 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Guided Multimodal Learning for Vocal Tract Segmentation in Real-Time MRI
May 18, 2026Segmenting vocal tract articulators in real-time MRI (rtMRI) is a challenging dynamic image segmentation problem characterized by low contrast, rapid motion, and limited spatial resolution. However, while rtMRI acquisitions may provide synchronized acoustic signals, existing methods discard this information, and the few multimodal approaches that incorporate audio cannot be deployed when audio is unavailable. We propose a three-stage framework that leverages acoustic and phonological supervision during training while requiring only the rtMRI image at inference: phonological representations are converted into spatial bounding-box priors for articulator localization, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and the learned representations are fused through a cross-attention decoder, effectively transferring multimodal knowledge into a single-modality inference pipeline. Evaluated on 75-Speaker~Annot-16 and USC-TIMIT datasets, our method outperforms existing unimodal and multimodal methods, demonstrating that multimodal supervision provides transferable benefits for precise and clinically deployable vocal tract segmentation.
LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment: Methods and Results
Apr 13, 2026This paper reviews the LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment. This challenge aims to raise a new direction, i.e., how to evaluate the loss of semantic information from the human perspective, intending to promote the development of some new directions, like semantic coding, processing, and semantic-oriented optimization, etc. Unlike existing datasets of quality assessment, we form a dataset of human-oriented semantic quality assessment, termed the SeIQA dataset. This dataset is divided into three parts for this competition: (i) training data: 510 pairs of degraded images and their corresponding ground truth references; (ii) validation data: 80 pairs of degraded images and their corresponding ground-truth references; (iii) testing data: 160 pairs of degraded images and their corresponding ground-truth references. The primary objective of this challenge is to establish a new and powerful benchmark for human-oriented semantic image quality assessment. There are a total of 58 teams registered in this competition, and 6 teams submitted valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the SeIQA dataset.
An update to PYRO-NN: A Python Library for Differentiable CT Operators
Nov 11, 2025Deep learning has brought significant advancements to X-ray Computed Tomography (CT) reconstruction, offering solutions to challenges arising from modern imaging technologies. These developments benefit from methods that combine classical reconstruction techniques with data-driven approaches. Differentiable operators play a key role in this integration by enabling end-to-end optimization and the incorporation of physical modeling within neural networks. In this work, we present an updated version of PYRO-NN, a Python-based library for differentiable CT reconstruction. The updated framework extends compatibility to PyTorch and introduces native CUDA kernel support for efficient projection and back-projection operations across parallel, fan, and cone-beam geometries. Additionally, it includes tools for simulating imaging artifacts, modeling arbitrary acquisition trajectories, and creating flexible, end-to-end trainable pipelines through a high-level Python API. Code is available at: https://github.com/csyben/PYRO-NN
Learning Wavelet-Sparse FDK for 3D Cone-Beam CT Reconstruction
May 19, 2025Cone-Beam Computed Tomography (CBCT) is essential in medical imaging, and the Feldkamp-Davis-Kress (FDK) algorithm is a popular choice for reconstruction due to its efficiency. However, FDK is susceptible to noise and artifacts. While recent deep learning methods offer improved image quality, they often increase computational complexity and lack the interpretability of traditional methods. In this paper, we introduce an enhanced FDK-based neural network that maintains the classical algorithm's interpretability by selectively integrating trainable elements into the cosine weighting and filtering stages. Recognizing the challenge of a large parameter space inherent in 3D CBCT data, we leverage wavelet transformations to create sparse representations of the cosine weights and filters. This strategic sparsification reduces the parameter count by $93.75\%$ without compromising performance, accelerates convergence, and importantly, maintains the inference computational cost equivalent to the classical FDK algorithm. Our method not only ensures volumetric consistency and boosts robustness to noise, but is also designed for straightforward integration into existing CT reconstruction pipelines. This presents a pragmatic enhancement that can benefit clinical applications, particularly in environments with computational limitations.
