 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Image Super Resolution Via Heterogeneous Model using GP-NAS
Sep 02, 2020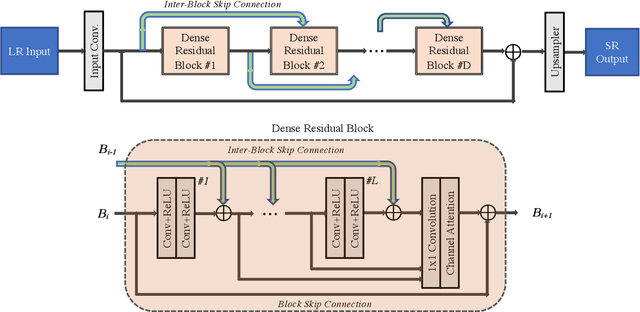
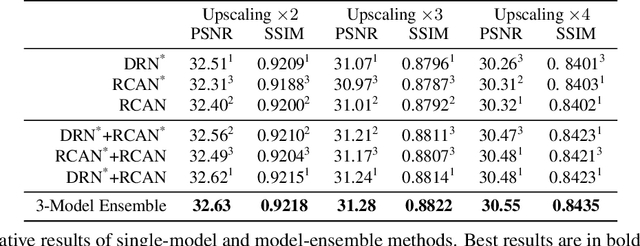
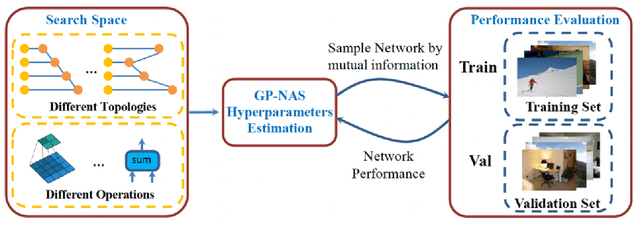
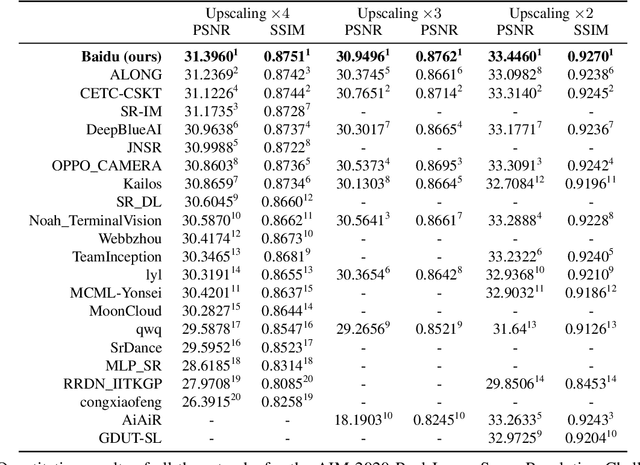
With advancement in deep neural network (DNN), recent state-of-the-art (SOTA) image superresolution (SR) methods have achieved impressive performance using deep residual network with dense skip connections. While these models perform well on benchmark dataset where low-resolution (LR) images are constructed from high-resolution (HR) references with known blur kernel, real image SR is more challenging when both images in the LR-HR pair are collected from real cameras. Based on existing dense residual networks, a Gaussian process based neural architecture search (GP-NAS) scheme is utilized to find candidate network architectures using a large search space by varying the number of dense residual blocks, the block size and the number of features. A suite of heterogeneous models with diverse network structure and hyperparameter are selected for model-ensemble to achieve outstanding performance in real image SR. The proposed method won the first place in all three tracks of the AIM 2020 Real Image Super-Resolution Challenge.
