 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Decomposition Representation for Reinforcement Learning
Aug 19, 2022
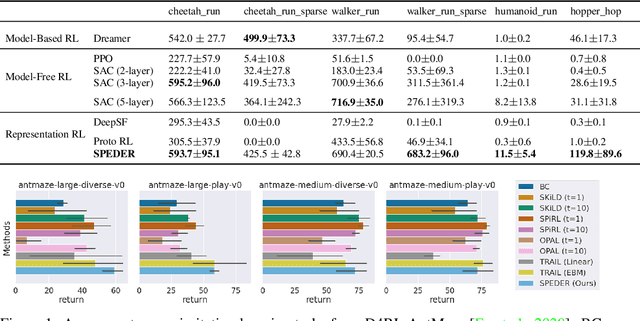
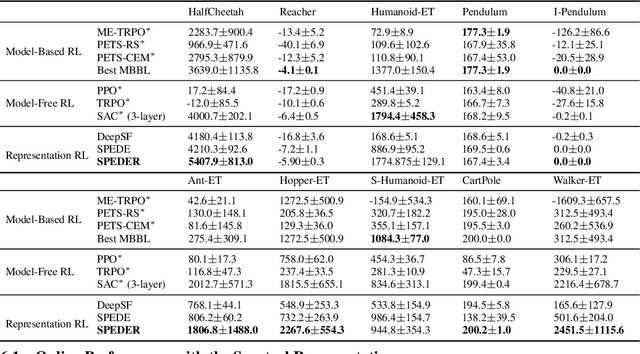

Representation learning often plays a critical role in reinforcement learning by managing the curse of dimensionality. A representative class of algorithms exploits a spectral decomposition of the stochastic transition dynamics to construct representations that enjoy strong theoretical properties in an idealized setting. However, current spectral methods suffer from limited applicability because they are constructed for state-only aggregation and derived from a policy-dependent transition kernel, without considering the issue of exploration. To address these issues, we propose an alternative spectral method, Spectral Decomposition Representation (SPEDER), that extracts a state-action abstraction from the dynamics without inducing spurious dependence on the data collection policy, while also balancing the exploration-versus-exploitation trade-off during learning. A theoretical analysis establishes the sample efficiency of the proposed algorithm in both the online and offline settings. In addition, an experimental investigation demonstrates superior performance over current state-of-the-art algorithms across several benchmarks.
Autonomously Untangling Long Cables
Jul 16, 2022


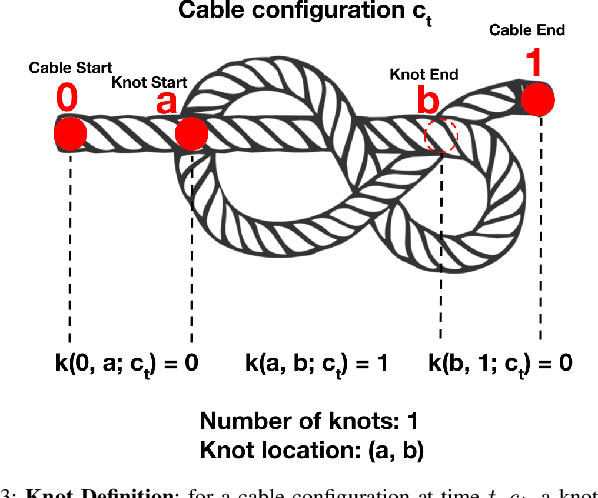
Cables are ubiquitous in many settings, but are prone to self-occlusions and knots, making them difficult to perceive and manipulate. The challenge often increases with cable length: long cables require more complex slack management and strategies to facilitate observability and reachability. In this paper, we focus on autonomously untangling cables up to 3 meters in length using a bilateral robot. We develop new motion primitives to efficiently untangle long cables and novel gripper jaws specialized for this task. We present Sliding and Grasping for Tangle Manipulation (SGTM), an algorithm that composes these primitives with RGBD vision to iteratively untangle. SGTM untangles cables with success rates of 67% on isolated overhand and figure eight knots and 50% on more complex configurations. Supplementary material, visualizations, and videos can be found at https://sites.google.com/view/rss-2022-untangling/home.
POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
Jul 15, 2022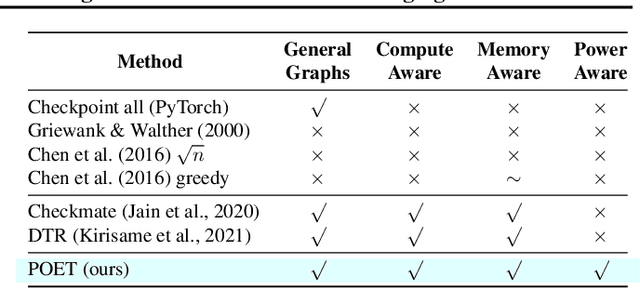
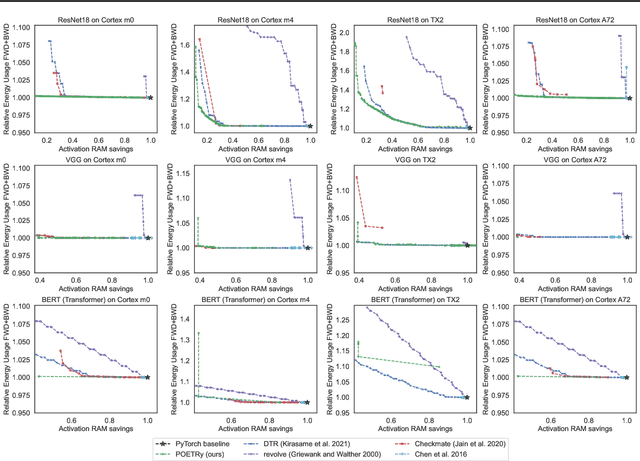
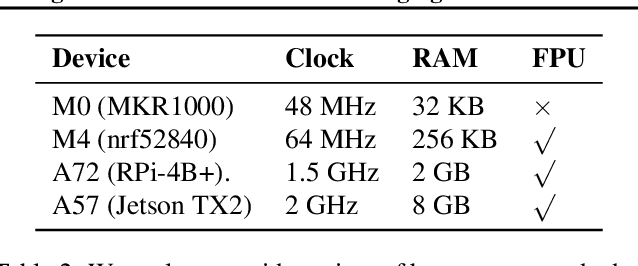
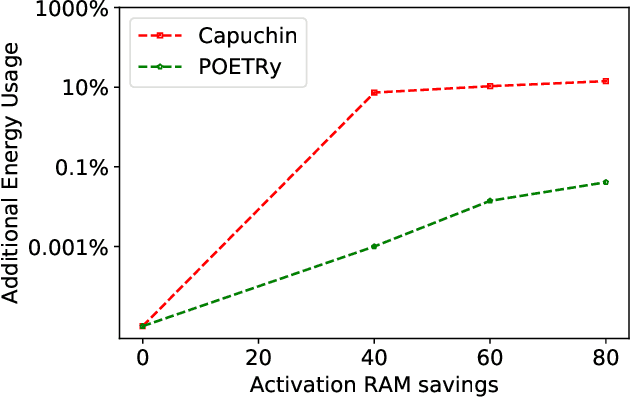
Fine-tuning models on edge devices like mobile phones would enable privacy-preserving personalization over sensitive data. However, edge training has historically been limited to relatively small models with simple architectures because training is both memory and energy intensive. We present POET, an algorithm to enable training large neural networks on memory-scarce battery-operated edge devices. POET jointly optimizes the integrated search search spaces of rematerialization and paging, two algorithms to reduce the memory consumption of backpropagation. Given a memory budget and a run-time constraint, we formulate a mixed-integer linear program (MILP) for energy-optimal training. Our approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both ResNet-18 and BERT within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency. POET is an open-source project available at https://github.com/ShishirPatil/poet
Making Linear MDPs Practical via Contrastive Representation Learning
Jul 14, 2022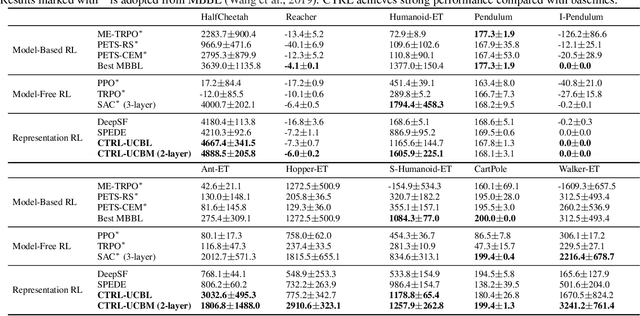
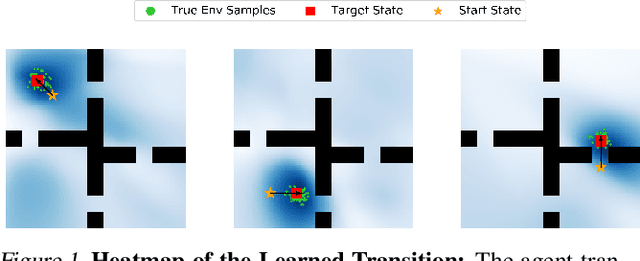


