 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025


Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
Uniqueness of phase retrieval from offset linear canonical transform
Jun 04, 2025The classical phase retrieval refers to the recovery of an unknown signal from its Fourier magnitudes, which is widely used in fields such as quantum mechanics, signal processing, optics, etc. The offset linear canonical transform (OLCT), which is a more general type of linear integral transform including Fourier transform (FT), fractional Fourier transform (FrFT), and linear canonical transform (LCT) as its special cases. Hence, in this paper, we focus on the uniqueness problem of phase retrieval in the framework of OLCT. First, we prove that all the nontrivial ambiguities in continuous OLCT phase retrieval can be represented by convolution operators, and demonstrate that a continuous compactly supported signal can be uniquely determined up to a global phase from its multiple magnitude-only OLCT measurements. Moreover, we investigate the nontrivial ambiguities in the discrete OLCT phase retrieval case. Furthermore, we demenstrate that a nonseparable function can be uniquely recovered from its magnitudes of short-time OLCT (STOLCT) up to a global phase. Finally, we show that signals which are bandlimited in FT or OLCT domain can be reconstructed from its sampled STOLCT magnitude measurements, up to a global phase, providing the ambiguity function of window function satisfies some mild conditions.
Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
May 27, 2025Long-form question answering (LFQA) presents unique challenges for large language models, requiring the synthesis of coherent, paragraph-length answers. While retrieval-augmented generation (RAG) systems have emerged as a promising solution, existing research struggles with key limitations: the scarcity of high-quality training data for long-form generation, the compounding risk of hallucination in extended outputs, and the absence of reliable evaluation metrics for factual completeness. In this paper, we propose RioRAG, a novel reinforcement learning (RL) framework that advances long-form RAG through reinforced informativeness optimization. Our approach introduces two fundamental innovations to address the core challenges. First, we develop an RL training paradigm of reinforced informativeness optimization that directly optimizes informativeness and effectively addresses the slow-thinking deficit in conventional RAG systems, bypassing the need for expensive supervised data. Second, we propose a nugget-centric hierarchical reward modeling approach that enables precise assessment of long-form answers through a three-stage process: extracting the nugget from every source webpage, constructing a nugget claim checklist, and computing rewards based on factual alignment. Extensive experiments on two LFQA benchmarks LongFact and RAGChecker demonstrate the effectiveness of the proposed method. Our codes are available at https://github.com/RUCAIBox/RioRAG.
TuneComp: Joint Fine-tuning and Compression for Large Foundation Models
May 27, 2025



