 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact and Human Dynamics from Monocular Video
Jul 24, 2020
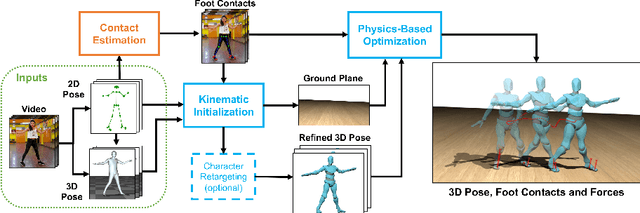

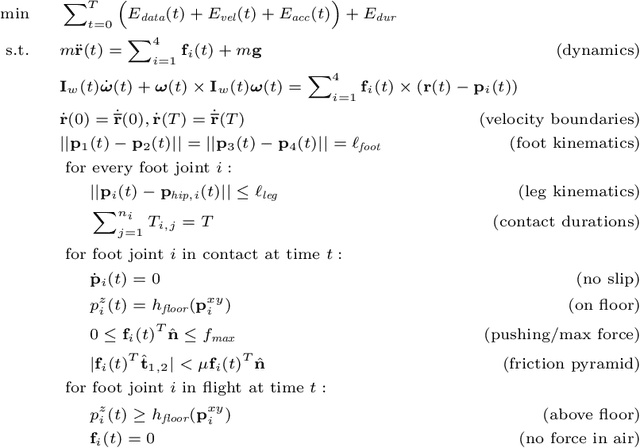
Existing deep models predict 2D and 3D kinematic poses from video that are approximately accurate, but contain visible errors that violate physical constraints, such as feet penetrating the ground and bodies leaning at extreme angles. In this paper, we present a physics-based method for inferring 3D human motion from video sequences that takes initial 2D and 3D pose estimates as input. We first estimate ground contact timings with a novel prediction network which is trained without hand-labeled data. A physics-based trajectory optimization then solves for a physically-plausible motion, based on the inputs. We show this process produces motions that are significantly more realistic than those from purely kinematic methods, substantially improving quantitative measures of both kinematic and dynamic plausibility. We demonstrate our method on character animation and pose estimation tasks on dynamic motions of dancing and sports with complex contact patterns.
Generative Tweening: Long-term Inbetweening of 3D Human Motions
May 28, 2020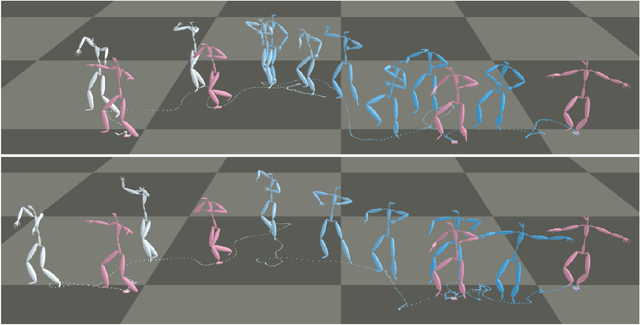
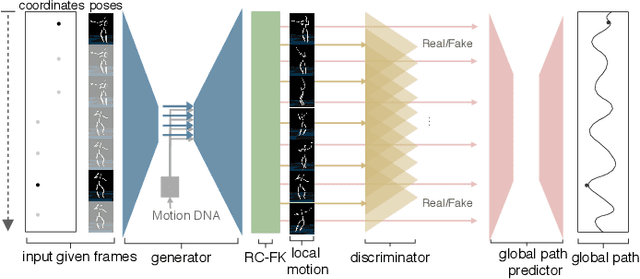

The ability to generate complex and realistic human body animations at scale, while following specific artistic constraints, has been a fundamental goal for the game and animation industry for decades. Popular techniques include key-framing, physics-based simulation, and database methods via motion graphs. Recently, motion generators based on deep learning have been introduced. Although these learning models can automatically generate highly intricate stylized motions of arbitrary length, they still lack user control. To this end, we introduce the problem of long-term inbetweening, which involves automatically synthesizing complex motions over a long time interval given very sparse keyframes by users. We identify a number of challenges related to this problem, including maintaining biomechanical and keyframe constraints, preserving natural motions, and designing the entire motion sequence holistically while considering all constraints. We introduce a biomechanically constrained generative adversarial network that performs long-term inbetweening of human motions, conditioned on keyframe constraints. This network uses a novel two-stage approach where it first predicts local motion in the form of joint angles, and then predicts global motion, i.e. the global path that the character follows. Since there are typically a number of possible motions that could satisfy the given user constraints, we also enable our network to generate a variety of outputs with a scheme that we call Motion DNA. This approach allows the user to manipulate and influence the output content by feeding seed motions (DNA) to the network. Trained with 79 classes of captured motion data, our network performs robustly on a variety of highly complex motion styles.
