 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking People by Predicting 3D Appearance, Location & Pose
Dec 08, 2021
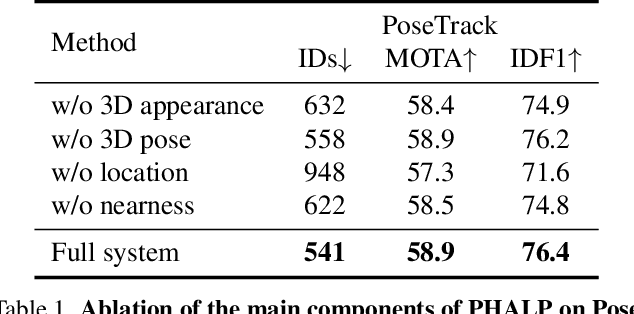
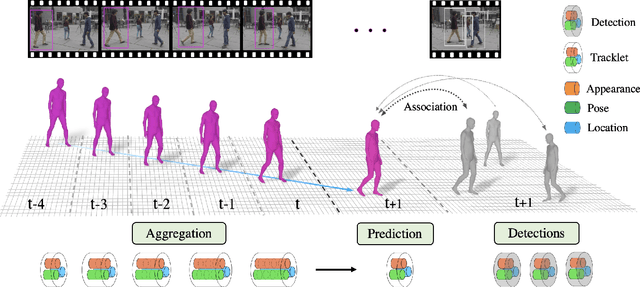

In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.
Coupling Vision and Proprioception for Navigation of Legged Robots
Dec 03, 2021
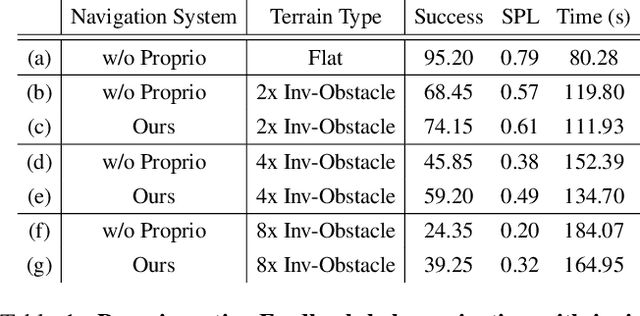
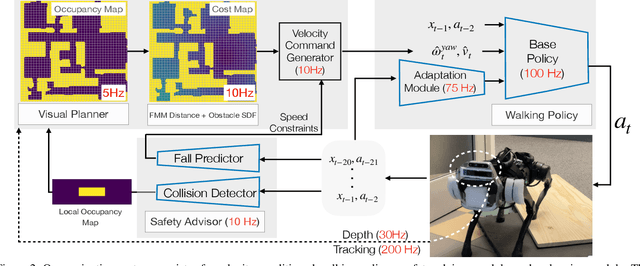
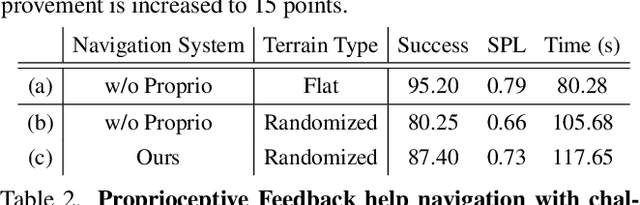
We exploit the complementary strengths of vision and proprioception to achieve point goal navigation in a legged robot. Legged systems are capable of traversing more complex terrain than wheeled robots, but to fully exploit this capability, we need the high-level path planner in the navigation system to be aware of the walking capabilities of the low-level locomotion policy on varying terrains. We achieve this by using proprioceptive feedback to estimate the safe operating limits of the walking policy, and to sense unexpected obstacles and terrain properties like smoothness or softness of the ground that may be missed by vision. The navigation system uses onboard cameras to generate an occupancy map and a corresponding cost map to reach the goal. The FMM (Fast Marching Method) planner then generates a target path. The velocity command generator takes this as input to