 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Network with Novel Quantization Designed for Massive MIMO CSI Feedback
May 30, 2024



The efficacy of massive multiple-input multiple-output (MIMO) techniques heavily relies on the accuracy of channel state information (CSI) in frequency division duplexing (FDD) systems. Many works focus on CSI compression and quantization methods to enhance CSI reconstruction accuracy with lower feedback overhead. In this letter, we propose CsiConformer, a novel CSI feedback network that combines convolutional operations and self-attention mechanisms to improve CSI feedback accuracy. Additionally, a new quantization module is developed to improve encoding efficiency. Experiment results show that CsiConformer outperforms previous state-of-the-art networks, achieving an average accuracy improvement of 17.67\% with lower computational overhead.
Teach LLMs to Phish: Stealing Private Information from Language Models
Mar 01, 2024



When large language models are trained on private data, it can be a significant privacy risk for them to memorize and regurgitate sensitive information. In this work, we propose a new practical data extraction attack that we call "neural phishing". This attack enables an adversary to target and extract sensitive or personally identifiable information (PII), e.g., credit card numbers, from a model trained on user data with upwards of 10% attack success rates, at times, as high as 50%. Our attack assumes only that an adversary can insert as few as 10s of benign-appearing sentences into the training dataset using only vague priors on the structure of the user data.
Digital Twin-Enhanced Deep Reinforcement Learning for Resource Management in Networks Slicing
Nov 28, 2023



Network slicing-based communication systems can dynamically and efficiently allocate resources for diversified services. However, due to the limitation of the network interface on channel access and the complexity of the resource allocation, it is challenging to achieve an acceptable solution in the practical system without precise prior knowledge of the dynamics probability model of the service requests. Existing work attempts to solve this problem using deep reinforcement learning (DRL), however, such methods usually require a lot of interaction with the real environment in order to achieve good results. In this paper, a framework consisting of a digital twin and reinforcement learning agents is present to handle the issue. Specifically, we propose to use the historical data and the neural networks to build a digital twin model to simulate the state variation law of the real environment. Then, we use the data generated by the network slicing environment to calibrate the digital twin so that it is in sync with the real environment. Finally, DRL for slice optimization optimizes its own performance in this virtual pre-verification environment. We conducted an exhaustive verification of the proposed digital twin framework to confirm its scalability. Specifically, we propose to use loss landscapes to visualize the generalization of DRL solutions. We explore a distillation-based optimization scheme for lightweight slicing strategies. In addition, we also extend the framework to offline reinforcement learning, where solutions can be used to obtain intelligent decisions based solely on historical data. Numerical simulation experiments show that the proposed digital twin can significantly improve the performance of the slice optimization strategy.
An Efficient Probabilistic Solution to Mapping Errors in LiDAR-Camera Fusion for Autonomous Vehicles
Nov 08, 2023



LiDAR-camera fusion is one of the core processes for the perception system of current automated driving systems. The typical sensor fusion process includes a list of coordinate transformation operations following system calibration. Although a significant amount of research has been done to improve the fusion accuracy, there are still inherent data mapping errors in practice related to system synchronization offsets, vehicle vibrations, the small size of the target, and fast relative moving speeds. Moreover, more and more complicated algorithms to improve fusion accuracy can overwhelm the onboard computational resources, limiting the actual implementation. This study proposes a novel and low-cost probabilistic LiDAR-Camera fusion method to alleviate these inherent mapping errors in scene reconstruction. By calculating shape similarity using KL-divergence and applying RANSAC-regression-based trajectory smoother, the effects of LiDAR-camera mapping errors are minimized in object localization and distance estimation. Designed experiments are conducted to prove the robustness and effectiveness of the proposed strategy.
AIR-DA: Adversarial Image Reconstruction for Unsupervised Domain Adaptive Object Detection
Mar 27, 2023



