 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025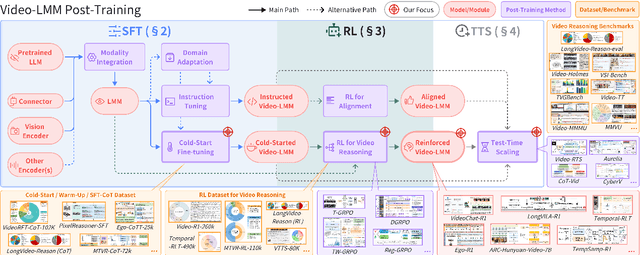
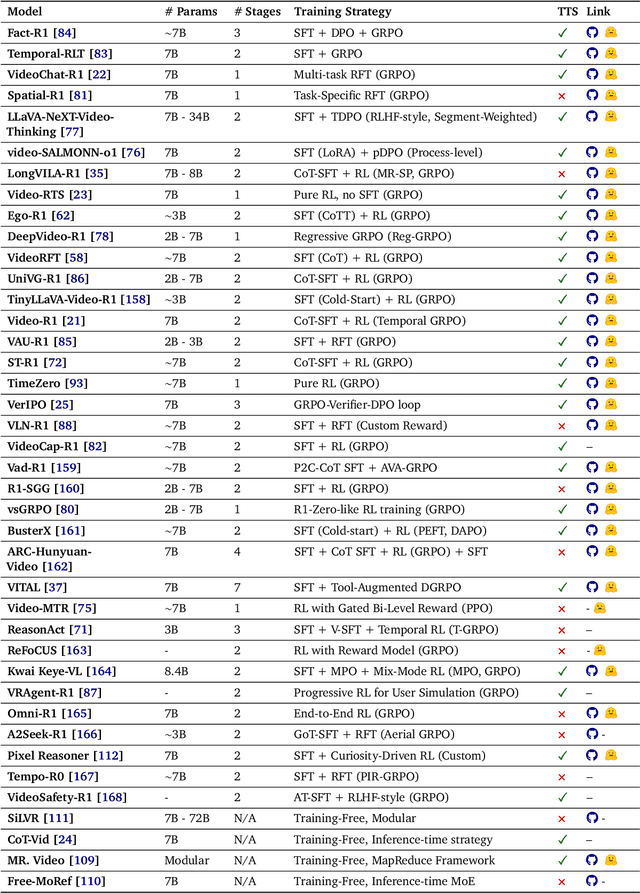
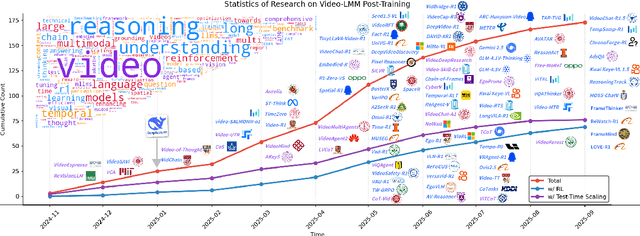
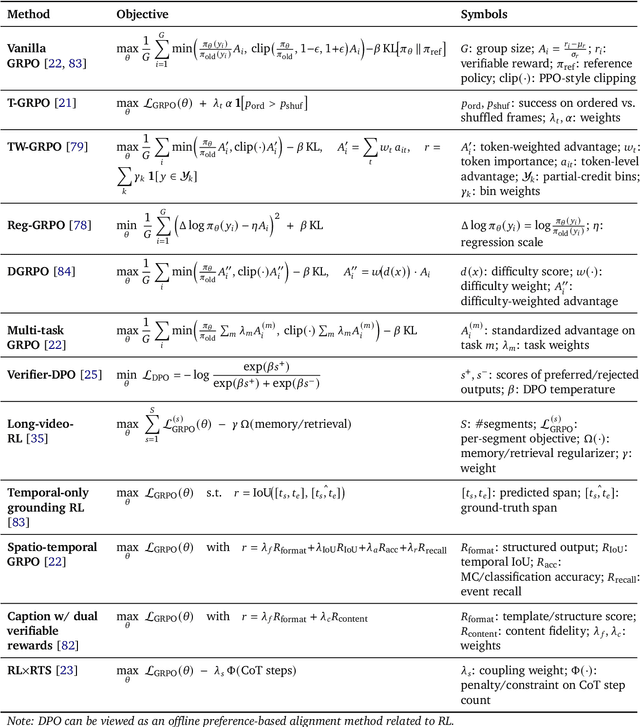
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Assessing Historical Structural Oppression Worldwide via Rule-Guided Prompting of Large Language Models
Sep 18, 2025



Traditional efforts to measure historical structural oppression struggle with cross-national validity due to the unique, locally specified histories of exclusion, colonization, and social status in each country, and often have relied on structured indices that privilege material resources while overlooking lived, identity-based exclusion. We introduce a novel framework for oppression measurement that leverages Large Language Models (LLMs) to generate context-sensitive scores of lived historical disadvantage across diverse geopolitical settings. Using unstructured self-identified ethnicity utterances from a multilingual COVID-19 global study, we design rule-guided prompting strategies that encourage models to produce interpretable, theoretically grounded estimations of oppression. We systematically evaluate these strategies across multiple state-of-the-art LLMs. Our results demonstrate that LLMs, when guided by explicit rules, can capture nuanced forms of identity-based historical oppression within nations. This approach provides a complementary measurement tool that highlights dimensions of systemic exclusion, offering a scalable, cross-cultural lens for understanding how oppression manifests in data-driven research and public health contexts. To support reproducible evaluation, we release an open-sourced benchmark dataset for assessing LLMs on oppression measurement (https://github.com/chattergpt/llm-oppression-benchmark).
PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
EndoMatcher: Generalizable Endoscopic Image Matcher via Multi-Domain Pre-training for Robot-Assisted Surgery
Aug 07, 2025Generalizable dense feature matching in endoscopic images is crucial for robot-assisted tasks, including 3D reconstruction, navigation, and surgical scene understanding. Yet, it remains a challenge due to difficult visual conditions (e.g., weak textures, large viewpoint variations) and a scarcity of annotated data. To address these challenges, we propose EndoMatcher, a generalizable endoscopic image matcher via large-scale, multi-domain data pre-training. To address difficult visual conditions, EndoMatcher employs a two-branch Vision Transformer to extract multi-scale features, enhanced by dual interaction blocks for robust correspondence learning. To overcome data scarcity and improve domain diversity, we construct Endo-Mix6, the first multi-domain dataset for endoscopic matching. Endo-Mix6 consists of approximately 1.2M real and synthetic image pairs across six domains, with correspondence labels generated using Structure-from-Motion and simulated transformations. The diversity and scale of Endo-Mix6 introduce new challenges in training stability due to significant variations in dataset sizes, distribution shifts, and error imbalance. To address them, a progressive multi-objective training strategy is employed to promote balanced learning and improve representation quality across domains. This enables EndoMatcher to generalize across unseen organs and imaging conditions in a zero-shot fashion. Extensive zero-shot matching experiments demonstrate that EndoMatcher increases the number of inlier matches by 140.69% and 201.43% on the Hamlyn and Bladder datasets over state-of-the-art methods, respectively, and improves the Matching Direction Prediction Accuracy (MDPA) by 9.40% on the Gastro-Matching dataset, achieving dense and accurate matching under challenging endoscopic conditions. The code is publicly available at https://github.com/Beryl2000/EndoMatcher.
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
The Docking Game: Loop Self-Play for Fast, Dynamic, and Accurate Prediction of Flexible Protein--Ligand Binding
Aug 07, 2025Molecular docking is a crucial aspect of drug discovery, as it predicts the binding interactions between small-molecule ligands and protein pockets. However, current multi-task learning models for docking often show inferior performance in ligand docking compared to protein pocket docking. This disparity arises largely due to the distinct structural complexities of ligands and proteins. To address this issue, we propose a novel game-theoretic framework that models the protein-ligand interaction as a two-player game called the Docking Game, with the ligand docking module acting as the ligand player and the protein pocket docking module as the protein player. To solve this game, we develop a novel Loop Self-Play (LoopPlay) algorithm, which alternately trains these players through a two-level loop. In the outer loop, the players exchange predicted poses, allowing each to incorporate the other's structural predictions, which fosters mutual adaptation over multiple iterations. In the inner loop, each player dynamically refines its predictions by incorporating its own predicted ligand or pocket poses back into its model. We theoretically show the convergence of LoopPlay, ensuring stable optimization. Extensive experiments conducted on public benchmark datasets demonstrate that LoopPlay achieves approximately a 10\% improvement in predicting accurate binding modes compared to previous state-of-the-art methods. This highlights its potential to enhance the accuracy of molecular docking in drug discovery.
Diffusion Transformer-to-Mamba Distillation for High-Resolution Image Generation
Jun 23, 2025



The quadratic computational complexity of self-attention in diffusion transformers (DiT) introduces substantial computational costs in high-resolution image generation. While the linear-complexity Mamba model emerges as a potential alternative, direct Mamba training remains empirically challenging. To address this issue, this paper introduces diffusion transformer-to-mamba distillation (T2MD), forming an efficient training pipeline that facilitates the transition from the self-attention-based transformer to the linear complexity state-space model Mamba. We establish a diffusion self-attention and Mamba hybrid model that simultaneously achieves efficiency and global dependencies. With the proposed layer-level teacher forcing and feature-based knowledge distillation, T2MD alleviates the training difficulty and high cost of a state space model from scratch. Starting from the distilled 512$\times$512 resolution base model, we push the generation towards 2048$\times$2048 images via lightweight adaptation and high-resolution fine-tuning. Experiments demonstrate that our training path leads to low overhead but high-quality text-to-image generation. Importantly, our results also justify the feasibility of using sequential and causal Mamba models for generating non-causal visual output, suggesting the potential for future exploration.
Unleashing Hour-Scale Video Training for Long Video-Language Understanding
Jun 05, 2025Recent long-form video-language understanding benchmarks have driven progress in video large multimodal models (Video-LMMs). However, the scarcity of well-annotated long videos has left the training of hour-long Video-LLMs underexplored. To close this gap, we present VideoMarathon, a large-scale hour-long video instruction-following dataset. This dataset includes around 9,700 hours of long videos sourced from diverse domains, ranging from 3 to 60 minutes per video. Specifically, it contains 3.3M high-quality QA pairs, spanning six fundamental topics: temporality, spatiality, object, action, scene, and event. Compared to existing video instruction datasets, VideoMarathon significantly extends training video durations up to 1 hour, and supports 22 diverse tasks requiring both short- and long-term video comprehension. Building on VideoMarathon, we propose Hour-LLaVA, a powerful and efficient Video-LMM for hour-scale video-language modeling. It enables hour-long video training and inference at 1-FPS sampling by leveraging a memory augmentation module, which adaptively integrates user question-relevant and spatiotemporal-informative semantics from a cached full video context. In our experiments, Hour-LLaVA achieves the best performance on multiple long video-language benchmarks, demonstrating the high quality of the VideoMarathon dataset and the superiority of the Hour-LLaVA model.