Learning Global Structure Consistency for Robust Object Tracking
Aug 26, 2020
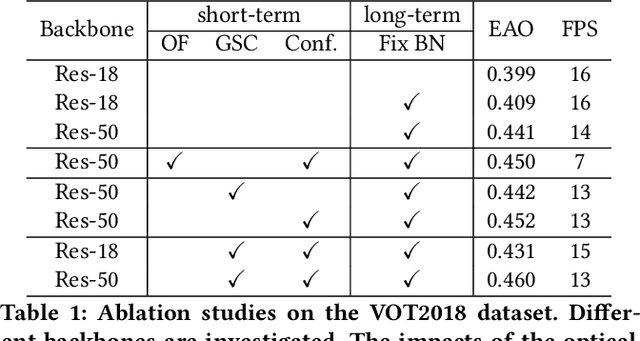
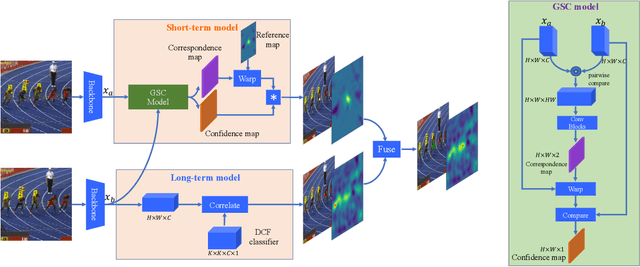
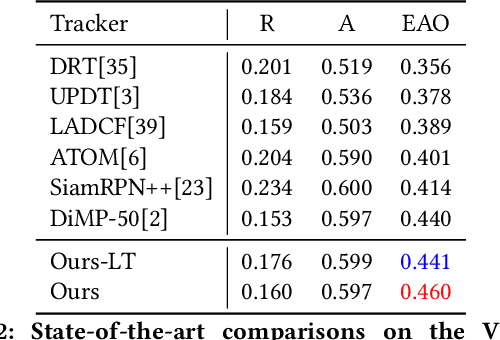
Fast appearance variations and the distractions of similar objects are two of the most challenging problems in visual object tracking. Unlike many existing trackers that focus on modeling only the target, in this work, we consider the \emph{transient variations of the whole scene}. The key insight is that the object correspondence and spatial layout of the whole scene are consistent (i.e., global structure consistency) in consecutive frames which helps to disambiguate the target from distractors. Moreover, modeling transient variations enables to localize the target under fast variations. Specifically, we propose an effective and efficient short-term model that learns to exploit the global structure consistency in a short time and thus can handle fast variations and distractors. Since short-term modeling falls short of handling occlusion and out of the views, we adopt the long-short term paradigm and use a long-term model that corrects the short-term model when it drifts away from the target or the target is not present. These two components are carefully combined to achieve the balance of stability and plasticity during tracking. We empirically verify that the proposed tracker can tackle the two challenging scenarios and validate it on large scale benchmarks. Remarkably, our tracker improves state-of-the-art-performance on VOT2018 from 0.440 to 0.460, GOT-10k from 0.611 to 0.640, and NFS from 0.619 to 0.629.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020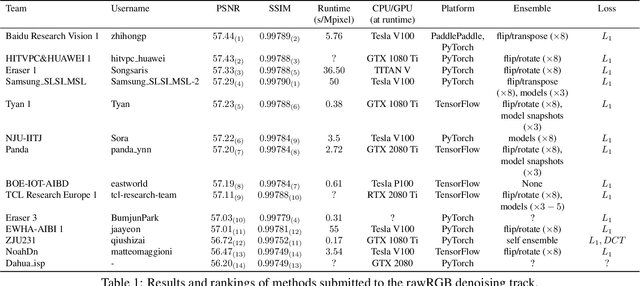