It is common to address the curse of dimensionality in Markov decision processes (MDPs) by exploiting low-rank representations. This motivates much of the recent theoretical study on linear MDPs. However, most approaches require a given representation under unrealistic assumptions about the normalization of the decomposition or introduce unresolved computational challenges in practice. Instead, we consider an alternative definition of linear MDPs that automatically ensures normalization while allowing efficient representation learning via contrastive estimation. The framework also admits confidence-adjusted index algorithms, enabling an efficient and principled approach to incorporating optimism or pessimism in the face of uncertainty. To the best of our knowledge, this provides the first practical representation learning method for linear MDPs that achieves both strong theoretical guarantees and empirical performance. Theoretically, we prove that the proposed algorithm is sample efficient in both the online and offline settings. Empirically, we demonstrate superior performance over existing state-of-the-art model-based and model-free algorithms on several benchmarks.
Neurotoxin: Durable Backdoors in Federated Learning
Jun 12, 2022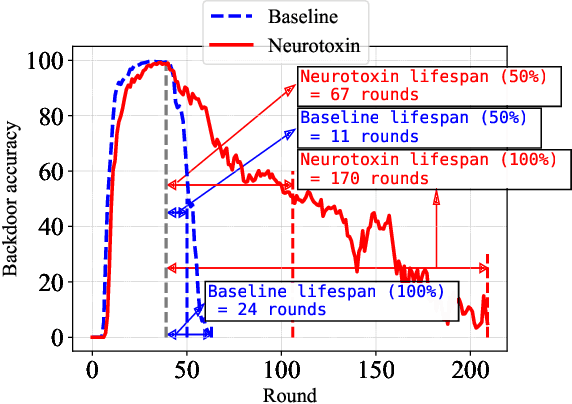

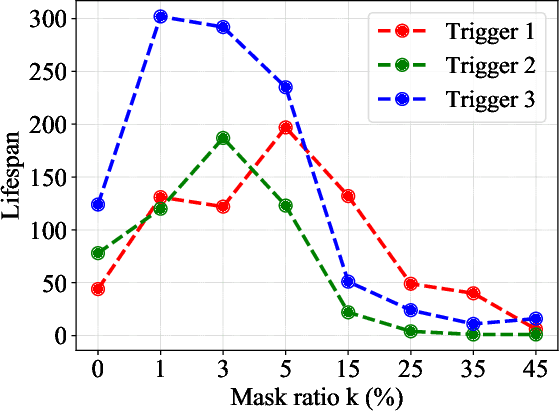
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.