Filter2Noise: Interpretable Self-Supervised Single-Image Denoising for Low-Dose CT with Attention-Guided Bilateral Filtering
Apr 18, 2025Effective denoising is crucial in low-dose CT to enhance subtle structures and low-contrast lesions while preventing diagnostic errors. Supervised methods struggle with limited paired datasets, and self-supervised approaches often require multiple noisy images and rely on deep networks like U-Net, offering little insight into the denoising mechanism. To address these challenges, we propose an interpretable self-supervised single-image denoising framework -- Filter2Noise (F2N). Our approach introduces an Attention-Guided Bilateral Filter that adapted to each noisy input through a lightweight module that predicts spatially varying filter parameters, which can be visualized and adjusted post-training for user-controlled denoising in specific regions of interest. To enable single-image training, we introduce a novel downsampling shuffle strategy with a new self-supervised loss function that extends the concept of Noise2Noise to a single image and addresses spatially correlated noise. On the Mayo Clinic 2016 low-dose CT dataset, F2N outperforms the leading self-supervised single-image method (ZS-N2N) by 4.59 dB PSNR while improving transparency, user control, and parametric efficiency. These features provide key advantages for medical applications that require precise and interpretable noise reduction. Our code is demonstrated at https://github.com/sypsyp97/Filter2Noise.git .
seg2med: a segmentation-based medical image generation framework using denoising diffusion probabilistic models
Apr 12, 2025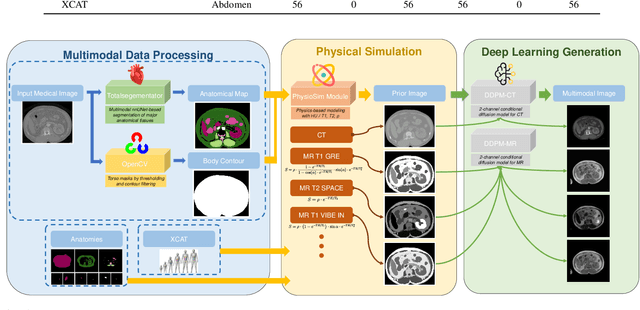
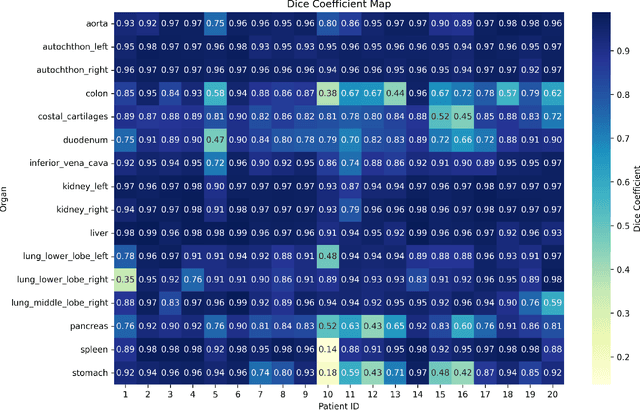
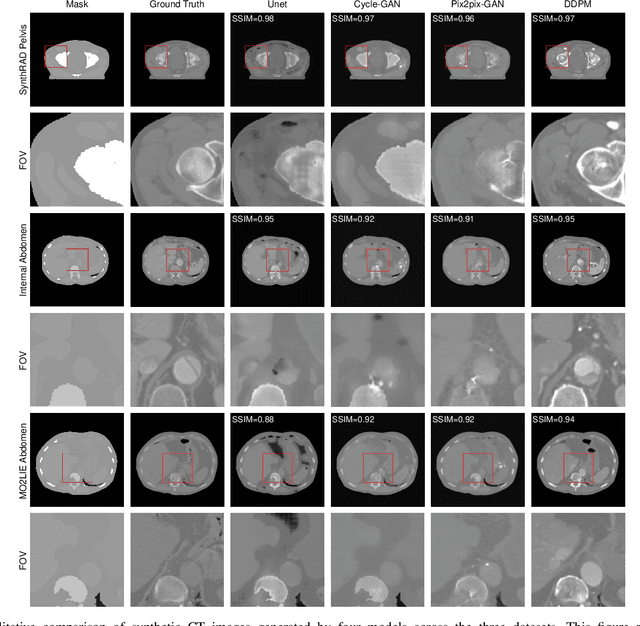
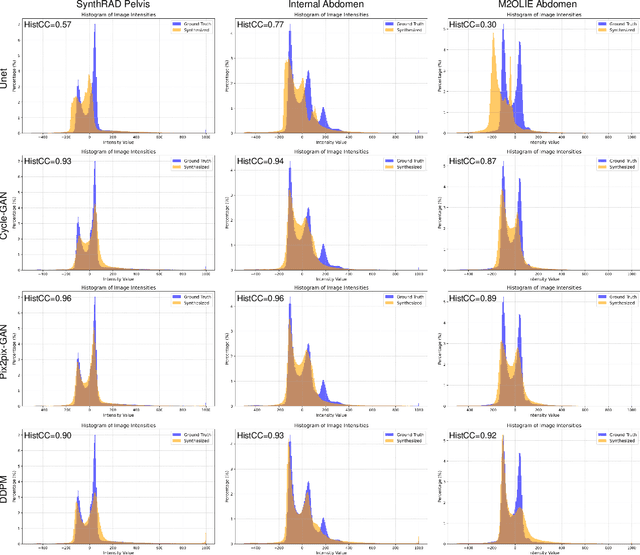
In this study, we present seg2med, an advanced medical image synthesis framework that uses Denoising Diffusion Probabilistic Models (DDPM) to generate high-quality synthetic medical images conditioned on anatomical masks from TotalSegmentator. The framework synthesizes CT and MR images from segmentation masks derived from real patient data and XCAT digital phantoms, achieving a Structural Similarity Index Measure (SSIM) of 0.94 +/- 0.02 for CT and 0.89 +/- 0.04 for MR images compared to ground-truth images of real patients. It also achieves a Feature Similarity Index Measure (FSIM) of 0.78 +/- 0.04 for CT images from XCAT. The generative quality is further