To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine-tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
FT-Boosted SV: Towards Noise Robust Speaker Verification for English Speaking Classroom Environments
May 26, 2025Creating Speaker Verification (SV) systems for classroom settings that are robust to classroom noises such as babble noise is crucial for the development of AI tools that assist educational environments. In this work, we study the efficacy of finetuning with augmented children datasets to adapt the x-vector and ECAPA-TDNN to classroom environments. We demonstrate that finetuning with augmented children's datasets is powerful in that regard and reduces the Equal Error Rate (EER) of x-vector and ECAPA-TDNN models for both classroom datasets and children speech datasets. Notably, this method reduces EER of the ECAPA-TDNN model on average by half (a 5 % improvement) for classrooms in the MPT dataset compared to the ECAPA-TDNN baseline model. The x-vector model shows an 8 % average improvement for classrooms in the NCTE dataset compared to its baseline.
Context-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
$μ$-MoE: Test-Time Pruning as Micro-Grained Mixture-of-Experts
May 24, 2025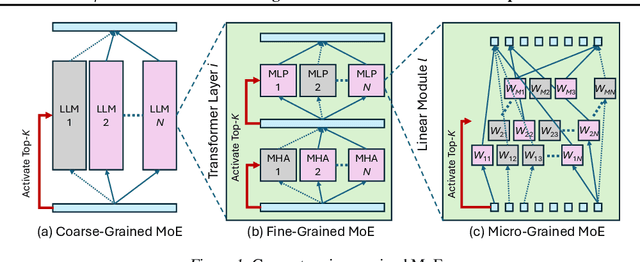
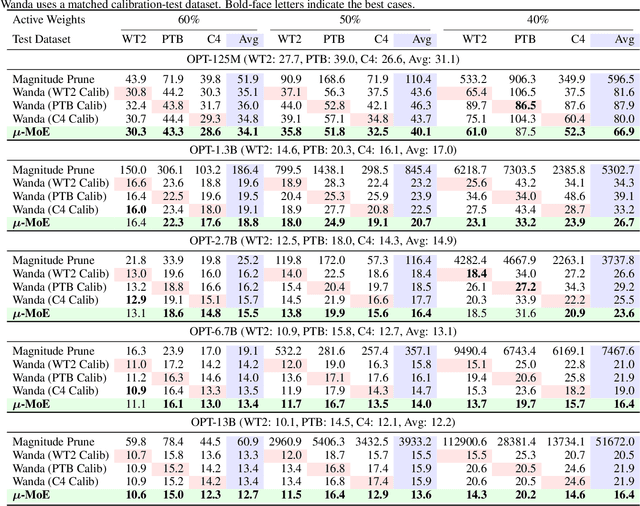
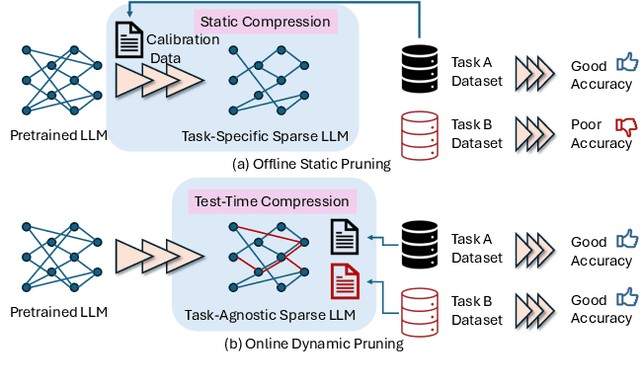
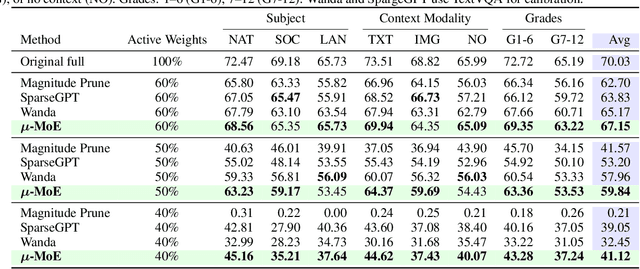
To tackle the huge computational demand of large foundation models, activation-aware compression techniques without retraining have been introduced. However, since these rely on calibration data, domain shift may arise for unknown downstream tasks. With a computationally efficient calibration, activation-aware pruning can be executed for every prompt adaptively, yet achieving reduced complexity at inference. We formulate it as a mixture of micro-experts, called $\mu$-MoE. Several experiments demonstrate that $\mu$-MoE can dynamically adapt to task/prompt-dependent structured sparsity on the fly.
LatentLLM: Attention-Aware Joint Tensor Compression
May 23, 2025Modern foundation models such as large language models (LLMs) and large multi-modal models (LMMs) require a massive amount of computational and memory resources. We propose a new framework to convert such LLMs/LMMs into a reduced-dimension latent structure. Our method extends a local activation-aware tensor decomposition to a global attention-aware joint tensor de-composition. Our framework can significantly improve the model accuracy over the existing model compression methods when reducing the latent dimension to realize computationally/memory-efficient LLMs/LLMs. We show the benefit on several benchmark including multi-modal reasoning tasks.
Scaling Law for Quantization-Aware Training
May 20, 2025



Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
From Weak Labels to Strong Results: Utilizing 5,000 Hours of Noisy Classroom Transcripts with Minimal Accurate Data
May 20, 2025Recent progress in speech recognition has relied on models trained on vast amounts of labeled data. However, classroom Automatic Speech Recognition (ASR) faces the real-world challenge of abundant weak transcripts paired with only a small amount of accurate, gold-standard data. In such low-resource settings, high transcription costs make re-transcription impractical. To address this, we ask: what is the best approach when abundant inexpensive weak transcripts coexist with limited gold-standard data, as is the case for classroom speech data? We propose Weakly Supervised Pretraining (WSP), a two-step process where models are first pretrained on weak transcripts in a supervised manner, and then fine-tuned on accurate data. Our results, based on both synthetic and real weak transcripts, show that WSP outperforms alternative methods, establishing it as an effective training methodology for low-resource ASR in real-world scenarios.