 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Prompt Biasing for Contextualized End-to-End ASR Systems
Jun 06, 2025End-to-End Automatic Speech Recognition (ASR) has advanced significantly yet still struggles with rare and domain-specific entities. This paper introduces a simple yet efficient prompt-based biasing technique for contextualized ASR, enhancing recognition accuracy by leverage a unified multitask learning framework. The approach comprises two key components: a prompt biasing model which is trained to determine when to focus on entities in prompt, and a entity filtering mechanism which efficiently filters out irrelevant entities. Our method significantly enhances ASR accuracy on entities, achieving a relative 30.7% and 18.0% reduction in Entity Word Error Rate compared to the baseline model with shallow fusion on in-house domain dataset with small and large entity lists, respectively. The primary advantage of this method lies in its efficiency and simplicity without any structure change, making it lightweight and highly efficient.
Phi-Omni-ST: A multimodal language model for direct speech-to-speech translation
Jun 04, 2025Speech-aware language models (LMs) have demonstrated capabilities in understanding spoken language while generating text-based responses. However, enabling them to produce speech output efficiently and effectively remains a challenge. In this paper, we present Phi-Omni-ST, a multimodal LM for direct speech-to-speech translation (ST), built on the open-source Phi-4 MM model. Phi-Omni-ST extends its predecessor by generating translated speech using an audio transformer head that predicts audio tokens with a delay relative to text tokens, followed by a streaming vocoder for waveform synthesis. Our experimental results on the CVSS-C dataset demonstrate Phi-Omni-ST's superior performance, significantly surpassing existing baseline models trained on the same dataset. Furthermore, when we scale up the training data and the model size, Phi-Omni-ST reaches on-par performance with the current SOTA model.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025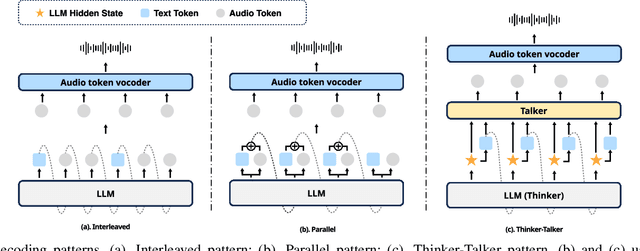
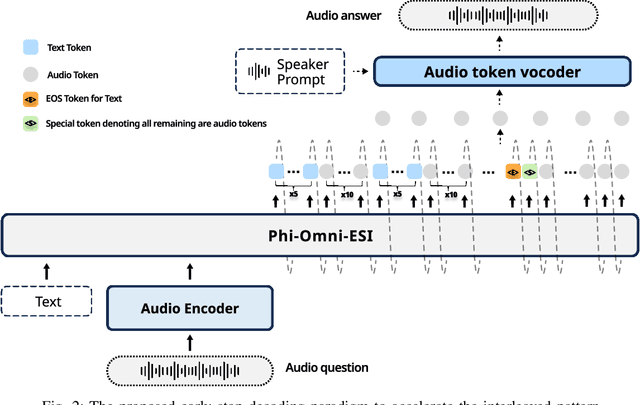


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Apr 14, 2025



Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning
Feb 19, 2025



End-to-end autonomous driving, which directly maps raw sensor inputs to low-level vehicle controls, is an important part of Embodied AI. Despite successes in applying Multimodal Large Language Models (MLLMs) for high-level traffic scene semantic understanding, it remains challenging to effectively translate these conceptual semantics understandings into low-level motion control commands and achieve generalization and consensus in cross-scene driving. We introduce Sce2DriveX, a human-like driving chain-of-thought (CoT) reasoning MLLM framework. Sce2DriveX utilizes multimodal joint learning from local scene videos and global BEV maps to deeply understand long-range spatiotemporal relationships and road topology, enhancing its comprehensive perception and reasoning capabilities in 3D dynamic/static scenes and achieving driving generalization across scenes. Building on this, it reconstructs the implicit cognitive chain inherent in human driving, covering scene understanding, meta-action reasoning, behavior interpretation analysis, motion planning and control, thereby further bridging the gap between autonomous driving and human thought processes. To elevate model performance, we have developed the first extensive Visual Question Answering (VQA) driving instruction dataset tailored for 3D spatial understanding and long-axis task reasoning. Extensive experiments demonstrate that Sce2DriveX achieves state-of-the-art performance from scene understanding to end-to-end driving, as well as robust generalization on the CARLA Bench2Drive benchmark.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
Addressing speaker gender bias in large scale speech translation systems
Jan 10, 2025



This study addresses the issue of speaker gender bias in Speech Translation (ST) systems, which can lead to offensive and inaccurate translations. The masculine bias often found in large-scale ST systems is typically perpetuated through training data derived from Machine Translation (MT) systems. Our approach involves two key steps. First, we employ Large Language Models (LLMs) to rectify translations based on the speaker's gender in a cost-effective manner. Second, we fine-tune the ST model with the corrected data, enabling the model to generate gender-specific translations directly from audio cues, without the need for explicit gender input. Additionally, we propose a three-mode fine-tuned model for scenarios where the speaker's gender is either predefined or should not be inferred from speech cues. We demonstrate a 70% improvement in translations for female speakers compared to our baseline and other large-scale ST systems, such as Seamless M4T and Canary, on the MuST-SHE test set.
Interleaved Speech-Text Language Models are Simple Streaming Text to Speech Synthesizers
Dec 23, 2024This paper introduces Interleaved Speech-Text Language Model (IST-LM) for streaming zero-shot Text-to-Speech (TTS). Unlike many previous approaches, IST-LM is directly trained on interleaved sequences of text and speech tokens with a fixed ratio, eliminating the need for additional efforts in duration prediction and grapheme-to-phoneme alignment. The ratio of text chunk size to speech chunk size is crucial for the performance of IST-LM. To explore this, we conducted a comprehensive series of statistical analyses on the training data and performed correlation analysis with the final performance, uncovering several key factors: 1) the distance between speech tokens and their corresponding text tokens, 2) the number of future text tokens accessible to each speech token, and 3) the frequency of speech tokens precedes their corresponding text tokens. Experimental results demonstrate how to achieve an optimal streaming TTS system without complicated engineering optimization, which has a limited gap with the non-streaming system. IST-LM is conceptually simple and empirically powerful, paving the way for streaming TTS with minimal overhead while largely maintaining performance, showcasing broad prospects coupled with real-time text stream from LLMs.
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Dec 20, 2024



Recent advancements highlight the potential of end-to-end real-time spoken dialogue systems, showcasing their low latency and high quality. In this paper, we introduce SLAM-Omni, a timbre-controllable, end-to-end voice interaction system with single-stage training. SLAM-Omni achieves zero-shot timbre control by modeling spoken language with semantic tokens and decoupling speaker information to a vocoder. By predicting grouped speech semantic tokens at each step, our method significantly reduces the sequence length of audio tokens, accelerating both training and inference. Additionally, we propose historical text prompting to compress dialogue history, facilitating efficient multi-round interactions. Comprehensive evaluations reveal that SLAM-Omni outperforms prior models of similar scale, requiring only 15 hours of training on 4 GPUs with limited data. Notably, it is the first spoken dialogue system to achieve competitive performance with a single-stage training approach, eliminating the need for pre-training on TTS or ASR tasks. Further experiments validate its multilingual and multi-turn dialogue capabilities on larger datasets.