High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling
May 24, 2020
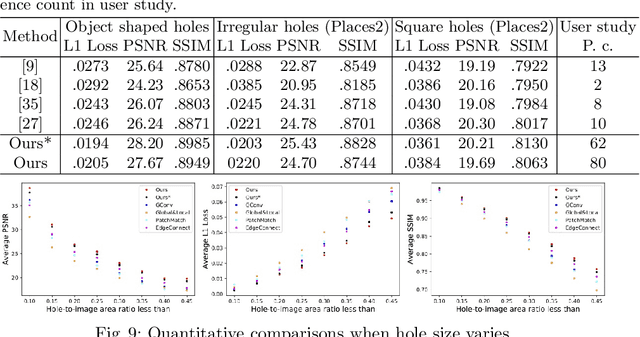

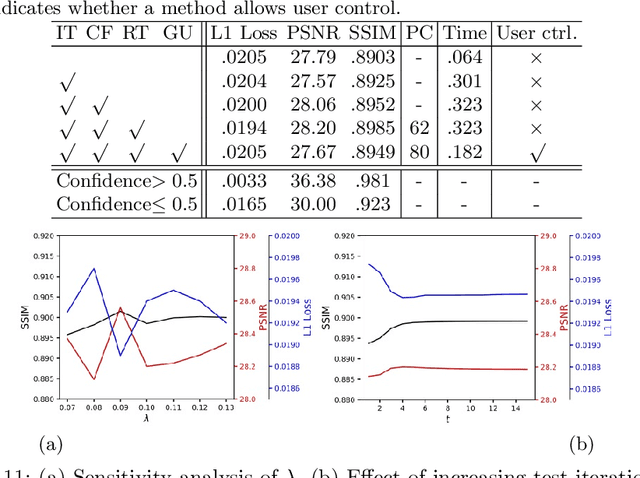
Existing image inpainting methods often produce artifacts when dealing with large holes in real applications. To address this challenge, we propose an iterative inpainting method with a feedback mechanism. Specifically, we introduce a deep generative model which not only outputs an inpainting result but also a corresponding confidence map. Using this map as feedback, it progressively fills the hole by trusting only high-confidence pixels inside the hole at each iteration and focuses on the remaining pixels in the next iteration. As it reuses partial predictions from the previous iterations as known pixels, this process gradually improves the result. In addition, we propose a guided upsampling network to enable generation of high-resolution inpainting results. We achieve this by extending the Contextual Attention module [1] to borrow high-resolution feature patches in the input image. Furthermore, to mimic real object removal scenarios, we collect a large object mask dataset and synthesize more realistic training data that better simulates user inputs. Experiments show that our method significantly outperforms existing methods in both quantitative and qualitative evaluations. More results and Web APP are available at https://zengxianyu.github.io/iic.