generate the desired velocity for the locomotion policy using as input additional constraints, from the safety advisor, of unexpected obstacles and terrain determined speed limits. We show superior performance compared to wheeled robot (LoCoBot) baselines, and other baselines which have disjoint high-level planning and low-level control. We also show the real-world deployment of our system on a quadruped robot with onboard sensors and compute. Videos at https://navigation-locomotion.github.io/camera-ready
Improved Multiscale Vision Transformers for Classification and Detection
Dec 02, 2021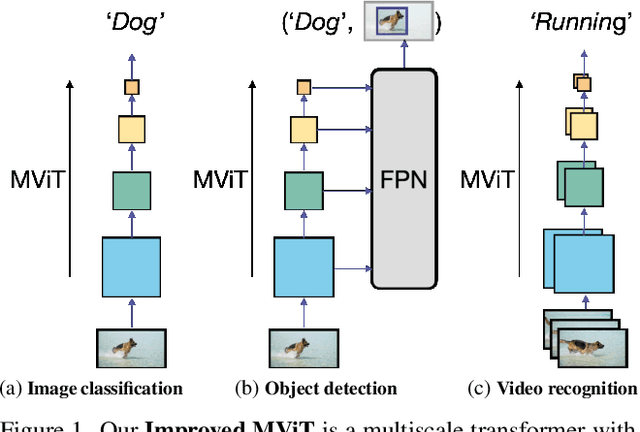
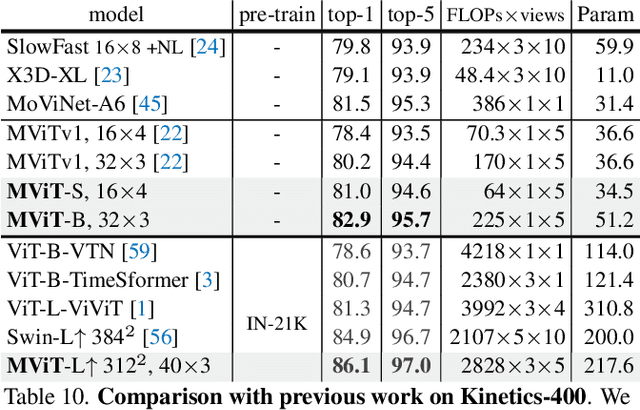
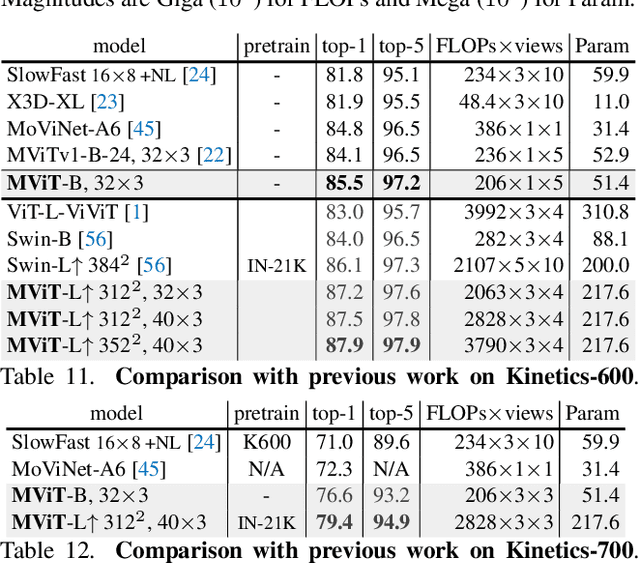
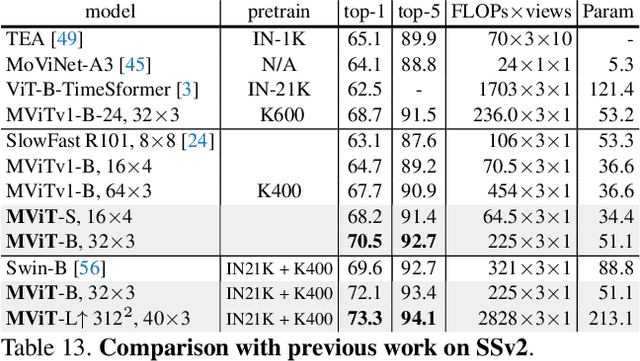
In this paper, we study Multiscale Vision Transformers (MViT) as a unified architecture for image and video classification, as well as object detection. We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections. We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work. We further compare MViTs' pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute. Without bells-and-whistles, MViT has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 56.1 box AP on COCO object detection as well as 86.1% on Kinetics-400 video classification. Code and models will be made publicly available.