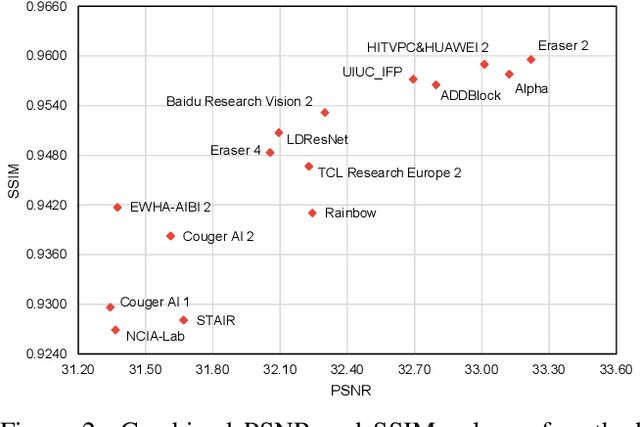
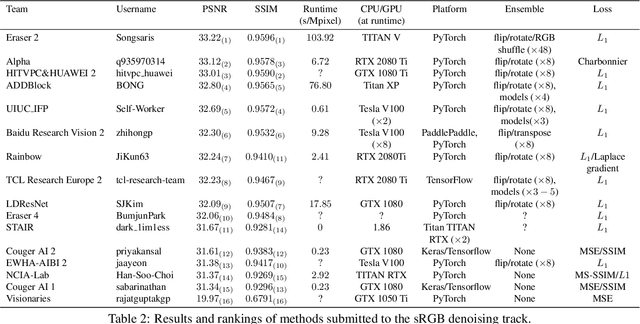
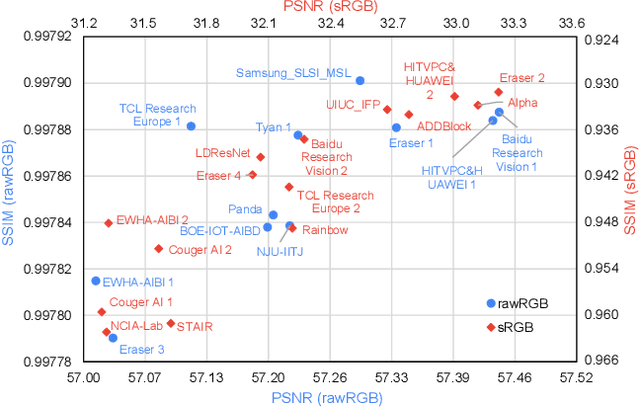
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Learning Generalized Spoof Cues for Face Anti-spoofing
May 08, 2020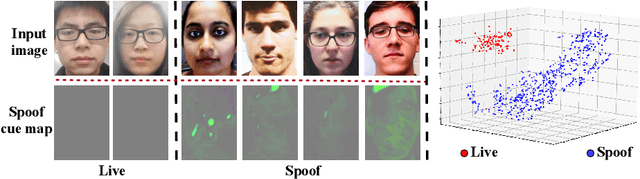
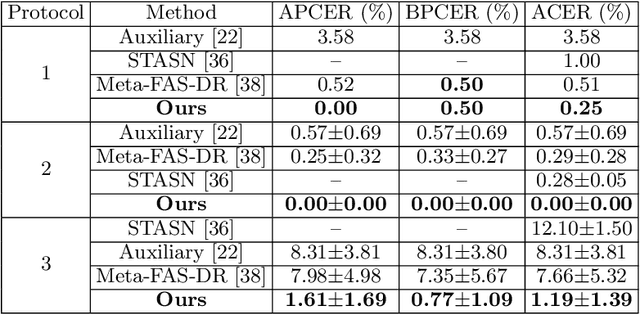
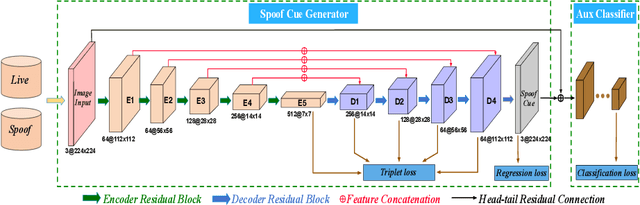
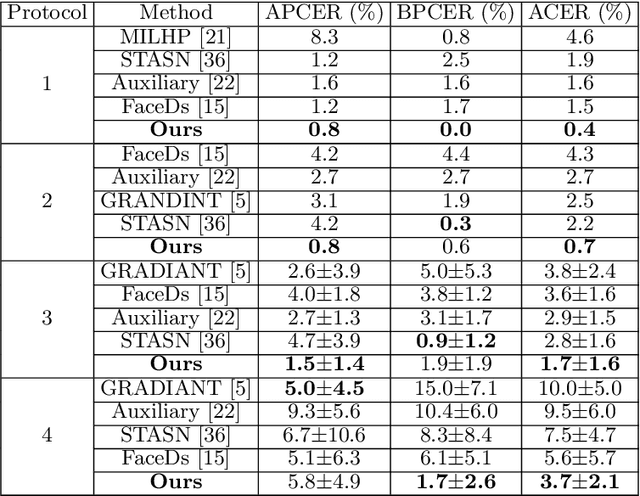
Many existing face anti-spoofing (FAS) methods focus on modeling the decision boundaries for some predefined spoof types. However, the diversity of the spoof samples including the unknown ones hinders the effective decision boundary modeling and leads to weak generalization capability. In this paper, we reformulate FAS in an anomaly detection perspective and propose a residual-learning framework to learn the discriminative live-spoof differences which are defined as the spoof cues. The proposed framework consists of a spoof cue generator and an auxiliary classifier. The generator minimizes the spoof cues of live samples while imposes no explicit constraint on those of spoof samples to generalize well to unseen attacks. In this way, anomaly detection is implicitly used to guide spoof cue generation, leading to discriminative feature learning. The auxiliary classifier serves as a spoof cue amplifier and makes the spoof cues more discriminative. We conduct extensive experiments and the experimental results show the proposed method consistently outperforms the state-of-the-art methods. The code will be publicly available at https://github.com/vis-var/lgsc-for-fas.
Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
Mar 27, 2020
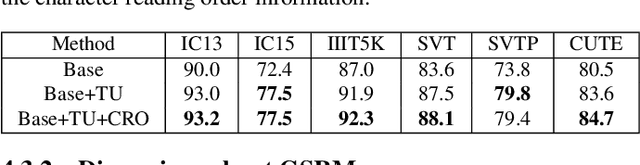
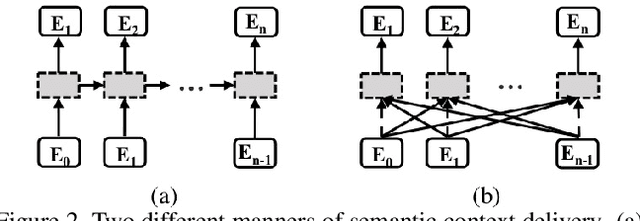
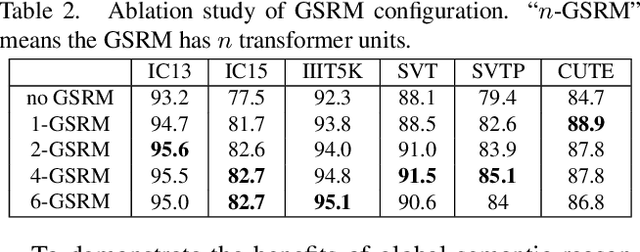
Scene text image contains two levels of contents: visual texture and semantic information. Although the previous scene text recognition methods have made great progress over the past few years, the research on mining semantic information to assist text recognition attracts less attention, only RNN-like structures are explored to implicitly model semantic information. However, we observe that RNN based methods have some obvious shortcomings, such as time-dependent decoding manner and one-way serial transmission of semantic context, which greatly limit the help of semantic information and the computation efficiency. To mitigate these limitations, we propose a novel end-to-end trainable framework named semantic reasoning network (SRN) for accurate scene text recognition, where a global semantic reasoning module (GSRM) is introduced to capture global semantic context through multi-way parallel transmission. The state-of-the-art results on 7 public benchmarks, including regular text, irregular text and non-Latin long text, verify the effectiveness and robustness of the proposed method. In addition, the speed of SRN has significant advantages over the RNN based methods, demonstrating its value in practical use.
