 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Specialization: Rare Token Neurons in Language Models
May 19, 2025Large language models struggle with representing and generating rare tokens despite their importance in specialized domains. In this study, we identify neuron structures with exceptionally strong influence on language model's prediction of rare tokens, termed as rare token neurons, and investigate the mechanism for their emergence and behavior. These neurons exhibit a characteristic three-phase organization (plateau, power-law, and rapid decay) that emerges dynamically during training, evolving from a homogeneous initial state to a functionally differentiated architecture. In the activation space, rare token neurons form a coordinated subnetwork that selectively co-activates while avoiding co-activation with other neurons. This functional specialization potentially correlates with the development of heavy-tailed weight distributions, suggesting a statistical mechanical basis for emergent specialization.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
Unveiling Knowledge Utilization Mechanisms in LLM-based Retrieval-Augmented Generation
May 17, 2025
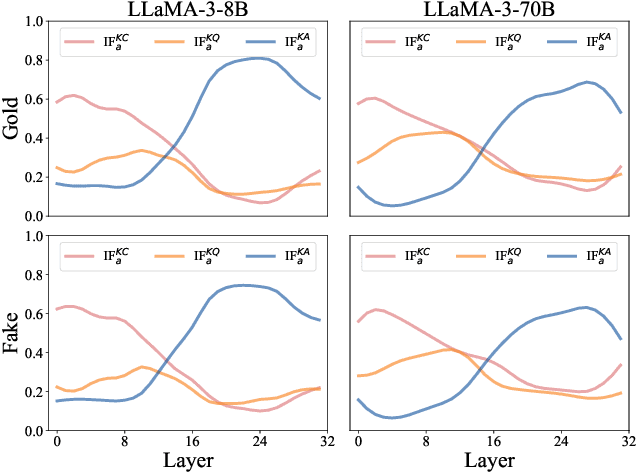
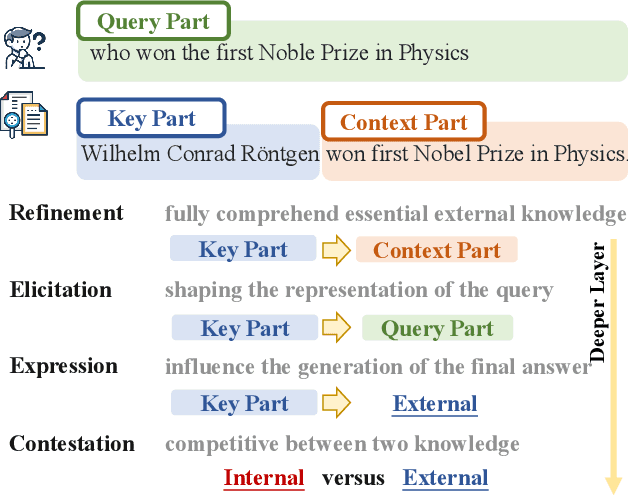
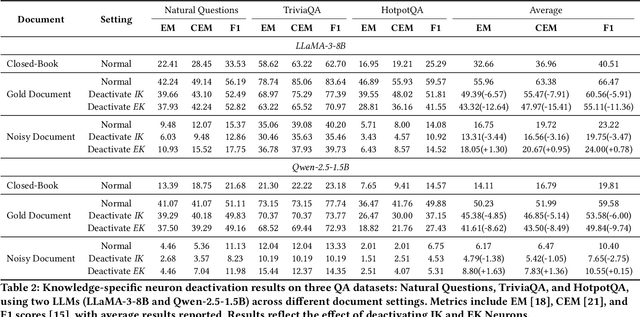
Considering the inherent limitations of parametric knowledge in large language models (LLMs), retrieval-augmented generation (RAG) is widely employed to expand their knowledge scope. Since RAG has shown promise in knowledge-intensive tasks like open-domain question answering, its broader application to complex tasks and intelligent assistants has further advanced its utility. Despite this progress, the underlying knowledge utilization mechanisms of LLM-based RAG remain underexplored. In this paper, we present a systematic investigation of the intrinsic mechanisms by which LLMs integrate internal (parametric) and external (retrieved) knowledge in RAG scenarios. Specially, we employ knowledge stream analysis at the macroscopic level, and investigate the function of individual modules at the microscopic level. Drawing on knowledge streaming analyses, we decompose the knowledge utilization process into four distinct stages within LLM layers: knowledge refinement, knowledge elicitation, knowledge expression, and knowledge contestation. We further demonstrate that the relevance of passages guides the streaming of knowledge through these stages. At the module level, we introduce a new method, knowledge activation probability entropy (KAPE) for neuron identification associated with either internal or external knowledge. By selectively deactivating these neurons, we achieve targeted shifts in the LLM's reliance on one knowledge source over the other. Moreover, we discern complementary roles for multi-head attention and multi-layer perceptron layers during knowledge formation. These insights offer a foundation for improving interpretability and reliability in retrieval-augmented LLMs, paving the way for more robust and transparent generative solutions in knowledge-intensive domains.
