 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyServe: Serving AI Models across Regions and Clouds with Spot Instances
Nov 03, 2024



Recent years have witnessed an explosive growth of AI models. The high cost of hosting AI services on GPUs and their demanding service requirements, make it timely and challenging to lower service costs and guarantee service quality. While spot instances have long been offered with a large discount, spot preemptions have discouraged users from using them to host model replicas when serving AI models. To address this, we introduce SkyServe, a system that efficiently serves AI models over a mixture of spot and on-demand replicas across regions and clouds. SkyServe intelligently spreads spot replicas across different failure domains (e.g., regions or clouds) to improve availability and reduce correlated preemptions, overprovisions cheap spot replicas than required as a safeguard against possible preemptions, and dynamically falls back to on-demand replicas when spot replicas become unavailable. We compare SkyServe with both research and production systems on real AI workloads: SkyServe reduces cost by up to 44% while achieving high resource availability compared to using on-demand replicas. Additionally, SkyServe improves P50, P90, and P99 latency by up to 2.6x, 3.1x, 2.7x compared to other research and production systems.
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
Sep 30, 2023



Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset's content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at https://huggingface.co/datasets/lmsys/lmsys-chat-1m.
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Jun 09, 2023



Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, such as position and verbosity biases and limited reasoning ability, and propose solutions to migrate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and Chatbot Arena, a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80\% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA/Vicuna. We will publicly release 80 MT-bench questions, 3K expert votes, and 30K conversations with human preferences from Chatbot Arena.
Representing Long-Range Context for Graph Neural Networks with Global Attention
Jan 21, 2022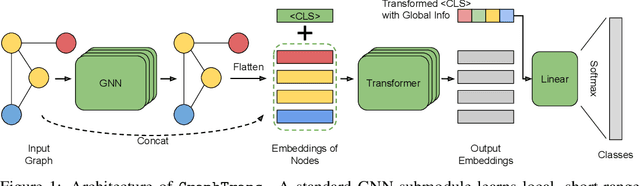
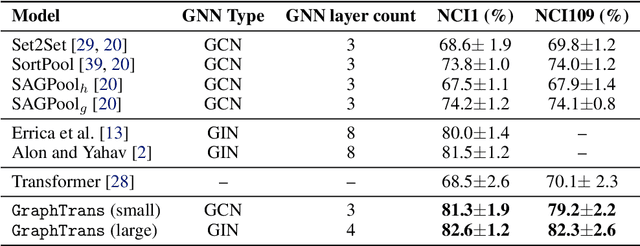
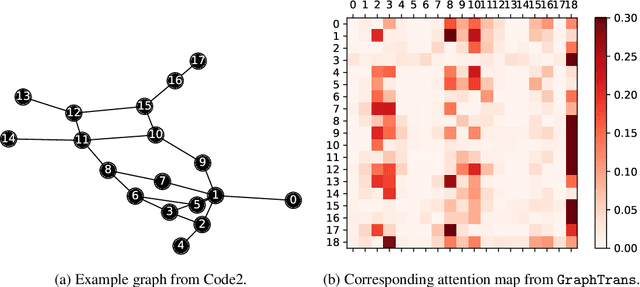
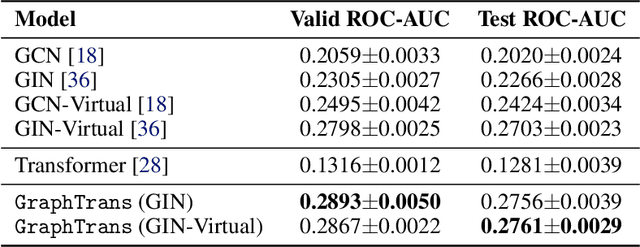
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel "readout" mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs. Code for GraphTrans is available at https://github.com/ucbrise/graphtrans.