FreiHAND: A Dataset for Markerless Capture of Hand Pose and Shape from Single RGB Images
Sep 13, 2019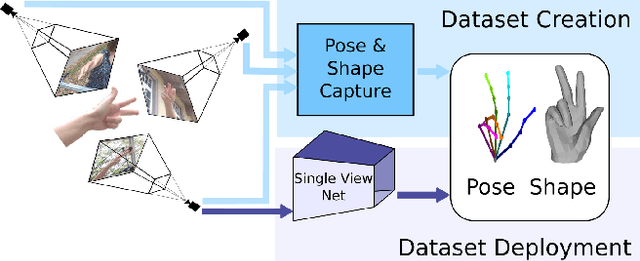
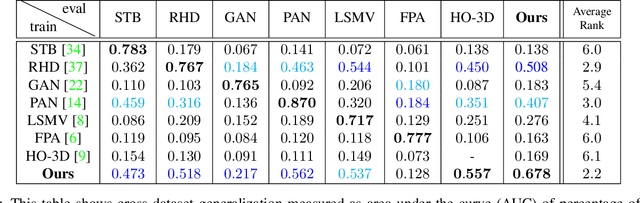

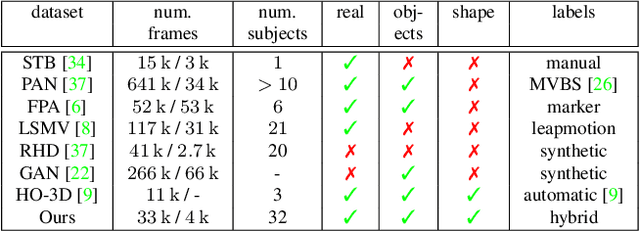
Estimating 3D hand pose from single RGB images is a highly ambiguous problem that relies on an unbiased training dataset. In this paper, we analyze cross-dataset generalization when training on existing datasets. We find that approaches perform well on the datasets they are trained on, but do not generalize to other datasets or in-the-wild scenarios. As a consequence, we introduce the first large-scale, multi-view hand dataset that is accompanied by both 3D hand pose and shape annotations. For annotating this real-world dataset, we propose an iterative, semi-automated `human-in-the-loop' approach, which includes hand fitting optimization to infer both the 3D pose and shape for each sample. We show that methods trained on our dataset consistently perform well when tested on other datasets. Moreover, the dataset allows us to train a network that predicts the full articulated hand shape from a single RGB image. The evaluation set can serve as a benchmark for articulated hand shape estimation.
3D Ken Burns Effect from a Single Image
Sep 12, 2019


The Ken Burns effect allows animating still images with a virtual camera scan and zoom. Adding parallax, which results in the 3D Ken Burns effect, enables significantly more compelling results. Creating such effects manually is time-consuming and demands sophisticated editing skills. Existing automatic methods, however, require multiple input images from varying viewpoints. In this paper, we introduce a framework that synthesizes the 3D Ken Burns effect from a single image, supporting both a fully automatic mode and an interactive mode with the user controlling the camera. Our framework first leverages a depth prediction pipeline, which estimates scene depth that is suitable for view synthesis tasks. To address the limitations of existing depth estimation methods such as geometric distortions, semantic distortions, and inaccurate depth boundaries, we develop a semantic-aware neural network for depth prediction, couple its estimate with a segmentation-based depth adjustment process, and employ a refinement neural network that facilitates accurate depth predictions at object boundaries. According to this depth estimate, our framework then maps the input image to a point cloud and synthesizes the resulting video frames by rendering the point cloud from the corresponding camera positions. To address disocclusions while maintaining geometrically and temporally coherent synthesis results, we utilize context-aware color- and depth-inpainting to fill in the missing information in the extreme views of the camera path, thus extending the scene geometry of the point cloud. Experiments with a wide variety of image content show that our method enables realistic synthesis results. Our study demonstrates that our system allows users to achieve better results while requiring little effort compared to existing solutions for the 3D Ken Burns effect creation.