supported by a Fr\'echet Inception Distance (FID) of 3.62 for CT image generation. Additionally, seg2med can generate paired CT and MR images with consistent anatomical structures and convert images between CT and MR modalities, achieving SSIM values of 0.91 +/- 0.03 for MR-to-CT and 0.77 +/- 0.04 for CT-to-MR conversion. Despite the limitations of incomplete anatomical details in segmentation masks, the framework shows strong performance in cross-modality synthesis and multimodal imaging. seg2med also demonstrates high anatomical fidelity in CT synthesis, achieving a mean Dice coefficient greater than 0.90 for 11 abdominal organs and greater than 0.80 for 34 organs out of 59 in 58 test cases. The highest Dice of 0.96 +/- 0.01 was recorded for the right scapula. Leveraging the TotalSegmentator toolkit, seg2med enables segmentation mask generation across diverse datasets, supporting applications in clinical imaging, data augmentation, multimodal synthesis, and diagnostic algorithm development.
Compressibility Analysis for the differentiable shift-variant Filtered Backprojection Model
Jan 20, 2025



The differentiable shift-variant filtered backprojection (FBP) model enables the reconstruction of cone-beam computed tomography (CBCT) data for any non-circular trajectories. This method employs deep learning technique to estimate the redundancy weights required for reconstruction, given knowledge of the specific trajectory at optimization time. However, computing the redundancy weight for each projection remains computationally intensive. This paper presents a novel approach to compress and optimize the differentiable shift-variant FBP model based on Principal Component Analysis (PCA). We apply PCA to the redundancy weights learned from sinusoidal trajectory projection data, revealing significant parameter redundancy in the original model. By integrating PCA directly into the differentiable shift-variant FBP reconstruction pipeline, we develop a method that decomposes the redundancy weight layer parameters into a trainable eigenvector matrix, compressed weights, and a mean vector. This innovative technique achieves a remarkable 97.25% reduction in trainable parameters without compromising reconstruction accuracy. As a result, our algorithm significantly decreases the complexity of the differentiable shift-variant FBP model and greatly improves training speed. These improvements make the model substantially more practical for real-world applications.