HAMBox: Delving into Online High-quality Anchors Mining for Detecting Outer Faces
Dec 19, 2019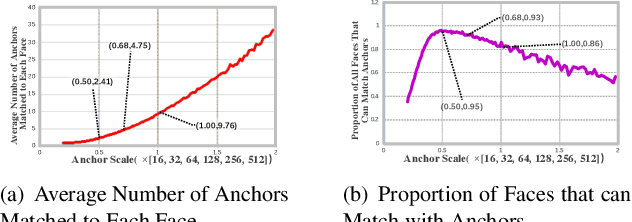
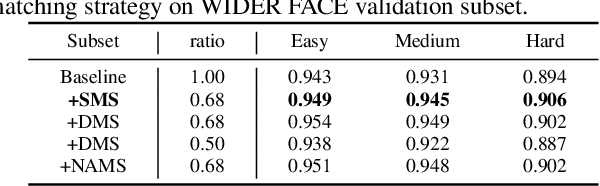
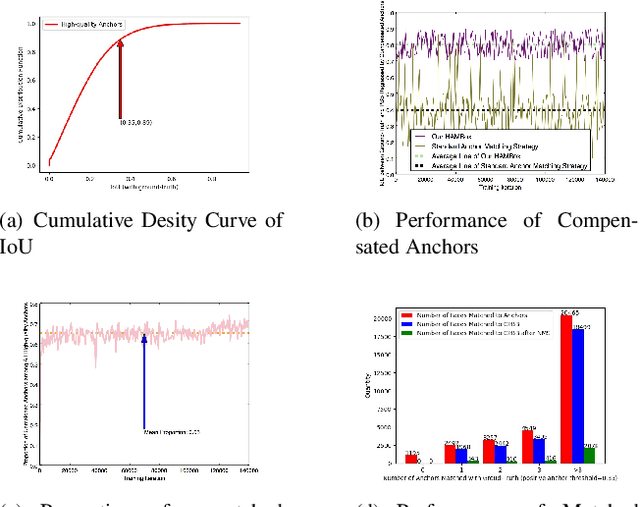
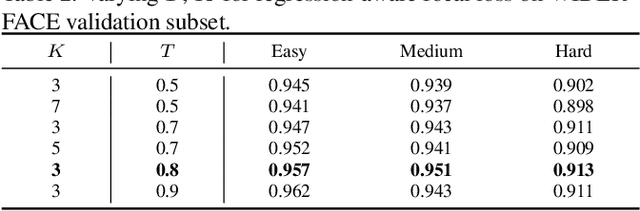
Current face detectors utilize anchors to frame a multi-task learning problem which combines classification and bounding box regression. Effective anchor design and anchor matching strategy enable face detectors to localize faces under large pose and scale variations. However, we observe that more than 80% correctly predicted bounding boxes are regressed from the unmatched anchors (the IoUs between anchors and target faces are lower than a threshold) in the inference phase. It indicates that these unmatched anchors perform excellent regression ability, but the existing methods neglect to learn from them. In this paper, we propose an Online High-quality Anchor Mining Strategy (HAMBox), which explicitly helps outer faces compensate with high-quality anchors. Our proposed HAMBox method could be a general strategy for anchor-based single-stage face detection. Experiments on various datasets, including WIDER FACE, FDDB, AFW and PASCAL Face, demonstrate the superiority of the proposed method. Furthermore, our team win the championship on the Face Detection test track of WIDER Face and Pedestrian Challenge 2019. We will release the codes with PaddlePaddle.