Learning to Sit: Synthesizing Human-Chair Interactions via Hierarchical Control
Aug 20, 2019
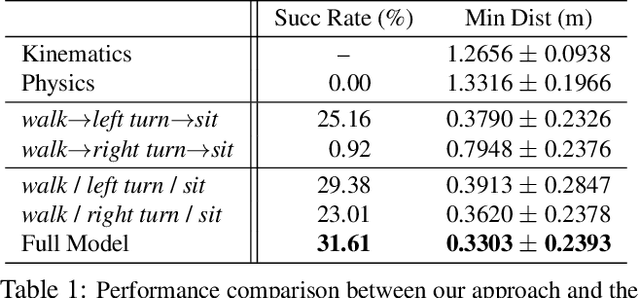
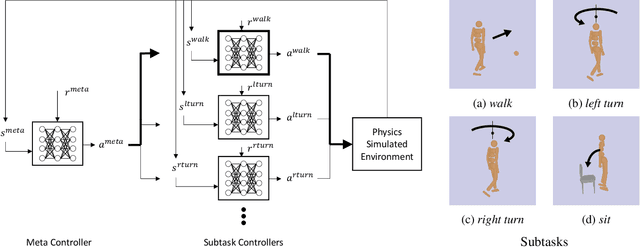
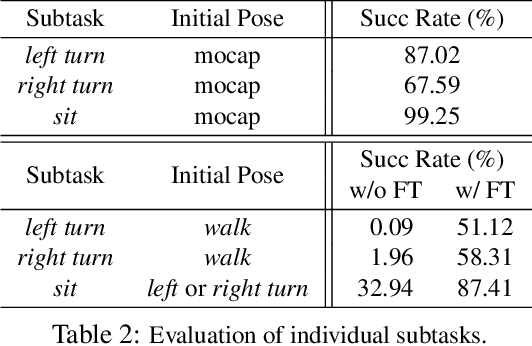
Recent progress on physics-based character animation has shown impressive breakthroughs on human motion synthesis, through the imitation of motion capture data via deep reinforcement learning. However, results have mostly been demonstrated on imitating a single distinct motion pattern, and do not generalize to interactive tasks that require flexible motion patterns due to varying human-object spatial configurations. In this paper, we focus on one class of interactive task---sitting onto a chair. We propose a hierarchical reinforcement learning framework which relies on a collection of subtask controllers trained to imitate simple, reusable mocap motions, and a meta controller trained to execute the subtasks properly to complete the main task. We experimentally demonstrate the strength of our approach over different single level and hierarchical baselines. We also show that our approach can be applied to motion prediction given an image input. A video highlight can be found at https://youtu.be/3CeN0OGz2cA.
Multimodal Style Transfer via Graph Cuts
May 17, 2019
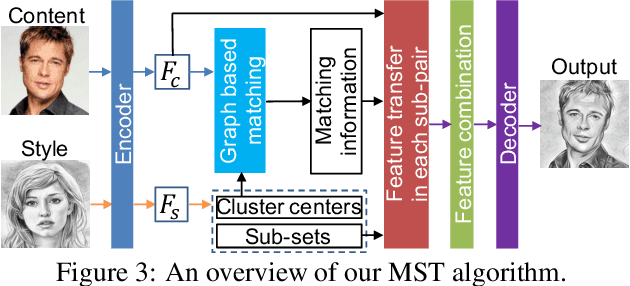

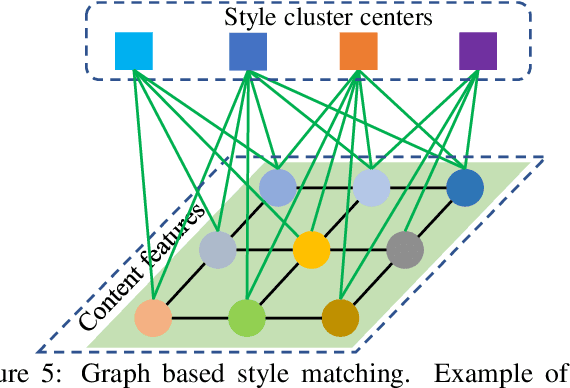
An assumption widely used in recent neural style transfer methods is that image styles can be described by global statics of deep features like Gram or covariance matrices. Alternative approaches have represented styles by decomposing them into local pixel or neural patches. Despite the recent progress, most existing methods treat the semantic patterns of style image uniformly, resulting unpleasing results on complex styles. In this paper, we introduce a more flexible and general universal style transfer technique: multimodal style transfer (MST). MST explicitly considers the matching of semantic patterns in content and style images. Specifically, the style image features are clustered into sub-style components, which are matched with local content features under a graph cut formulation. A reconstruction network is trained to transfer each sub-style and render the final stylized result. Extensive experiments demonstrate the superior effectiveness, robustness and flexibility of MST.