QVGen: Pushing the Limit of Quantized Video Generative Models
May 16, 2025Video diffusion models (DMs) have enabled high-quality video synthesis. Yet, their substantial computational and memory demands pose serious challenges to real-world deployment, even on high-end GPUs. As a commonly adopted solution, quantization has proven notable success in reducing cost for image DMs, while its direct application to video DMs remains ineffective. In this paper, we present QVGen, a novel quantization-aware training (QAT) framework tailored for high-performance and inference-efficient video DMs under extremely low-bit quantization (e.g., 4-bit or below). We begin with a theoretical analysis demonstrating that reducing the gradient norm is essential to facilitate convergence for QAT. To this end, we introduce auxiliary modules ($\Phi$) to mitigate large quantization errors, leading to significantly enhanced convergence. To eliminate the inference overhead of $\Phi$, we propose a rank-decay strategy that progressively eliminates $\Phi$. Specifically, we repeatedly employ singular value decomposition (SVD) and a proposed rank-based regularization $\mathbf{\gamma}$ to identify and decay low-contributing components. This strategy retains performance while zeroing out inference overhead. Extensive experiments across $4$ state-of-the-art (SOTA) video DMs, with parameter sizes ranging from $1.3$B $\sim14$B, show that QVGen is the first to reach full-precision comparable quality under 4-bit settings. Moreover, it significantly outperforms existing methods. For instance, our 3-bit CogVideoX-2B achieves improvements of $+25.28$ in Dynamic Degree and $+8.43$ in Scene Consistency on VBench.
End-to-End Vision Tokenizer Tuning
May 15, 2025Existing vision tokenization isolates the optimization of vision tokenizers from downstream training, implicitly assuming the visual tokens can generalize well across various tasks, e.g., image generation and visual question answering. The vision tokenizer optimized for low-level reconstruction is agnostic to downstream tasks requiring varied representations and semantics. This decoupled paradigm introduces a critical misalignment: The loss of the vision tokenization can be the representation bottleneck for target tasks. For example, errors in tokenizing text in a given image lead to poor results when recognizing or generating them. To address this, we propose ETT, an end-to-end vision tokenizer tuning approach that enables joint optimization between vision tokenization and target autoregressive tasks. Unlike prior autoregressive models that use only discrete indices from a frozen vision tokenizer, ETT leverages the visual embeddings of the tokenizer codebook, and optimizes the vision tokenizers end-to-end with both reconstruction and caption objectives. ETT can be seamlessly integrated into existing training pipelines with minimal architecture modifications. Our ETT is simple to implement and integrate, without the need to adjust the original codebooks or architectures of the employed large language models. Extensive experiments demonstrate that our proposed end-to-end vision tokenizer tuning unlocks significant performance gains, i.e., 2-6% for multimodal understanding and visual generation tasks compared to frozen tokenizer baselines, while preserving the original reconstruction capability. We hope this very simple and strong method can empower multimodal foundation models besides image generation and understanding.
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
Edge-Cloud Collaborative Computing on Distributed Intelligence and Model Optimization: A Survey
May 03, 2025



Edge-cloud collaborative computing (ECCC) has emerged as a pivotal paradigm for addressing the computational demands of modern intelligent applications, integrating cloud resources with edge devices to enable efficient, low-latency processing. Recent advancements in AI, particularly deep learning and large language models (LLMs), have dramatically enhanced the capabilities of these distributed systems, yet introduce significant challenges in model deployment and resource management. In this survey, we comprehensive examine the intersection of distributed intelligence and model optimization within edge-cloud environments, providing a structured tutorial on fundamental architectures, enabling technologies, and emerging applications. Additionally, we systematically analyze model optimization approaches, including compression, adaptation, and neural architecture search, alongside AI-driven resource management strategies that balance performance, energy efficiency, and latency requirements. We further explore critical aspects of privacy protection and security enhancement within ECCC systems and examines practical deployments through diverse applications, spanning autonomous driving, healthcare, and industrial automation. Performance analysis and benchmarking techniques are also thoroughly explored to establish evaluation standards for these complex systems. Furthermore, the review identifies critical research directions including LLMs deployment, 6G integration, neuromorphic computing, and quantum computing, offering a roadmap for addressing persistent challenges in heterogeneity management, real-time processing, and scalability. By bridging theoretical advancements and practical deployments, this survey offers researchers and practitioners a holistic perspective on leveraging AI to optimize distributed computing environments, fostering innovation in next-generation intelligent systems.
ZipR1: Reinforcing Token Sparsity in MLLMs
Apr 23, 2025Sparse attention mechanisms aim to reduce computational overhead by selectively processing a subset of salient tokens while preserving model performance. Despite the effectiveness of such designs, how to actively encourage token sparsity of well-posed MLLMs remains under-explored, which fundamentally limits the achievable acceleration effect during inference. In this paper, we propose a simple RL-based post-training method named \textbf{ZipR1} that treats the token reduction ratio as the efficiency reward and answer accuracy as the performance reward. In this way, our method can jointly alleviate the computation and memory bottlenecks via directly optimizing the inference-consistent efficiency-performance tradeoff. Experimental results demonstrate that ZipR1 can reduce the token ratio of Qwen2/2.5-VL from 80\% to 25\% with a minimal accuracy reduction on 13 image and video benchmarks.
Image Difference Grounding with Natural Language
Apr 02, 2025Visual grounding (VG) typically focuses on locating regions of interest within an image using natural language, and most existing VG methods are limited to single-image interpretations. This limits their applicability in real-world scenarios like automatic surveillance, where detecting subtle but meaningful visual differences across multiple images is crucial. Besides, previous work on image difference understanding (IDU) has either focused on detecting all change regions without cross-modal text guidance, or on providing coarse-grained descriptions of differences. Therefore, to push towards finer-grained vision-language perception, we propose Image Difference Grounding (IDG), a task designed to precisely localize visual differences based on user instructions. We introduce DiffGround, a large-scale and high-quality dataset for IDG, containing image pairs with diverse visual variations along with instructions querying fine-grained differences. Besides, we present a baseline model for IDG, DiffTracker, which effectively integrates feature differential enhancement and common suppression to precisely locate differences. Experiments on the DiffGround dataset highlight the importance of our IDG dataset in enabling finer-grained IDU. To foster future research, both DiffGround data and DiffTracker model will be publicly released.
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.