All You Need is LUV: Unsupervised Collection of Labeled Images using Invisible UV Fluorescent Indicators
Mar 13, 2022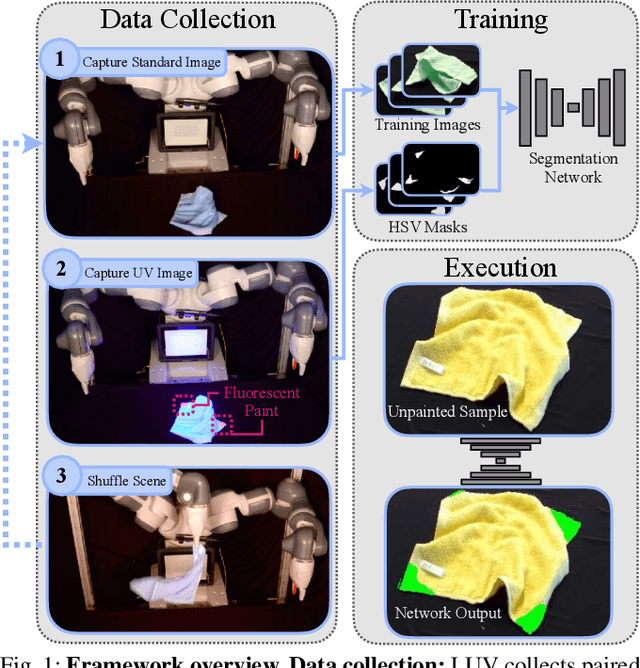



Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Current approaches often rely on human labelers, which can be expensive, or simulation data, which can visually or physically differ from real data. This paper proposes Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling. LUV uses transparent, ultraviolet-fluorescent paint with programmable ultraviolet LEDs to collect paired images of a scene in standard lighting and UV lighting to autonomously extract segmentation masks and keypoints via color segmentation. We apply LUV to a suite of diverse robot perception tasks to evaluate its labeling quality, flexibility, and data collection rate. Results suggest that LUV is 180-2500 times faster than a human labeler across the tasks. We show that LUV provides labels consistent with human annotations on unpainted test images. The networks trained on these labels are used to smooth and fold crumpled towels with 83% success rate and achieve 1.7mm position error with respect to human labels on a surgical needle pose estimation task. The low cost of LUV makes it ideal as a lightweight replacement for human labeling systems, with the one-time setup costs at $300 equivalent to the cost of collecting around 200 semantic segmentation labels on Amazon Mechanical Turk. Code, datasets, visualizations, and supplementary material can be found at https://sites.google.com/berkeley.edu/luv
Evaluating natural language processing models with generalization metrics that do not need access to any training or testing data
Feb 06, 2022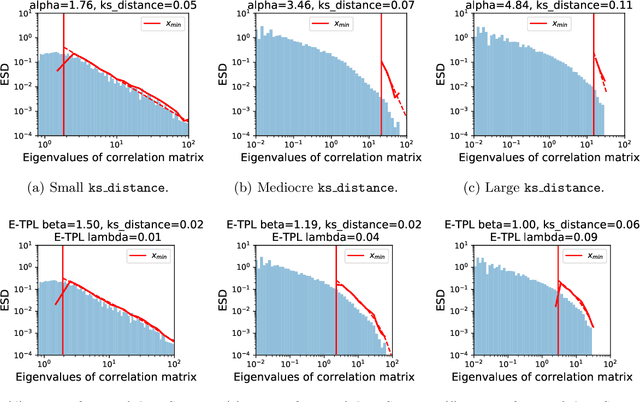
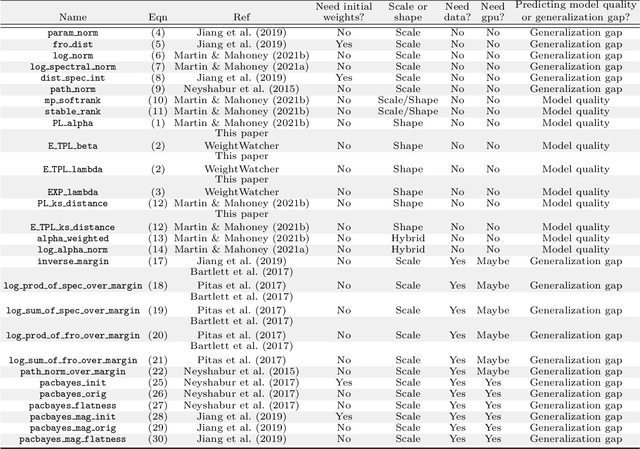
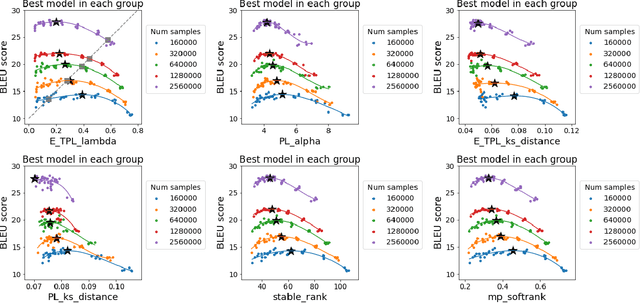

The search for effective and robust generalization metrics has been the focus of recent theoretical and empirical work. In this paper, we discuss the performance of natural language processing (NLP) models, and we evaluate various existing and novel generalization metrics. Compared to prior studies, we (i) focus on NLP instead of computer vision (CV), (ii) focus on generalization metrics that predict test error instead of the generalization gap, (iii) focus on generalization metrics that do not need the access to data, and (iv) focus on the heavy-tail (HT) phenomenon that has received comparatively less attention in the study of deep neural networks (NNs). We extend recent