LayoutGAN: Generating Graphic Layouts with Wireframe Discriminators
Jan 21, 2019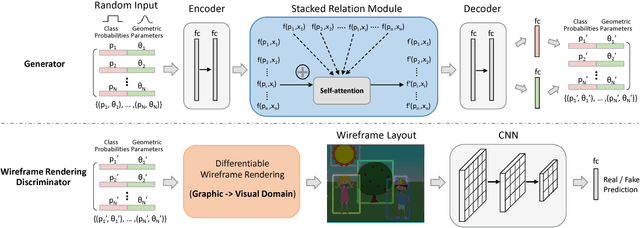

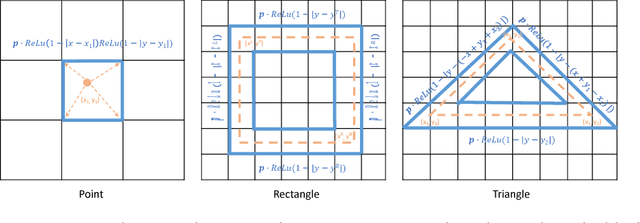
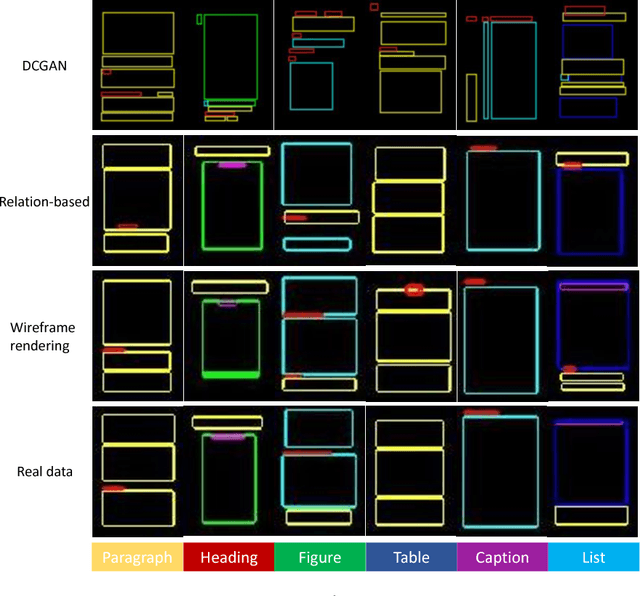
Layout is important for graphic design and scene generation. We propose a novel Generative Adversarial Network, called LayoutGAN, that synthesizes layouts by modeling geometric relations of different types of 2D elements. The generator of LayoutGAN takes as input a set of randomly-placed 2D graphic elements and uses self-attention modules to refine their labels and geometric parameters jointly to produce a realistic layout. Accurate alignment is critical for good layouts. We thus propose a novel differentiable wireframe rendering layer that maps the generated layout to a wireframe image, upon which a CNN-based discriminator is used to optimize the layouts in image space. We validate the effectiveness of LayoutGAN in various experiments including MNIST digit generation, document layout generation, clipart abstract scene generation and tangram graphic design.