Differentiable Spatial Planning using Transformers
Dec 02, 2021

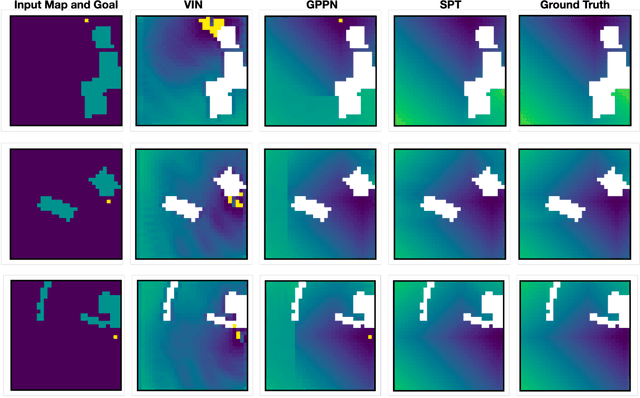
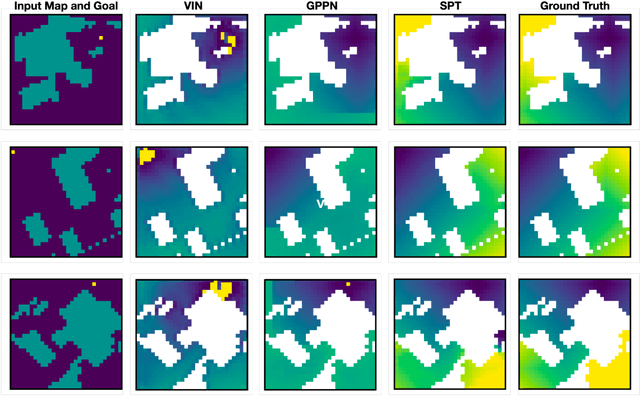
We consider the problem of spatial path planning. In contrast to the classical solutions which optimize a new plan from scratch and assume access to the full map with ground truth obstacle locations, we learn a planner from the data in a differentiable manner that allows us to leverage statistical regularities from past data. We propose Spatial Planning Transformers (SPT), which given an obstacle map learns to generate actions by planning over long-range spatial dependencies, unlike prior data-driven planners that propagate information locally via convolutional structure in an iterative manner. In the setting where the ground truth map is not known to the agent, we leverage pre-trained SPTs in an end-to-end framework that has the structure of mapper and planner built into it which allows seamless generalization to out-of-distribution maps and goals. SPTs outperform prior state-of-the-art differentiable planners across all the setups for both manipulation and navigation tasks, leading to an absolute improvement of 7-19%.