HT-based work which focuses on power law (PL) distributions, and we study exponential (EXP) and exponentially truncated power law (E-TPL) fitting to the empirical spectral densities (ESDs) of weight matrices. Our detailed empirical studies show that (i) \emph{shape metrics}, or the metrics obtained from fitting the shape of the ESDs, perform uniformly better at predicting generalization performance than \emph{scale metrics} commonly studied in the literature, as measured by the \emph{average} rank correlations with the generalization performance for all of our experiments; (ii) among forty generalization metrics studied in our paper, the \RANDDISTANCE metric, a new shape metric invented in this paper that measures the distance between empirical eigenvalues of weight matrices and those of randomly initialized weight matrices, achieves the highest worst-case rank correlation with generalization performance under a variety of training settings; and (iii) among the three HT distributions considered in our paper, the E-TPL fitting of ESDs performs the most robustly.
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
Jan 28, 2022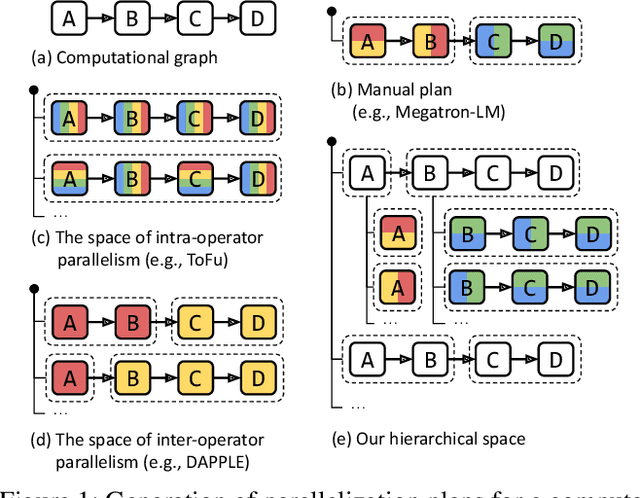
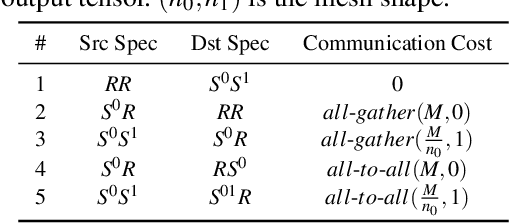

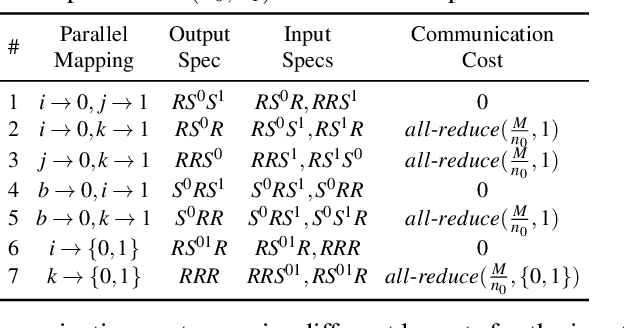
Alpa automates model-parallel training of large deep learning (DL) models by generating execution plans that unify data, operator, and pipeline parallelism. Existing model-parallel training systems either require users to manually create a parallelization plan or automatically generate one from a limited space of model parallelism configurations, which does not suffice to scale out complex DL models on distributed compute devices. Alpa distributes the training of large DL models by viewing parallelisms as two hierarchical levels: inter-operator and intra-operator parallelisms. Based on it, Alpa constructs a new hierarchical space for massive model-parallel execution plans. Alpa designs a number of compilation passes to automatically derive the optimal parallel execution plan in each independent parallelism level and implements an efficient runtime to orchestrate the two-level parallel execution on distributed compute devices. Our evaluation shows Alpa generates parallelization plans that match or outperform hand-tuned model-parallel training systems even on models they are designed for. Unlike specialized systems, Alpa also generalizes to models with heterogeneous architectures and models without manually-designed plans.