Distributed Reinforcement Learning is a Dataflow Problem
Dec 03, 2020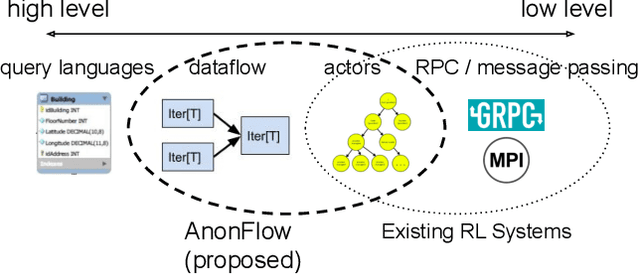
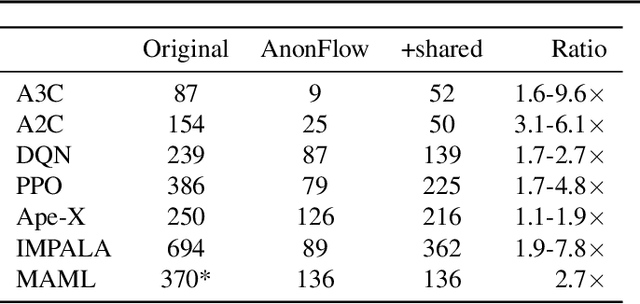
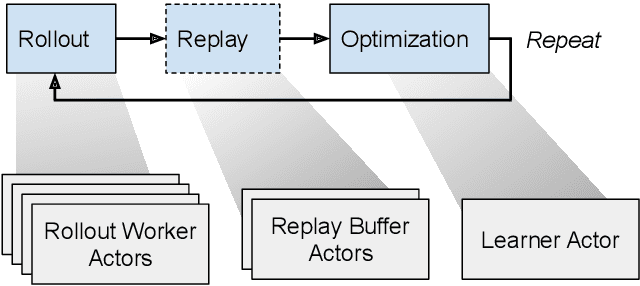
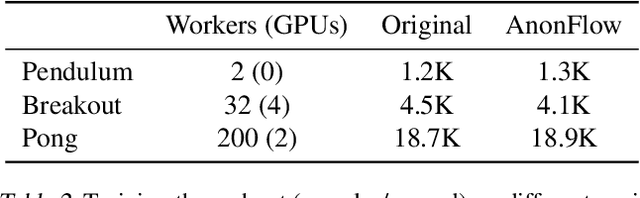
Researchers and practitioners in the field of reinforcement learning (RL) frequently leverage parallel computation, which has led to a plethora of new algorithms and systems in the last few years. In this paper, we re-examine the challenges posed by distributed RL and try to view it through the lens of an old idea: distributed dataflow. We show that viewing RL as a dataflow problem leads to highly composable and performant implementations. We propose AnonFlow, a hybrid actor-dataflow programming model for distributed RL, and validate its practicality by porting the full suite of algorithms in AnonLib, a widely-adopted distributed RL library.
HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
May 28, 2020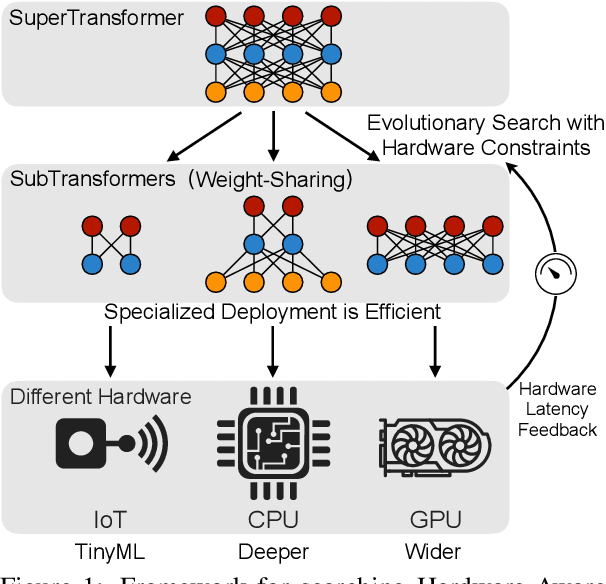
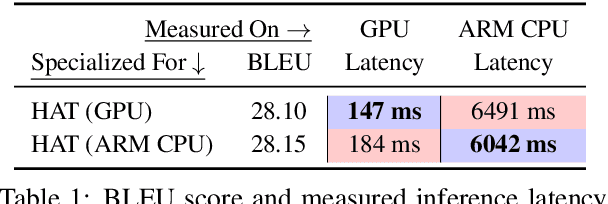
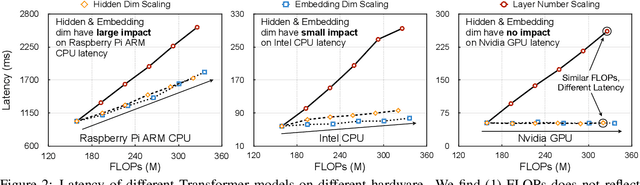
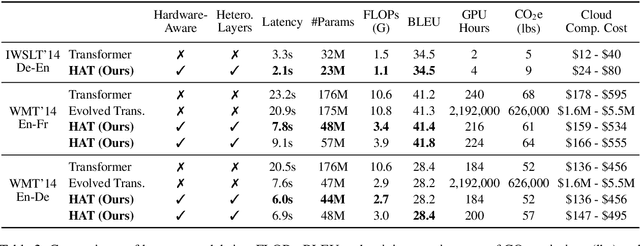
Transformers are ubiquitous in Natural Language Processing (NLP) tasks, but they are difficult to be deployed on hardware due to the intensive computation. To enable low-latency inference on resource-constrained hardware platforms, we propose to design Hardware-Aware Transformers (HAT) with neural architecture search. We first construct a large design space with $\textit{arbitrary encoder-decoder attention}$ and $\textit{heterogeneous layers}$. Then we train a $\textit{SuperTransformer}$ that covers all candidates in the design space, and efficiently produces many $\textit{SubTransformers}$ with weight sharing. Finally, we perform an evolutionary search with a hardware latency constraint to find a specialized $\textit{SubTransformer}$ dedicated to run fast on the target hardware. Extensive experiments on four machine translation tasks demonstrate that HAT can discover efficient models for different hardware (CPU, GPU, IoT device). When running WMT'14 translation task on Raspberry Pi-4, HAT can achieve $\textbf{3}\times$ speedup, $\textbf{3.7}\times$ smaller size over baseline Transformer; $\textbf{2.7}\times$ speedup, $\textbf{3.6}\times$ smaller size over Evolved Transformer with $\textbf{12,041}\times$ less search cost and no performance loss. HAT code is https://github.com/mit-han-lab/hardware-aware-transformers.git