Foreground-aware Image Inpainting
Jan 18, 2019
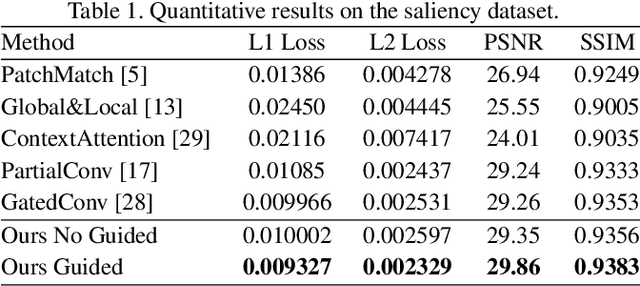
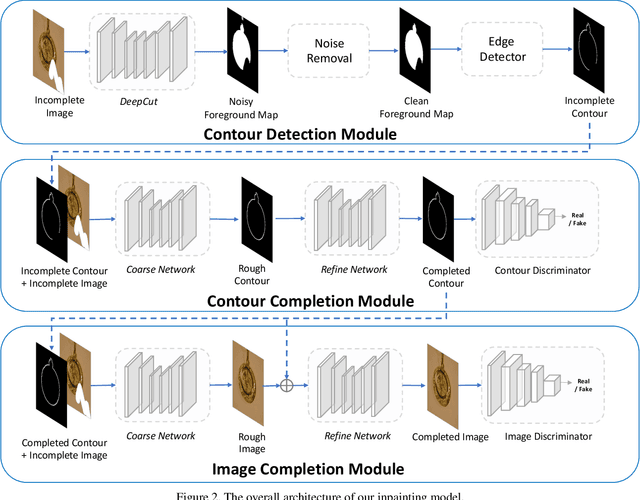

Existing image inpainting methods typically fill holes by borrowing information from surrounding image regions. They often produce unsatisfactory results when the holes overlap with or touch foreground objects due to lack of information about the actual extent of foreground and background regions within the holes. These scenarios, however, are very important in practice, especially for applications such as distracting object removal. To address the problem, we propose a foreground-aware image inpainting system that explicitly disentangles structure inference and content completion. Specifically, our model learns to predict the foreground contour first, and then inpaints the missing region using the predicted contour as guidance. We show that by this disentanglement, the contour completion model predicts reasonable contours of objects, and further substantially improves the performance of image inpainting. Experiments show that our method significantly outperforms existing methods and achieves superior inpainting results on challenging cases with complex compositions.
On the Continuity of Rotation Representations in Neural Networks
Dec 21, 2018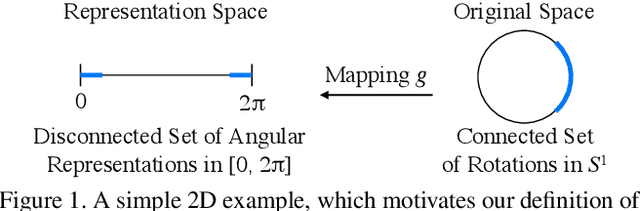
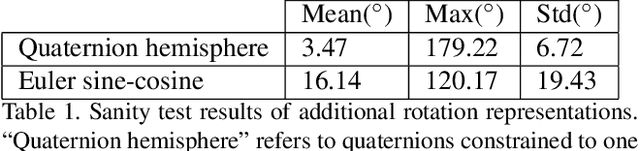

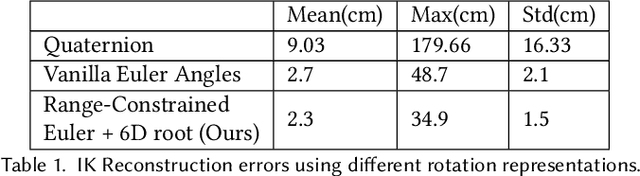
In neural networks, it is often desirable to work with various representations of the same space. For example, 3D rotations can be represented with quaternions or Euler angles. In this paper, we advance a definition of a continuous representation, which can be helpful for training deep neural network. We relate this to the definition of topological equivalence. We then investigate what are continuous and discontinuous representations for 2D, 3D, and n-dimensional rotations. We demonstrate that for 3D rotations, all representations are discontinuous in four or fewer dimensions in real Euclidean space. Thus, widely used representations such as quaternions and Euler angles are discontinuous and difficult for neural networks to learn. We show that the 3D rotations have continuous representations in 5D and 6D which are more suitable for learning. We also present continuous representations for the general case of the n dimensional rotation group SO(n). While our main focus is on rotations, we also show that our constructions apply to other groups such as the orthogonal group and similarity transforms. We finally present empirical results, which show that our continuous rotation representations outperform discontinuous ones for several practical problems in graphics and vision, including a simple autoencoder sanity test, a rotation estimator for 3D point clouds, and an inverse kinematics solver for 3D human poses.