ACFNet: Attentional Class Feature Network for Semantic Segmentation
Oct 18, 2019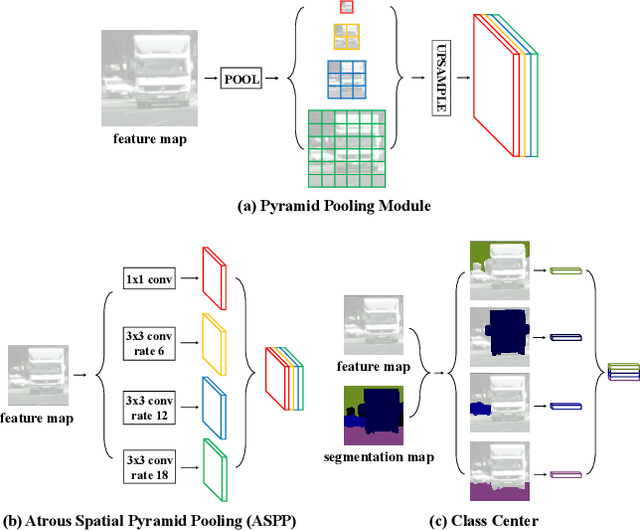
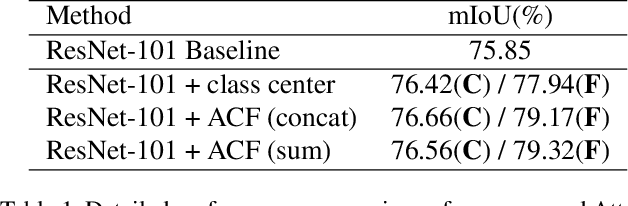
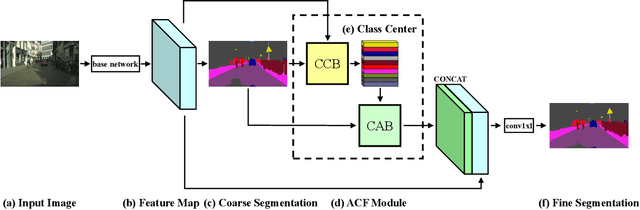
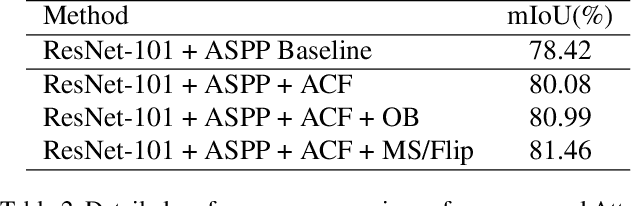
Recent works have made great progress in semantic segmentation by exploiting richer context, most of which are designed from a spatial perspective. In contrast to previous works, we present the concept of class center which extracts the global context from a categorical perspective. This class-level context describes the overall representation of each class in an image. We further propose a novel module, named Attentional Class Feature (ACF) module, to calculate and adaptively combine different class centers according to each pixel. Based on the ACF module, we introduce a coarse-to-fine segmentation network, called Attentional Class Feature Network (ACFNet), which can be composed of an ACF module and any off-the-shell segmentation network (base network). In this paper, we use two types of base networks to evaluate the effectiveness of ACFNet. We achieve new state-of-the-art performance of 81.85% mIoU on Cityscapes dataset with only finely annotated data used for training.
EATEN: Entity-aware Attention for Single Shot Visual Text Extraction
Sep 20, 2019



Extracting entity from images is a crucial part of many OCR applications, such as entity recognition of cards, invoices, and receipts. Most of the existing works employ classical detection and recognition paradigm. This paper proposes an Entity-aware Attention Text Extraction Network called EATEN, which is an end-to-end trainable system to extract the entities without any post-processing. In the proposed framework, each entity is parsed by its corresponding entity-aware decoder, respectively. Moreover, we innovatively introduce a state transition mechanism which further improves the robustness of entity extraction. In consideration of the absence of public benchmarks, we construct a dataset of almost 0.6 million images in three real-world scenarios (train ticket, passport and business card), which is publicly available at https://github.com/beacandler/EATEN. To the best of our knowledge, EATEN is the first single shot method to extract entities from images. Extensive experiments on these benchmarks demonstrate the state-of-the-art performance of EATEN.
Chinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning
Sep 17, 2019
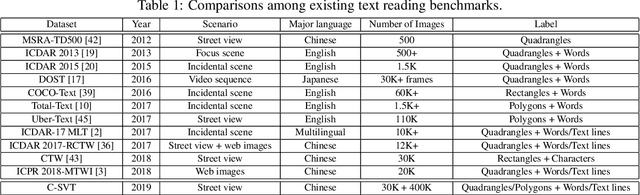

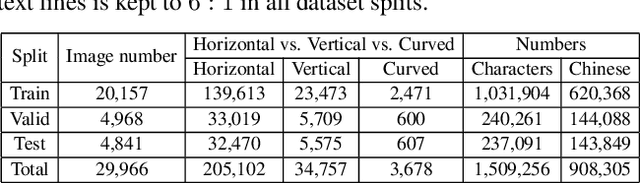
Most existing text reading benchmarks make it difficult to evaluate the performance of more advanced deep learning models in large vocabularies due to the limited amount of training data. To address this issue, we introduce a new large-scale text reading benchmark dataset named Chinese Street View Text (C-SVT) with 430,000 street view images, which is at least 14 times as large as the existing Chinese text reading benchmarks. To recognize Chinese text in the wild while keeping large-scale datasets labeling cost-effective, we propose to annotate one part of the CSVT dataset (30,000 images) in locations and text labels as full annotations and add 400,000 more images, where only the corresponding text-of-interest in the regions is given as weak annotations. To exploit the rich information from the weakly annotated data, we design a text reading network in a partially supervised learning framework, which enables to localize and recognize text, learn from fully and weakly annotated data simultaneously. To localize the best matched text proposals from weakly labeled images, we propose an online proposal matching module incorporated in the whole model, spotting the keyword regions by sharing parameters for end-to-end training. Compared with fully supervised training algorithms, this model can improve the end-to-end recognition performance remarkably by 4.03% in F-score at the same labeling cost. The proposed model can also achieve state-of-the-art results on the ICDAR 2017-RCTW dataset, which demonstrates the effectiveness of the proposed partially supervised learning framework.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


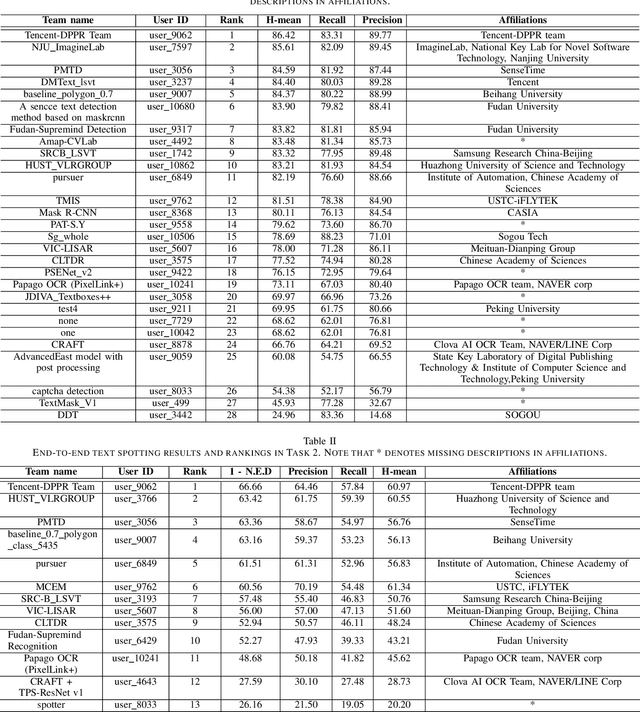
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.