DRACO: Differentiable Reconstruction for Arbitrary CBCT Orbits
Oct 18, 2024



This paper introduces a novel method for reconstructing cone beam computed tomography (CBCT) images for arbitrary orbits using a differentiable shift-variant filtered backprojection (FBP) neural network. Traditional CBCT reconstruction methods for arbitrary orbits, like iterative reconstruction algorithms, are computationally expensive and memory-intensive. The proposed method addresses these challenges by employing a shift-variant FBP algorithm optimized for arbitrary trajectories through a deep learning approach that adapts to a specific orbit geometry. This approach overcomes the limitations of existing techniques by integrating known operators into the learning model, minimizing the number of parameters, and improving the interpretability of the model. The proposed method is a significant advancement in interventional medical imaging, particularly for robotic C-arm CT systems, enabling faster and more accurate CBCT reconstructions with customized orbits. Especially this method can also be used for the analytical reconstruction of non-continuous orbits like circular plus arc. The experimental results demonstrate that the proposed method significantly accelerates the reconstruction process compared to conventional iterative algorithms. It achieves comparable or superior image quality, as evidenced by metrics such as the mean squared error (MSE), the peak signal-to-noise ratio (PSNR), and the structural similarity index measure (SSIM). The validation experiments show that the method can handle data from different trajectories, demonstrating its flexibility and robustness across different scan geometries. Our method demonstrates a significant improvement, particularly for the sinusoidal trajectory, achieving a 38.6% reduction in MSE, a 7.7% increase in PSNR, and a 5.0% improvement in SSIM. Furthermore, the computation time for reconstruction was reduced by more than 97%.
Reference-Free Multi-Modality Volume Registration of X-Ray Microscopy and Light-Sheet Fluorescence Microscopy
Apr 23, 2024


Recently, X-ray microscopy (XRM) and light-sheet fluorescence microscopy (LSFM) have emerged as two pivotal imaging tools in preclinical research on bone remodeling diseases, offering micrometer-level resolution. Integrating these complementary modalities provides a holistic view of bone microstructures, facilitating function-oriented volume analysis across different disease cycles. However, registering such independently acquired large-scale volumes is extremely challenging under real and reference-free scenarios. This paper presents a fast two-stage pipeline for volume registration of XRM and LSFM. The first stage extracts the surface features and employs two successive point cloud-based methods for coarse alignment. The second stage fine-tunes the initial alignment using a modified cross-correlation method, ensuring precise volumetric registration. Moreover, we propose residual similarity as a novel metric to assess the alignment of two complementary modalities. The results imply robust gradual improvement across the stages. In the end, all correlating microstructures, particularly lacunae in XRM and bone cells in LSFM, are precisely matched, enabling new insights into bone diseases like osteoporosis which are a substantial burden in aging societies.
Segmentation-Guided Knee Radiograph Generation using Conditional Diffusion Models
Apr 04, 2024



Deep learning-based medical image processing algorithms require representative data during development. In particular, surgical data might be difficult to obtain, and high-quality public datasets are limited. To overcome this limitation and augment datasets, a widely adopted solution is the generation of synthetic images. In this work, we employ conditional diffusion models to generate knee radiographs from contour and bone segmentations. Remarkably, two distinct strategies are presented by incorporating the segmentation as a condition into the sampling and training process, namely, conditional sampling and conditional training. The results demonstrate that both methods can generate realistic images while adhering to the conditioning segmentation. The conditional training method outperforms the conditional sampling method and the conventional U-Net.