 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
Jun 12, 2024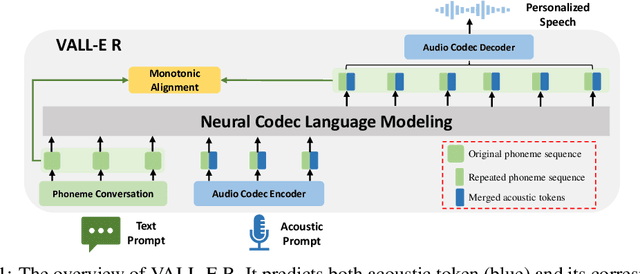

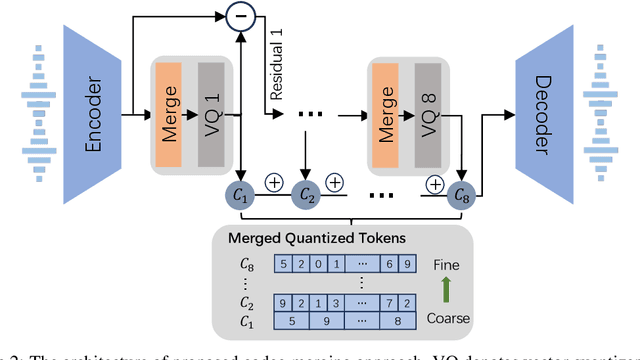

With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a codec-merging approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth. In addition, it requires fewer autoregressive steps, with over 60% time reduction during inference. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia. Audio samples will be available at: https://aka.ms/valler.