Representing Long-Range Context for Graph Neural Networks with Global Attention
Jan 21, 2022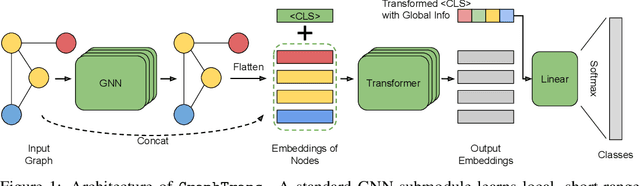
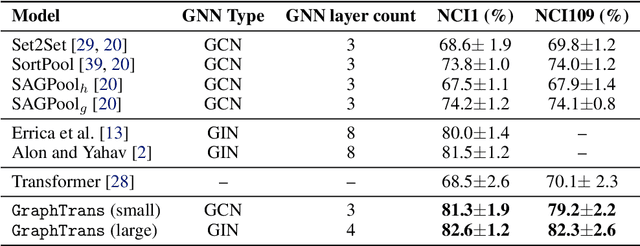
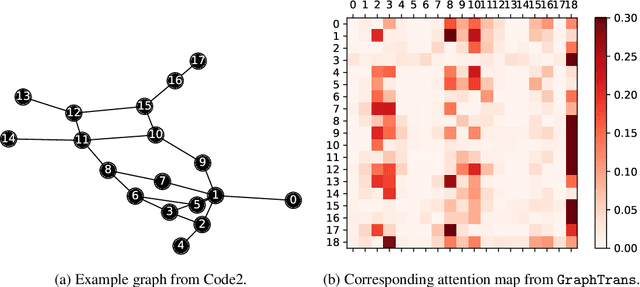
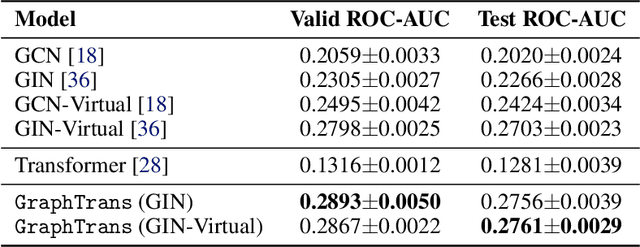
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel "readout" mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs. Code for GraphTrans is available at https://github.com/ucbrise/graphtrans.
Data Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
Dec 20, 2021



Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use InfoNCE loss to train a model to predict the pairing between images and text captions. CLIP, however, is data hungry and requires more than 400M image-text pairs for training. The inefficiency can be partially attributed to the fact that the image-text pairs are noisy. To address this, we propose OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition), which uses online entropic optimal transport to find a soft image-text match as labels for contrastive learning. Based on pretrained image and text encoders, models trained with OTTER achieve strong performance with only 3M image text pairs. Compared with InfoNCE loss, label smoothing, and knowledge distillation, OTTER consistently outperforms these baselines in zero shot evaluation on Google Open Images (19,958 classes) and multi-labeled ImageNet 10K (10032 classes) from Tencent ML-Images. Over 42 evaluations on 7 different dataset/architecture settings x 6 metrics, OTTER outperforms (32) or ties (2) all baselines in 34 of them.