SEAL: Self-supervised Embodied Active Learning using Exploration and 3D Consistency
Dec 02, 2021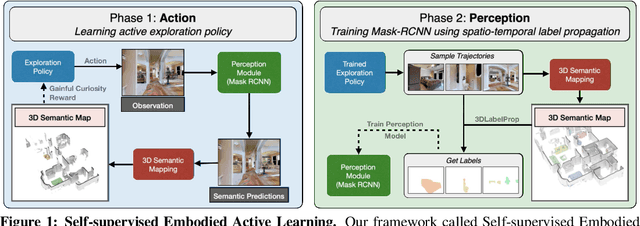
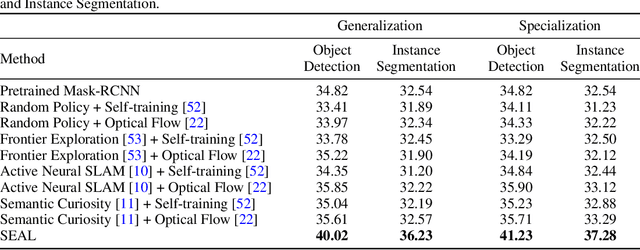
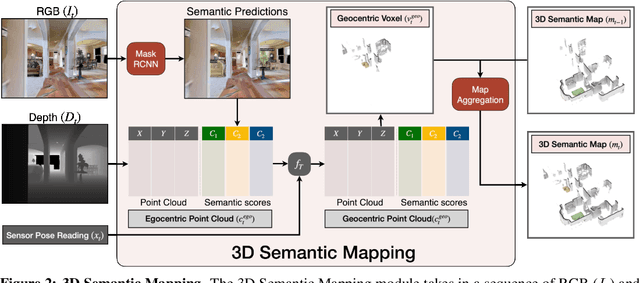

In this paper, we explore how we can build upon the data and models of Internet images and use them to adapt to robot vision without requiring any extra labels. We present a framework called Self-supervised Embodied Active Learning (SEAL). It utilizes perception models trained on internet images to learn an active exploration policy. The observations gathered by this exploration policy are labelled using 3D consistency and used to improve the perception model. We build and utilize 3D semantic maps to learn both action and perception in a completely self-supervised manner. The semantic map is used to compute an intrinsic motivation reward for training the exploration policy and for labelling the agent observations using spatio-temporal 3D consistency and label propagation. We demonstrate that the SEAL framework can be used to close the action-perception loop: it improves object detection and instance segmentation performance of a pretrained perception model by just moving around in training environments and the improved perception model can be used to improve Object Goal Navigation.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
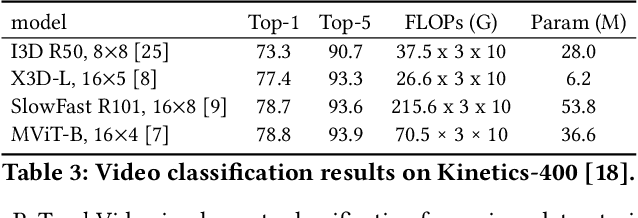

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Tracking People with 3D Representations
Nov 15, 2021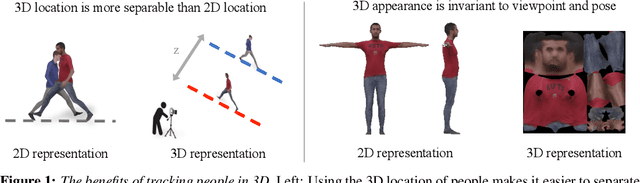
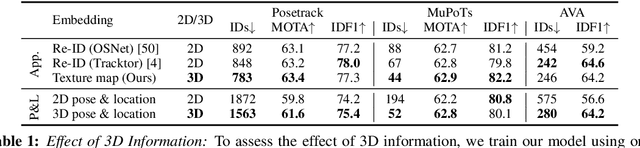
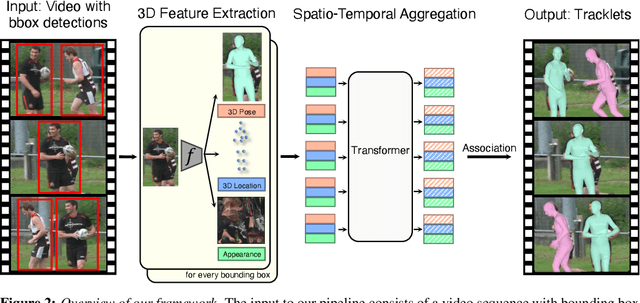
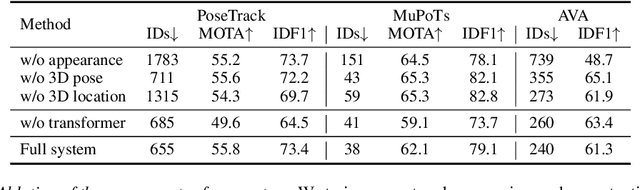