Unsupervised domain adaptive object detection is a challenging vision task where object detectors are adapted from a label-rich source domain to an unlabeled target domain. Recent advances prove the efficacy of the adversarial based domain alignment where the adversarial training between the feature extractor and domain discriminator results in domain-invariance in the feature space. However, due to the domain shift, domain discrimination, especially on low-level features, is an easy task. This results in an imbalance of the adversarial training between the domain discriminator and the feature extractor. In this work, we achieve a better domain alignment by introducing an auxiliary regularization task to improve the training balance. Specifically, we propose Adversarial Image Reconstruction (AIR) as the regularizer to facilitate the adversarial training of the feature extractor. We further design a multi-level feature alignment module to enhance the adaptation performance. Our evaluations across several datasets of challenging domain shifts demonstrate that the proposed method outperforms all previous methods, of both one- and two-stage, in most settings.
Neurotoxin: Durable Backdoors in Federated Learning
Jun 12, 2022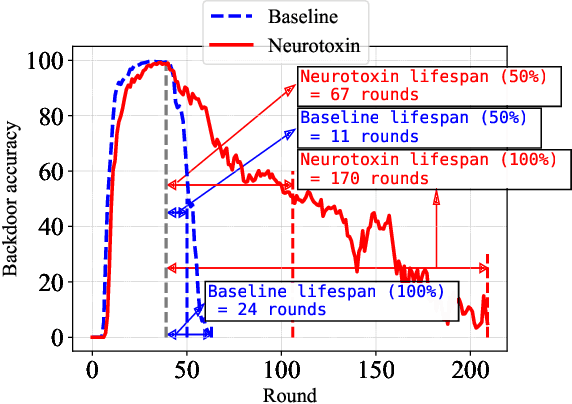

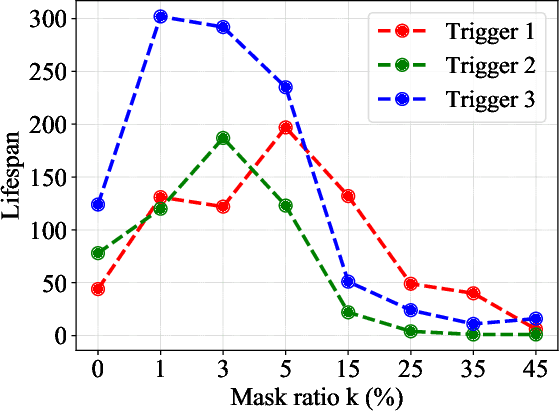
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.
Joint User Association and Power Allocation in Heterogeneous Ultra Dense Network via Semi-Supervised Representation Learning
Mar 29, 2021
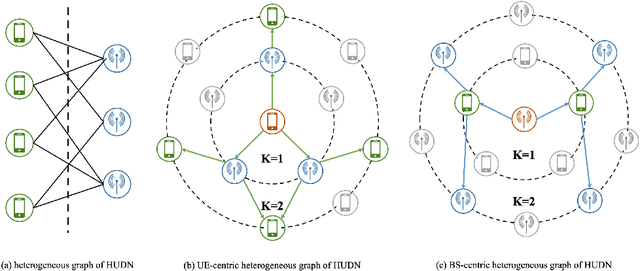
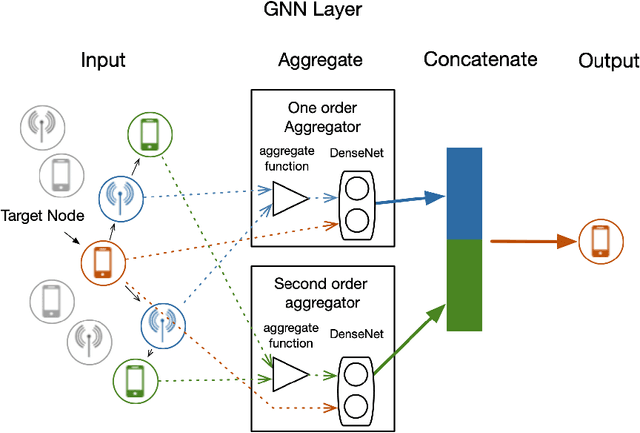
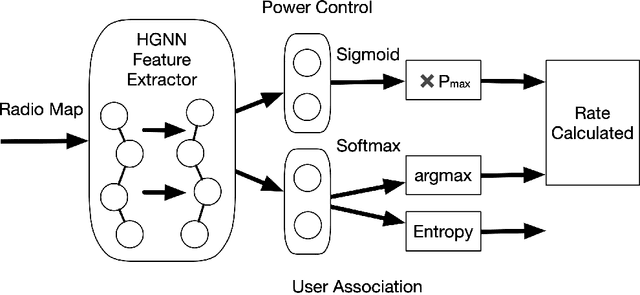
Heterogeneous Ultra-Dense Network (HUDN) is one of the vital networking architectures due to its ability to enable higher connectivity density and ultra-high data rates. Rational user association and power control schedule in HUDN can reduce wireless interference. This paper proposes a novel idea for resolving the joint user association and power control problem: the optimal user association and Base Station transmit power can be represented by channel information. Then, we solve this problem by formulating an optimal representation function. We model the HUDNs as a heterogeneous graph and train a Graph Neural Network (GNN) to approach this representation function by using semi-supervised learning, in which the loss function is composed of the unsupervised part that helps the GNN approach the optimal representation function and the supervised part that utilizes the previous experience to reduce useless exploration. We separate the learning process into two parts, the generalization-representation learning (GRL) part and the specialization-representation learning (SRL) part, which train the GNN for learning representation for generalized scenario quasi-static user distribution scenario, respectively. Simulation results demonstrate that the proposed GRL-based solution has higher computational efficiency than the traditional optimization algorithm, and the performance of SRL outperforms the GRL.
Benchmarking Semi-supervised Federated Learning
Aug 26, 2020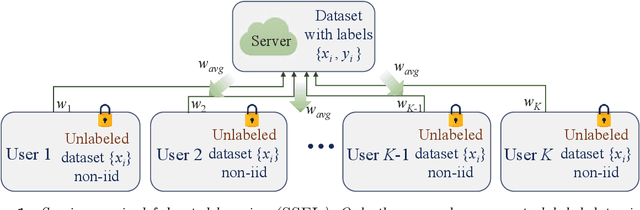

