 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidualViT for Efficient Temporally Dense Video Encoding
Sep 16, 2025



Several video understanding tasks, such as natural language temporal video grounding, temporal activity localization, and audio description generation, require "temporally dense" reasoning over frames sampled at high temporal resolution. However, computing frame-level features for these tasks is computationally expensive given the temporal resolution requirements. In this paper, we make three contributions to reduce the cost of computing features for temporally dense tasks. First, we introduce a vision transformer (ViT) architecture, dubbed ResidualViT, that leverages the large temporal redundancy in videos to efficiently compute temporally dense frame-level features. Our architecture incorporates (i) learnable residual connections that ensure temporal consistency across consecutive frames and (ii) a token reduction module that enhances processing speed by selectively discarding temporally redundant information while reusing weights of a pretrained foundation model. Second, we propose a lightweight distillation strategy to approximate the frame-level features of the original foundation model. Finally, we evaluate our approach across four tasks and five datasets, in both zero-shot and fully supervised settings, demonstrating significant reductions in computational cost (up to 60%) and improvements in inference speed (up to 2.5x faster), all while closely approximating the accuracy of the original foundation model.
Discovering Divergent Representations between Text-to-Image Models
Sep 10, 2025



In this paper, we investigate when and how visual representations learned by two different generative models diverge. Given two text-to-image models, our goal is to discover visual attributes that appear in images generated by one model but not the other, along with the types of prompts that trigger these attribute differences. For example, "flames" might appear in one model's outputs when given prompts expressing strong emotions, while the other model does not produce this attribute given the same prompts. We introduce CompCon (Comparing Concepts), an evolutionary search algorithm that discovers visual attributes more prevalent in one model's output than the other, and uncovers the prompt concepts linked to these visual differences. To evaluate CompCon's ability to find diverging representations, we create an automated data generation pipeline to produce ID2, a dataset of 60 input-dependent differences, and compare our approach to several LLM- and VLM-powered baselines. Finally, we use CompCon to compare popular text-to-image models, finding divergent representations such as how PixArt depicts prompts mentioning loneliness with wet streets and Stable Diffusion 3.5 depicts African American people in media professions. Code at: https://github.com/adobe-research/CompCon
Improving Personalized Search with Regularized Low-Rank Parameter Updates
Jun 11, 2025Personalized vision-language retrieval seeks to recognize new concepts (e.g. "my dog Fido") from only a few examples. This task is challenging because it requires not only learning a new concept from a few images, but also integrating the personal and general knowledge together to recognize the concept in different contexts. In this paper, we show how to effectively adapt the internal representation of a vision-language dual encoder model for personalized vision-language retrieval. We find that regularized low-rank adaption of a small set of parameters in the language encoder's final layer serves as a highly effective alternative to textual inversion for recognizing the personal concept while preserving general knowledge. Additionally, we explore strategies for combining parameters of multiple learned personal concepts, finding that parameter addition is effective. To evaluate how well general knowledge is preserved in a finetuned representation, we introduce a metric that measures image retrieval accuracy based on captions generated by a vision language model (VLM). Our approach achieves state-of-the-art accuracy on two benchmarks for personalized image retrieval with natural language queries - DeepFashion2 and ConCon-Chi - outperforming the prior art by 4%-22% on personal retrievals.
Video-Guided Foley Sound Generation with Multimodal Controls
Nov 26, 2024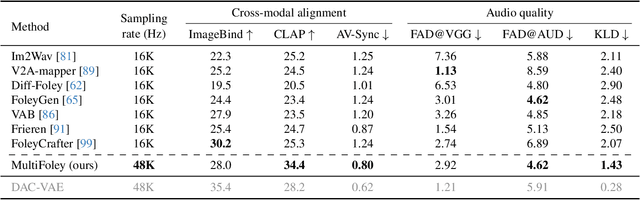
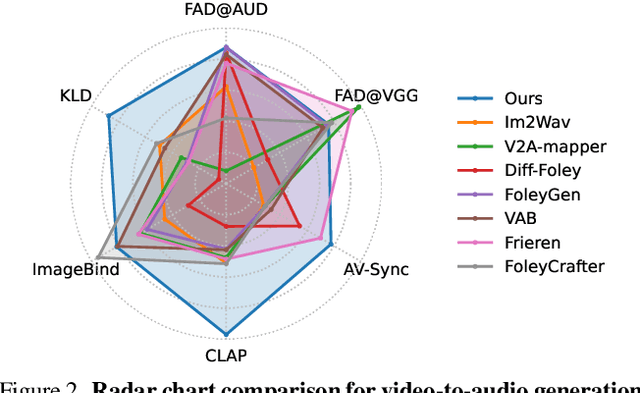
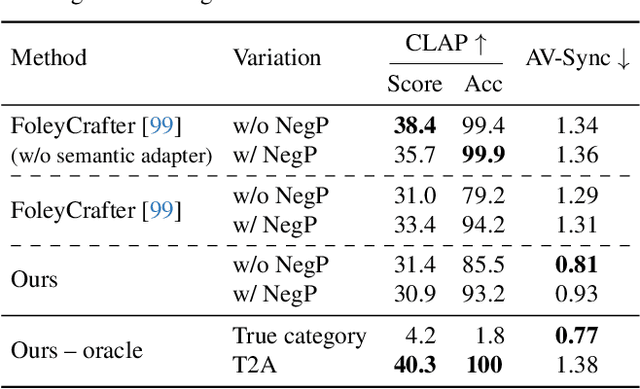
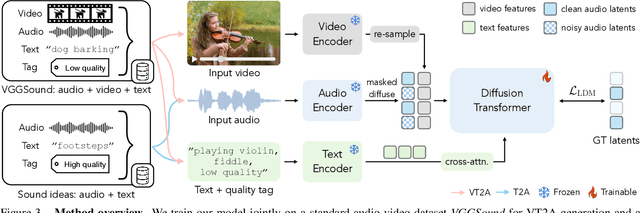
Generating sound effects for videos often requires creating artistic sound effects that diverge significantly from real-life sources and flexible control in the sound design. To address this problem, we introduce MultiFoley, a model designed for video-guided sound generation that supports multimodal conditioning through text, audio, and video. Given a silent video and a text prompt, MultiFoley allows users to create clean sounds (e.g., skateboard wheels spinning without wind noise) or more whimsical sounds (e.g., making a lion's roar sound like a cat's meow). MultiFoley also allows users to choose reference audio from sound effects (SFX) libraries or partial videos for conditioning. A key novelty of our model lies in its joint training on both internet video datasets with low-quality audio and professional SFX recordings, enabling high-quality, full-bandwidth (48kHz) audio generation. Through automated evaluations and human studies, we demonstrate that MultiFoley successfully generates synchronized high-quality sounds across varied conditional inputs and outperforms existing methods. Please see our project page for video results: https://ificl.github.io/MultiFoley/
Generative Timelines for Instructed Visual Assembly
Nov 19, 2024The objective of this work is to manipulate visual timelines (e.g. a video) through natural language instructions, making complex timeline editing tasks accessible to non-expert or potentially even disabled users. We call this task Instructed visual assembly. This task is challenging as it requires (i) identifying relevant visual content in the input timeline as well as retrieving relevant visual content in a given input (video) collection, (ii) understanding the input natural language instruction, and (iii) performing the desired edits of the input visual timeline to produce an output timeline. To address these challenges, we propose the Timeline Assembler, a generative model trained to perform instructed visual assembly tasks. The contributions of this work are three-fold. First, we develop a large multimodal language model, which is designed to process visual content, compactly represent timelines and accurately interpret timeline editing instructions. Second, we introduce a novel method for automatically generating datasets for visual assembly tasks, enabling efficient training of our model without the need for human-labeled data. Third, we validate our approach by creating two novel datasets for image and video assembly, demonstrating that the Timeline Assembler substantially outperforms established baseline models, including the recent GPT-4o, in accurately executing complex assembly instructions across various real-world inspired scenarios.
Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
May 06, 2024