We present a novel approach for tracking multiple people in video. Unlike past approaches which employ 2D representations, we focus on using 3D representations of people, located in three-dimensional space. To this end, we develop a method, Human Mesh and Appearance Recovery (HMAR) which in addition to extracting the 3D geometry of the person as a SMPL mesh, also extracts appearance as a texture map on the triangles of the mesh. This serves as a 3D representation for appearance that is robust to viewpoint and pose changes. Given a video clip, we first detect bounding boxes corresponding to people, and for each one, we extract 3D appearance, pose, and location information using HMAR. These embedding vectors are then sent to a transformer, which performs spatio-temporal aggregation of the representations over the duration of the sequence. The similarity of the resulting representations is used to solve for associations that assigns each person to a tracklet. We evaluate our approach on the Posetrack, MuPoTs and AVA datasets. We find that 3D representations are more effective than 2D representations for tracking in these settings, and we obtain state-of-the-art performance. Code and results are available at: https://brjathu.github.io/T3DP.
Minimizing Energy Consumption Leads to the Emergence of Gaits in Legged Robots
Oct 25, 2021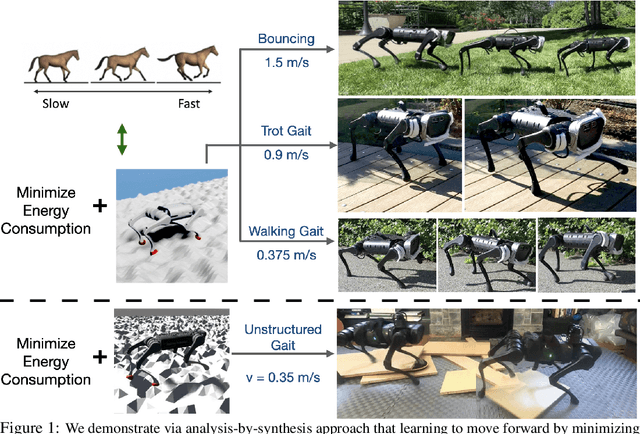
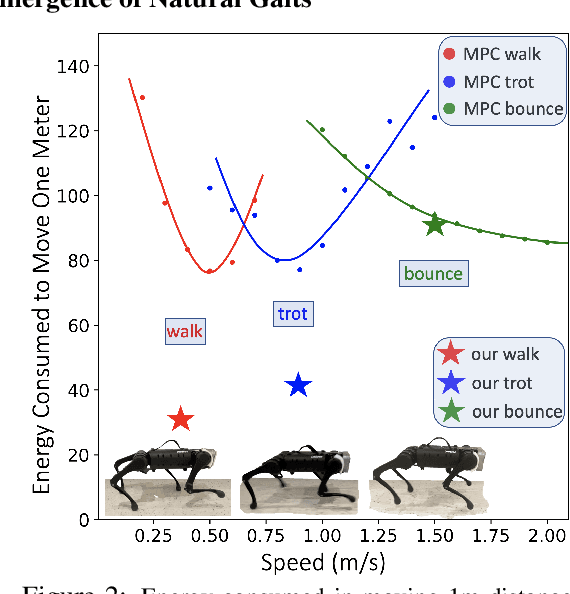

Legged locomotion is commonly studied and expressed as a discrete set of gait patterns, like walk, trot, gallop, which are usually treated as given and pre-programmed in legged robots for efficient locomotion at different speeds. However, fixing a set of pre-programmed gaits limits the generality of locomotion. Recent animal motor studies show that these conventional gaits are only prevalent in ideal flat terrain conditions while real-world locomotion is unstructured and more like