 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCoVLA: VLM-Guided Reward Compilation for Failure Recovery in Vision-Language-Action Policies
Jun 08, 2026Vision-language-action (VLA) policies provide strong priors for language-conditioned manipulation, but remain brittle in off-nominal states requiring targeted recovery. We propose ReCoVLA -- a failure-conditioned residual recovery framework that keeps a pretrained VLA policy frozen, uses an external vision-language model (VLM) to infer the failure mode and recovery stage, and compiles a structured reward from task-relevant components. Rather than using the VLM to generate actions or rewards directly, ReCoVLA uses it as a semantic reward selector: it predicts a recovery descriptor and reward mask for in-simulation residual-policy training, followed by zero-shot sim-to-real deployment of the trained recovery policies. This decouples high-level failure understanding from low-level corrective control to support different VLAs. Experiments across short-horizon, long-horizon, and contact-rich manipulation tasks show that ReCoVLA outperforms the tested baselines on average. In simulation, our reward compiler improves average success from 36.7% for the fine-tuned $π_{0.5}$ baseline to 66.7%. In physical zero-shot sim-to-real experiments, ReCoVLA achieves the best average performance, with 61.7% success.
EinSort: Sorting is All We Need for Tensorizing LLM
Jun 07, 2026Tensor networks provide efficient representations for compressing large neural networks. By carefully designing shapes and topologies, they can significantly reduce memory and computational costs. However, identifying implicit low-rank structures in large foundation models remains challenging due to their enormous scale and un-structured weight distributions. We propose an adaptive tensorization method that discovers inherent low-rank structure in a target tensor by index ordering. Experiments on weight and KV-cache compression demonstrate improved reconstruction quality compared to baselines.
Quantum-Native Maximum Likelihood Detection in Random Access Channel with Overloaded MIMO
May 19, 2026In this paper, we propose a quantum-native formulation of maximum likelihood detection (MLD) for overloaded multiple-input multiple-output (MIMO) systems in a random access channel, where numerous user terminals share the same channel resource and asynchronously transmit signals. Classical linear detectors suffer from significant performance degradation in this scenario, whereas the exhaustive-search MLD achieves the optimal performance but incurs an exponential computational complexity. To overcome this trade-off, we formulate the MLD as a binary optimization problem and solve it via Grover adaptive search (GAS) -- a quantum exhaustive search algorithm offering quadratic speedup in fault-tolerant quantum computing. We then introduce a search space reduction technique to substantially decrease the required computational resources. In addition, we investigate efficient parameter settings for GAS through probability analysis to improve convergence performance. We demonstrate that the proposed detector achieves the optimal detection performance while reducing the required Grover rotation count to reach the solution by up to approximately 65% compared with the conventional GAS, showing its potential as a viable solution for future quantum-accelerated wireless systems.
Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment
May 13, 2026Inference-time alignment techniques offer a lightweight alternative or complement to costly reinforcement learning, while enabling continual adaptation as alignment objectives and reward targets evolve. Existing theoretical analyses justify these methods as approximations to sampling from distributions optimally tilted toward a given reward model. We extend these techniques by introducing reference-model temperature adjustment, which leads to further generalization of inference-time alignment to ensembles of generative reward models combined as a sharpened logarithmic opinion pool (SLOP). To mitigate reward hacking, we propose an algorithm for calibrating SLOP weight parameters and experimentally demonstrate that it improves robustness while preserving alignment performance.
Amplification Effects in Test-Time Reinforcement Learning: Safety and Reasoning Vulnerabilities
Mar 16, 2026Test-time training (TTT) has recently emerged as a promising method to improve the reasoning abilities of large language models (LLMs), in which the model directly learns from test data without access to labels. However, this reliance on test data also makes TTT methods vulnerable to harmful prompt injections. In this paper, we investigate safety vulnerabilities of TTT methods, where we study a representative self-consistency-based test-time learning method: test-time reinforcement learning (TTRL), a recent TTT method that improves LLM reasoning by rewarding self-consistency using majority vote as a reward signal. We show that harmful prompt injection during TTRL amplifies the model's existing behaviors, i.e., safety amplification when the base model is relatively safe, and harmfulness amplification when it is vulnerable to the injected data. In both cases, there is a decline in reasoning ability, which we refer to as the reasoning tax. We also show that TTT methods such as TTRL can be exploited adversarially using specially designed "HarmInject" prompts to force the model to answer jailbreak and reasoning queries together, resulting in stronger harmfulness amplification. Overall, our results highlight that TTT methods that enhance LLM reasoning by promoting self-consistency can lead to amplification behaviors and reasoning degradation, highlighting the need for safer TTT methods.
Directional Embedding Smoothing for Robust Vision Language Models
Mar 16, 2026The safety and reliability of vision-language models (VLMs) are a crucial part of deploying trustworthy agentic AI systems. However, VLMs remain vulnerable to jailbreaking attacks that undermine their safety alignment to yield harmful outputs. In this work, we extend the Randomized Embedding Smoothing and Token Aggregation (RESTA) defense to VLMs and evaluate its performance against the JailBreakV-28K benchmark of multi-modal jailbreaking attacks. We find that RESTA is effective in reducing attack success rate over this diverse corpus of attacks, in particular, when employing directional embedding noise, where the injected noise is aligned with the original token embedding vectors. Our results demonstrate that RESTA can contribute to securing VLMs within agentic systems, as a lightweight, inference-time defense layer of an overall security framework.