In the recent years, the dual-encoder vision-language models (\eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.
Koala: Key frame-conditioned long video-LLM
Apr 05, 2024



Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
Customizing Motion in Text-to-Video Diffusion Models
Dec 07, 2023



We introduce an approach for augmenting text-to-video generation models with customized motions, extending their capabilities beyond the motions depicted in the original training data. By leveraging a few video samples demonstrating specific movements as input, our method learns and generalizes the input motion patterns for diverse, text-specified scenarios. Our contributions are threefold. First, to achieve our results, we finetune an existing text-to-video model to learn a novel mapping between the depicted motion in the input examples to a new unique token. To avoid overfitting to the new custom motion, we introduce an approach for regularization over videos. Second, by leveraging the motion priors in a pretrained model, our method can produce novel videos featuring multiple people doing the custom motion, and can invoke the motion in combination with other motions. Furthermore, our approach extends to the multimodal customization of motion and appearance of individualized subjects, enabling the generation of videos featuring unique characters and distinct motions. Third, to validate our method, we introduce an approach for quantitatively evaluating the learned custom motion and perform a systematic ablation study. We show that our method significantly outperforms prior appearance-based customization approaches when extended to the motion customization task.
Meta-Personalizing Vision-Language Models to Find Named Instances in Video
Jun 16, 2023Large-scale vision-language models (VLM) have shown impressive results for language-guided search applications. While these models allow category-level queries, they currently struggle with personalized searches for moments in a video where a specific object instance such as ``My dog Biscuit'' appears. We present the following three contributions to address this problem. First, we describe a method to meta-personalize a pre-trained VLM, i.e., learning how to learn to personalize a VLM at test time to search in video. Our method extends the VLM's token vocabulary by learning novel word embeddings specific to each instance. To capture only instance-specific features, we represent each instance embedding as a combination of shared and learned global category features. Second, we propose to learn such personalization without explicit human supervision. Our approach automatically identifies moments of named visual instances in video using transcripts and vision-language similarity in the VLM's embedding space. Finally, we introduce This-Is-My, a personal video instance retrieval benchmark. We evaluate our approach on This-Is-My and DeepFashion2 and show that we obtain a 15% relative improvement over the state of the art on the latter dataset.
Language-Guided Music Recommendation for Video via Prompt Analogies
Jun 15, 2023



We propose a method to recommend music for an input video while allowing a user to guide music selection with free-form natural language. A key challenge of this problem setting is that existing music video datasets provide the needed (video, music) training pairs, but lack text descriptions of the music. This work addresses this challenge with the following three contributions. First, we propose a text-synthesis approach that relies on an analogy-based prompting procedure to generate natural language music descriptions from a large-scale language model (BLOOM-176B) given pre-trained music tagger outputs and a small number of human text descriptions. Second, we use these synthesized music descriptions to train a new trimodal model, which fuses text and video input representations to query music samples. For training, we introduce a text dropout regularization mechanism which we show is critical to model performance. Our model design allows for the retrieved music audio to agree with the two input modalities by matching visual style depicted in the video and musical genre, mood, or instrumentation described in the natural language query. Third, to evaluate our approach, we collect a testing dataset for our problem by annotating a subset of 4k clips from the YT8M-MusicVideo dataset with natural language music descriptions which we make publicly available. We show that our approach can match or exceed the performance of prior methods on video-to-music retrieval while significantly improving retrieval accuracy when using text guidance.