Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$-MoE: Test-Time Pruning as Micro-Grained Mixture-of-Experts
Paper and Code
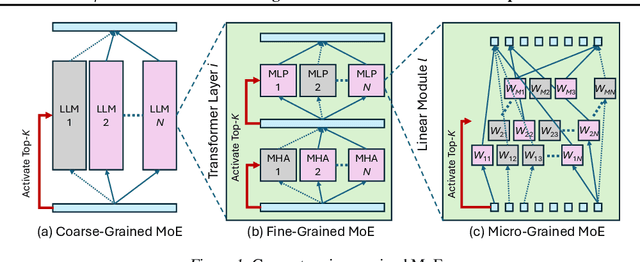
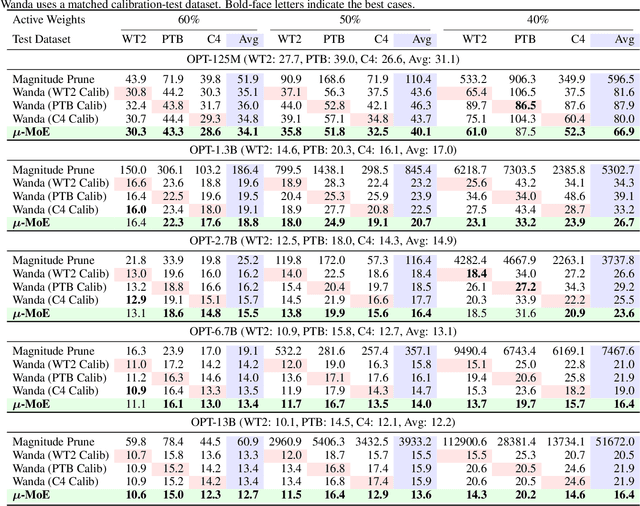
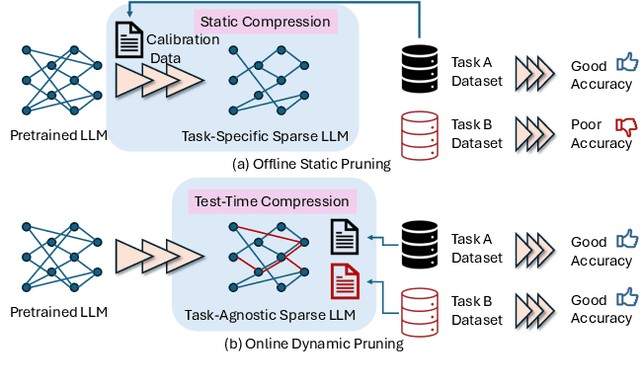
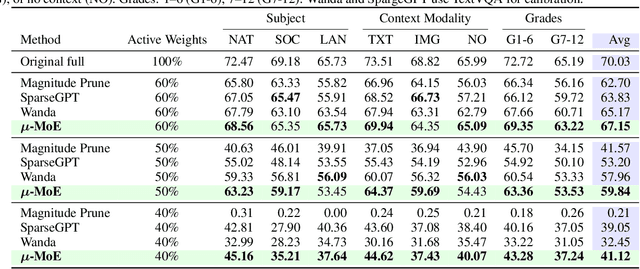
To tackle the huge computational demand of large foundation models, activation-aware compression techniques without retraining have been introduced. However, since these rely on calibration data, domain shift may arise for unknown downstream tasks. With a computationally efficient calibration, activation-aware pruning can be executed for every prompt adaptively, yet achieving reduced complexity at inference. We formulate it as a mixture of micro-experts, called $\mu$-MoE. Several experiments demonstrate that $\mu$-MoE can dynamically adapt to task/prompt-dependent structured sparsity on the fly.
* 10 pages, 4 figures
View paper on