 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before Writing: Feature-Level Multi-Objective Optimization for Generative Citation Visibility
Apr 21, 2026Generative answer engines expose content through selective citation rather than ranked retrieval, fundamentally altering how visibility is determined. This shift calls for new optimization methods beyond traditional search engine optimization. Existing generative engine optimization (GEO) approaches primarily rely on token-level text rewriting, offering limited interpretability and weak control over the trade-off between citation visibility and content quality. We propose FeatGEO, a feature-level, multi-objective optimization framework that abstracts webpages into interpretable structural, content, and linguistic properties. Instead of directly editing text, FeatGEO optimizes over this feature space and uses a language model to realize feature configurations into natural language, decoupling high-level optimization from surface-level generation. Experiments on GEO-Bench across three generative engines demonstrate that FeatGEO consistently improves citation visibility while maintaining or improving content quality, substantially outperforming token-level baselines. Further analyses show that citation behavior is more strongly influenced by document-level content properties than by isolated lexical edits, and that the learned feature configurations generalize across language models of different scales.
Towards Long-horizon Agentic Multimodal Search
Apr 14, 2026Multimodal deep search agents have shown great potential in solving complex tasks by iteratively collecting textual and visual evidence. However, managing the heterogeneous information and high token costs associated with multimodal inputs over long horizons remains a critical challenge, as existing methods often suffer from context explosion or the loss of crucial visual signals. To address this, we propose a novel Long-horizon MultiModal deep search framework, named LMM-Searcher, centered on a file-based visual representation mechanism. By offloading visual assets to an external file system and mapping them to lightweight textual identifiers (UIDs), our approach mitigates context overhead while preserving multimodal information for future access. We equip the agent with a tailored fetch-image tool, enabling a progressive, on-demand visual loading strategy for active perception. Furthermore, we introduce a data synthesis pipeline designed to generate queries requiring complex cross-modal multi-hop reasoning. Using this pipeline, we distill 12K high-quality trajectories to fine-tune Qwen3-VL-Thinking-30A3B into a specialized multimodal deep search agent. Extensive experiments across four benchmarks demonstrate that our method successfully scales to 100-turn search horizons, achieving state-of-the-art performance among open-source models on challenging long-horizon benchmarks like MM-BrowseComp and MMSearch-Plus, while also exhibiting strong generalizability across different base models. Our code will be released in https://github.com/RUCAIBox/LMM-Searcher.
AdaSpark: Adaptive Sparsity for Efficient Long-Video Understanding
Apr 09, 2026Processing long-form videos with Video Large Language Models (Video-LLMs) is computationally prohibitive. Current efficiency methods often compromise fine-grained perception through irreversible information disposal or inhibit long-range temporal modeling via rigid, predefined sparse patterns. This paper introduces AdaSpark, an adaptive sparsity framework designed to address these limitations. AdaSpark first partitions video inputs into 3D spatio-temporal cubes. It then employs two co-designed, context-aware components: (1) Adaptive Cube-Selective Attention (AdaS-Attn), which adaptively selects a subset of relevant video cubes to attend for each query token, and (2) Adaptive Token-Selective FFN (AdaS-FFN), which selectively processes only the most salient tokens within each cube. An entropy-based (Top-p) selection mechanism adaptively allocates computational resources based on input complexity. Experiments demonstrate that AdaSpark significantly reduces computational load by up to 57% FLOPs while maintaining comparable performance to dense models and preserving fine-grained, long-range dependencies, as validated on challenging hour-scale video benchmarks.
Thinking in Streaming Video
Mar 13, 2026Real-time understanding of continuous video streams is essential for interactive assistants and multimodal agents operating in dynamic environments. However, most existing video reasoning approaches follow a batch paradigm that defers reasoning until the full video context is observed, resulting in high latency and growing computational cost that are incompatible with streaming scenarios. In this paper, we introduce ThinkStream, a framework for streaming video reasoning based on a Watch--Think--Speak paradigm that enables models to incrementally update their understanding as new video observations arrive. At each step, the model performs a short reasoning update and decides whether sufficient evidence has accumulated to produce a response. To support long-horizon streaming, we propose Reasoning-Compressed Streaming Memory (RCSM), which treats intermediate reasoning traces as compact semantic memory that replaces outdated visual tokens while preserving essential context. We further train the model using a Streaming Reinforcement Learning with Verifiable Rewards scheme that aligns incremental reasoning and response timing with the requirements of streaming interaction. Experiments on multiple streaming video benchmarks show that ThinkStream significantly outperforms existing online video models while maintaining low latency and memory usage. Code, models and data will be released at https://github.com/johncaged/ThinkStream
VIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025


Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Improving Phishing Email Detection Performance of Small Large Language Models
Apr 29, 2025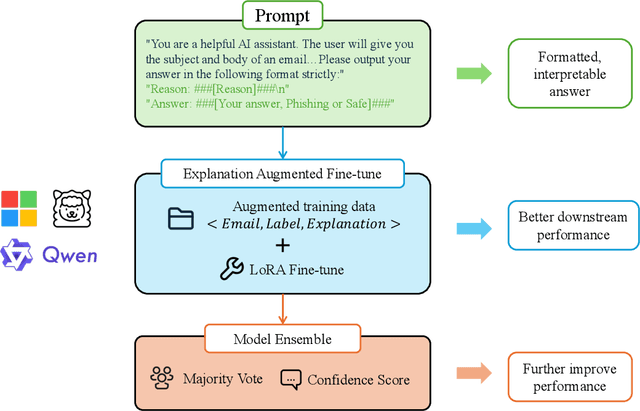
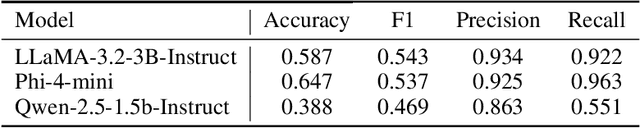
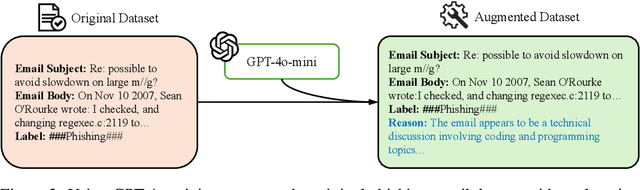
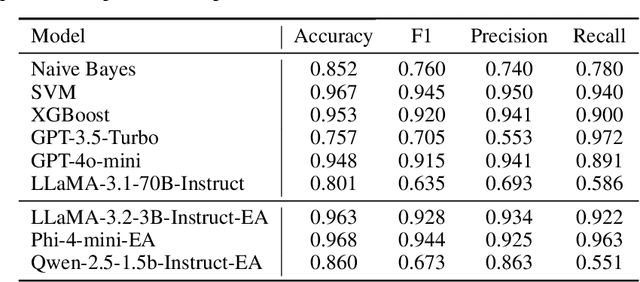
Large language models(LLMs) have demonstrated remarkable performance on many natural language processing(NLP) tasks and have been employed in phishing email detection research. However, in current studies, well-performing LLMs typically contain billions or even tens of billions of parameters, requiring enormous computational resources. To reduce computational costs, we investigated the effectiveness of small-parameter LLMs for phishing email detection. These LLMs have around 3 billion parameters and can run on consumer-grade GPUs. However, small LLMs often perform poorly in phishing email detection task. To address these issues, we designed a set of methods including Prompt Engineering, Explanation Augmented Fine-tuning, and Model Ensemble to improve phishing email detection capabilities of small LLMs. We validated the effectiveness of our approach through experiments, significantly improving accuracy on the SpamAssassin dataset from around 0.5 for baseline models like Qwen2.5-1.5B-Instruct to 0.976.
Do we Really Need Visual Instructions? Towards Visual Instruction-Free Fine-tuning for Large Vision-Language Models
Feb 17, 2025



Visual instruction tuning has become the predominant technology in eliciting the multimodal task-solving capabilities of large vision-language models (LVLMs). Despite the success, as visual instructions require images as the input, it would leave the gap in inheriting the task-solving capabilities from the backbone LLMs, and make it costly to collect a large-scale dataset. To address it, we propose ViFT, a visual instruction-free fine-tuning framework for LVLMs. In ViFT, we only require the text-only instructions and image caption data during training, to separately learn the task-solving and visual perception abilities. During inference, we extract and combine the representations of the text and image inputs, for fusing the two abilities to fulfill multimodal tasks. Experimental results demonstrate that ViFT can achieve state-of-the-art performance on several visual reasoning and visual instruction following benchmarks, with rather less training data. Our code and data will be publicly released.
VRoPE: Rotary Position Embedding for Video Large Language Models
Feb 17, 2025Rotary Position Embedding (RoPE) has shown strong performance in text-based Large Language Models (LLMs), but extending it to video remains a challenge due to the intricate spatiotemporal structure of video frames. Existing adaptations, such as RoPE-3D, attempt to encode spatial and temporal dimensions separately but suffer from two major limitations: positional bias in attention distribution and disruptions in video-text transitions. To overcome these issues, we propose Video Rotary Position Embedding (VRoPE), a novel positional encoding method tailored for Video-LLMs. Our approach restructures positional indices to preserve spatial coherence and ensure a smooth transition between video and text tokens. Additionally, we introduce a more balanced encoding strategy that mitigates attention biases, ensuring a more uniform distribution of spatial focus. Extensive experiments on Vicuna and Qwen2 across different model scales demonstrate that VRoPE consistently outperforms previous RoPE variants, achieving significant improvements in video understanding, temporal reasoning, and retrieval tasks. Code will be available at https://github.com/johncaged/VRoPE
Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
Jan 03, 2025Recently, slow-thinking reasoning systems, built upon large language models (LLMs), have garnered widespread attention by scaling the thinking time during inference. There is also growing interest in adapting this capability to multimodal large language models (MLLMs). Given that MLLMs handle more complex data semantics across different modalities, it is intuitively more challenging to implement multimodal slow-thinking systems. To address this issue, in this paper, we explore a straightforward approach by fine-tuning a capable MLLM with a small amount of textual long-form thought data, resulting in a multimodal slow-thinking system, Virgo (Visual reasoning with long thought). We find that these long-form reasoning processes, expressed in natural language, can be effectively transferred to MLLMs. Moreover, it seems that such textual reasoning data can be even more effective than visual reasoning data in eliciting the slow-thinking capacities of MLLMs. While this work is preliminary, it demonstrates that slow-thinking capacities are fundamentally associated with the language model component, which can be transferred across modalities or domains. This finding can be leveraged to guide the development of more powerful slow-thinking reasoning systems. We release our resources at https://github.com/RUCAIBox/Virgo.