Lite Transformer with Long-Short Range Attention
Apr 24, 2020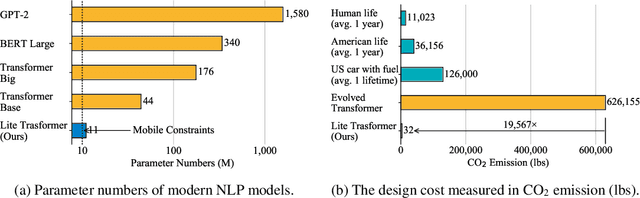
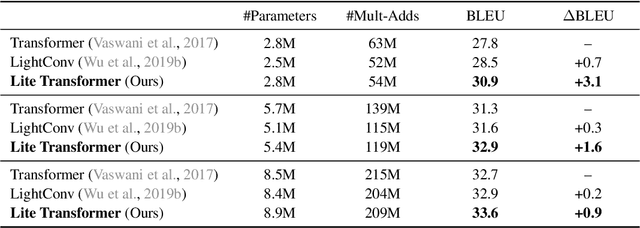
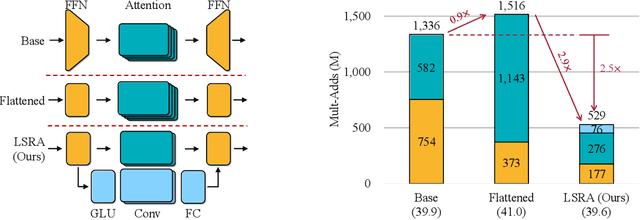
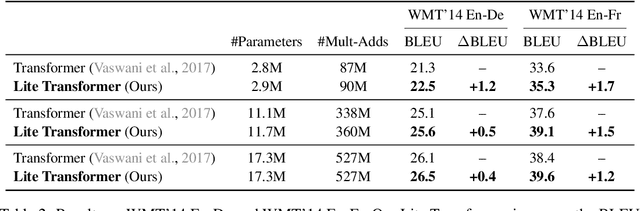
Transformer has become ubiquitous in natural language processing (e.g., machine translation, question answering); however, it requires enormous amount of computations to achieve high performance, which makes it not suitable for mobile applications that are tightly constrained by the hardware resources and battery. In this paper, we present an efficient mobile NLP architecture, Lite Transformer to facilitate deploying mobile NLP applications on edge devices. The key primitive is the Long-Short Range Attention (LSRA), where one group of heads specializes in the local context modeling (by convolution) while another group specializes in the long-distance relationship modeling (by attention). Such specialization brings consistent improvement over the vanilla transformer on three well-established language tasks: machine translation, abstractive summarization, and language modeling. Under constrained resources (500M/100M MACs), Lite Transformer outperforms transformer on WMT'14 English-French by 1.2/1.7 BLEU, respectively. Lite Transformer reduces the computation of transformer base model by 2.5x with 0.3 BLEU score degradation. Combining with pruning and quantization, we further compressed the model size of Lite Transformer by 18.2x. For language modeling, Lite Transformer achieves 1.8 lower perplexity than the transformer at around 500M MACs. Notably, Lite Transformer outperforms the AutoML-based Evolved Transformer by 0.5 higher BLEU for the mobile NLP setting without the costly architecture search that requires more than 250 GPU years. Code has been made available at https://github.com/mit-han-lab/lite-transformer.