Geo-ADAPT-VQE: Quantum Information Metric-Aware Circuit Optimization for Quantum Chemistry
Mar 11, 2026Adaptive ansatz construction has emerged as a powerful technique for reducing circuit depth and improving optimization efficiency in variational quantum eigensolvers. However, existing adaptive methods, including ADAPT-VQE, rely solely on first-order gradients and therefore ignore the underlying geometry of the quantum state space, limiting both convergence behavior and operator-selection efficiency. We introduce Geo-ADAPT-VQE, a geometry-aware adaptive VQE algorithm that selects operators from a pool using the natural gradient rule. The geometric operator-selection rule enables the ansatz to grow along directions aligned with the underlying quantum-state geometry, thereby improving convergence and reducing the algorithm's susceptibility to shallow local minima and saddle-point regions. We further provide an asymptotic convergence result. We present numerical simulations involving five molecules, which demonstrate that Geo-ADAPT-VQE achieves faster and more stable convergence compared to existing methods, while producing significantly shorter ansatz. In particular, Geo-ADAPT achieves up to 100-fold reduction in energy error compared to existing methods.
AWP: Activation-Aware Weight Pruning and Quantization with Projected Gradient Descent
Jun 11, 2025To address the enormous size of Large Language Models (LLMs), model compression methods, such as quantization and pruning, are often deployed, especially on edge devices. In this work, we focus on layer-wise post-training quantization and pruning. Drawing connections between activation-aware weight pruning and sparse approximation problems, and motivated by the success of Iterative Hard Thresholding (IHT), we propose a unified method for Activation-aware Weight pruning and quantization via Projected gradient descent (AWP). Our experiments demonstrate that AWP outperforms state-of-the-art LLM pruning and quantization methods. Theoretical convergence guarantees of the proposed method for pruning are also provided.
TuneComp: Joint Fine-tuning and Compression for Large Foundation Models
May 27, 2025



To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine-tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
$μ$-MoE: Test-Time Pruning as Micro-Grained Mixture-of-Experts
May 24, 2025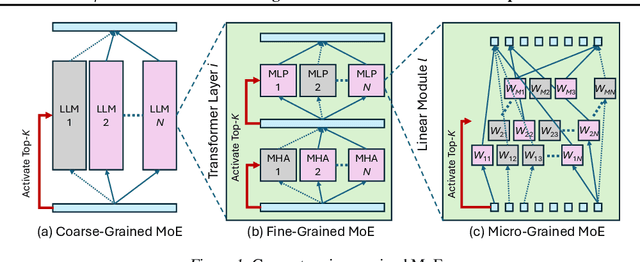
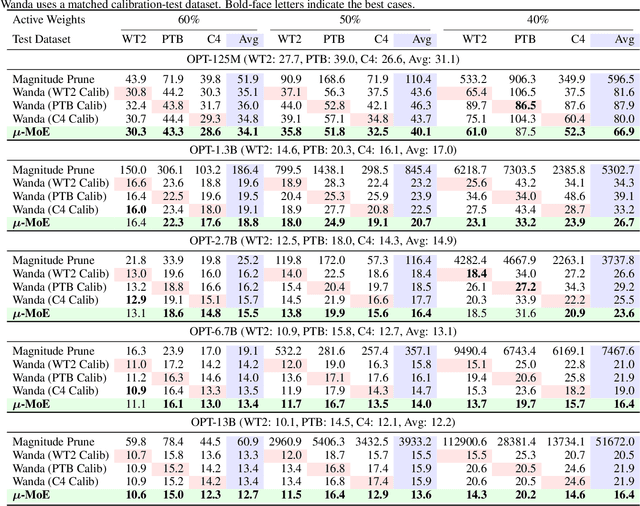
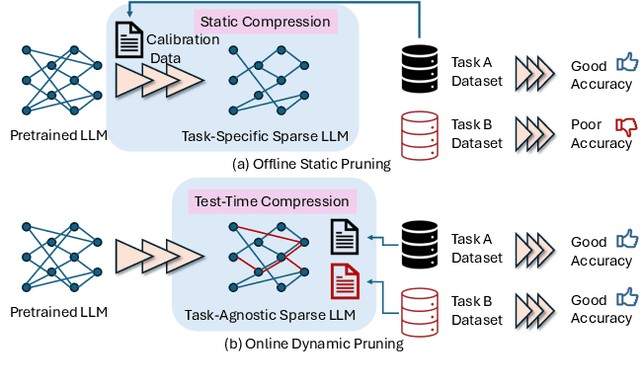
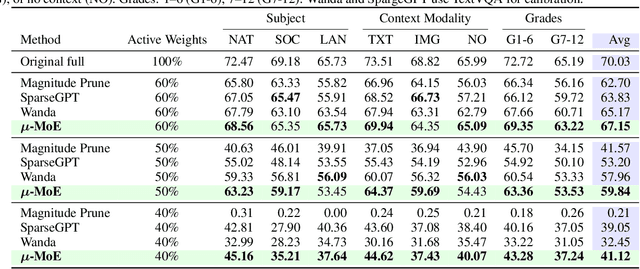
To tackle the huge computational demand of large foundation models, activation-aware compression techniques without retraining have been introduced. However, since these rely on calibration data, domain shift may arise for unknown downstream tasks. With a computationally efficient calibration, activation-aware pruning can be executed for every prompt adaptively, yet achieving reduced complexity at inference. We formulate it as a mixture of micro-experts, called $\mu$-MoE. Several experiments demonstrate that $\mu$-MoE can dynamically adapt to task/prompt-dependent structured sparsity on the fly.