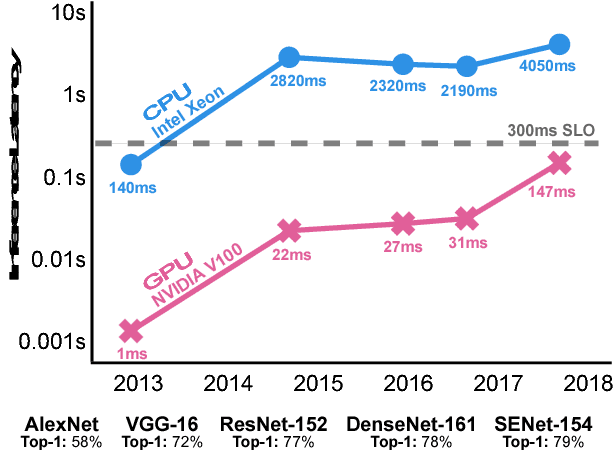
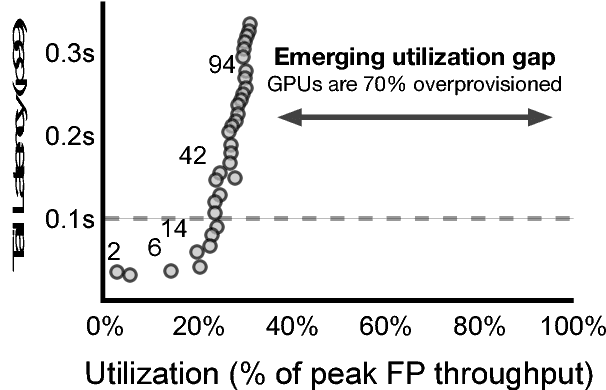
Current trends in Machine Learning~(ML) inference on hardware accelerated devices (e.g., GPUs, TPUs) point to alarmingly low utilization. As ML inference is increasingly time-bounded by tight latency SLOs, increasing data parallelism is not an option. The need for better efficiency motivates GPU multiplexing. Furthermore, existing GPU programming abstractions force programmers to micro-manage GPU resources in an early-binding, context-free fashion. We propose a VLIW-inspired Out-of-Order (OoO) Just-in-Time (JIT) compiler that coalesces and reorders execution kernels at runtime for throughput-optimal device utilization while satisfying latency SLOs. We quantify the inefficiencies of space-only and time-only multiplexing alternatives and demonstrate an achievable 7.7x opportunity gap through spatial coalescing.