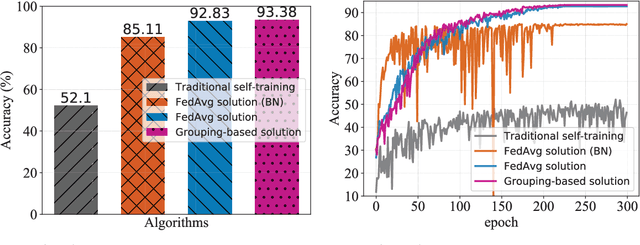
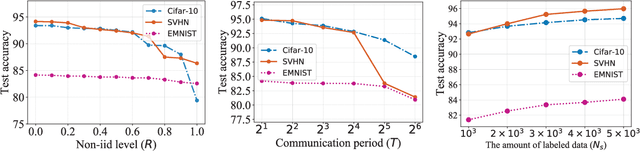
Federated learning promises to use the computational power of edge devices while maintaining user data privacy. Current frameworks, however, typically make the unrealistic assumption that the data stored on user devices come with ground truth labels, while the server has no data. In this work, we consider the more realistic scenario where the users have only unlabeled data and the server has a limited amount of labeled data. In this semi-supervised federated learning (ssfl) setting, the data distribution can be non-iid, in the sense of different distributions of classes at different users. We define a metric, $R$, to measure this non-iidness in class distributions. In this setting, we provide a thorough study on different factors that can affect the final test accuracy, including algorithm design (such as training objective), the non-iidness $R$, the communication period $T$, the number of users $K$, the amount of labeled data in the server $N_s$, and the number of users $C_k\leq K$ that communicate with the server in each communication round. We evaluate our ssfl framework on Cifar-10, SVHN, and EMNIST. Overall, we find that a simple consistency loss-based method, along with group normalization, achieves better generalization performance, even compared to previous supervised federated learning settings. Furthermore, we propose a novel grouping-based model average method to improve convergence efficiency, and we show that this can boost performance by up to 10.79% on EMNIST, compared to the non-grouping based method.