bouts of intermittent steps. What principles could lead to both structured and unstructured patterns across mammals and how to synthesize them in robots? In this work, we take an analysis-by-synthesis approach and learn to move by minimizing mechanical energy. We demonstrate that learning to minimize energy consumption plays a key role in the emergence of natural locomotion gaits at different speeds in real quadruped robots. The emergent gaits are structured in ideal terrains and look similar to that of horses and sheep. The same approach leads to unstructured gaits in rough terrains which is consistent with the findings in animal motor control. We validate our hypothesis in both simulation and real hardware across natural terrains. Videos at https://energy-locomotion.github.io
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
ABO: Dataset and Benchmarks for Real-World 3D Object Understanding
Oct 12, 2021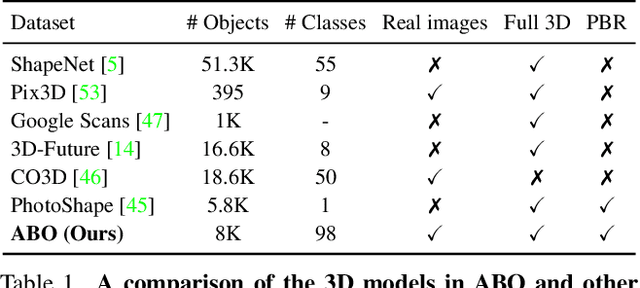
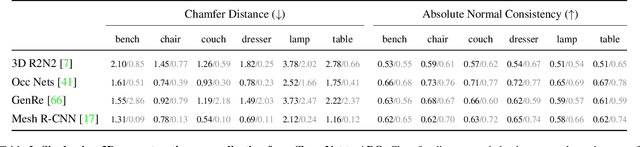
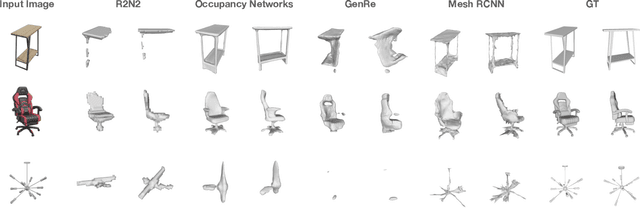
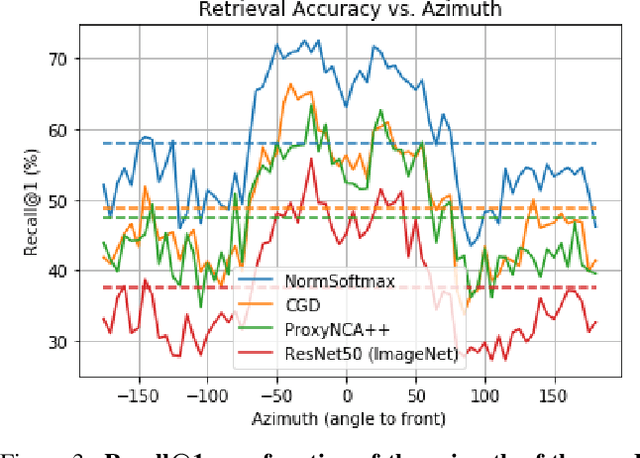
We introduce Amazon-Berkeley Objects (ABO), a new large-scale dataset of product images and 3D models corresponding to real household objects. We use this realistic, object-centric 3D dataset to measure the domain gap for single-view 3D reconstruction networks trained on synthetic objects. We also use multi-view images from ABO to measure the robustness of state-of-the-art metric learning approaches to different camera viewpoints. Finally, leveraging the physically-based rendering materials in ABO, we perform single- and multi-view material estimation for a variety of complex, real-world geometries. The full dataset is available for download at https://amazon-berkeley-objects.s3.amazonaws.com/index.html.