 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless Communication Enhanced Value Decomposition for Multi-Agent Reinforcement Learning
Apr 09, 2026Cooperation in multi-agent reinforcement learning (MARL) benefits from inter-agent communication, yet most approaches assume idealized channels and existing value decomposition methods ignore who successfully shared information with whom. We propose CLOVER, a cooperative MARL framework whose centralized value mixer is conditioned on the communication graph realized under a realistic wireless channel. This graph introduces a relational inductive bias into value decomposition, constraining how individual utilities are mixed based on the realized communication structure. The mixer is a GNN with node-specific weights generated by a Permutation-Equivariant Hypernetwork: multi-hop propagation along communication edges reshapes credit assignment so that different topologies induce different mixing. We prove this mixer is permutation invariant, monotonic (preserving the IGM condition), and strictly more expressive than QMIX-style mixers. To handle realistic channels, we formulate an augmented MDP isolating stochastic channel effects from the agent computation graph, and employ a stochastic receptive field encoder for variable-size message sets, enabling end-to-end differentiable training. On Predator-Prey and Lumberjacks benchmarks under p-CSMA wireless channels, CLOVER consistently improves convergence speed and final performance over VDN, QMIX, TarMAC+VDN, and TarMAC+QMIX. Behavioral analysis confirms agents learn adaptive signaling and listening strategies, and ablations isolate the communication-graph inductive bias as the key source of improvement.
Mixture of Weak & Strong Experts on Graphs
Nov 09, 2023Realistic graphs contain both rich self-features of nodes and informative structures of neighborhoods, jointly handled by a GNN in the typical setup. We propose to decouple the two modalities by mixture of weak and strong experts (Mowst), where the weak expert is a light-weight Multi-layer Perceptron (MLP), and the strong expert is an off-the-shelf Graph Neural Network (GNN). To adapt the experts' collaboration to different target nodes, we propose a "confidence" mechanism based on the dispersion of the weak expert's prediction logits. The strong expert is conditionally activated when either the node's classification relies on neighborhood information, or the weak expert has low model quality. We reveal interesting training dynamics by analyzing the influence of the confidence function on loss: our training algorithm encourages the specialization of each expert by effectively generating soft splitting of the graph. In addition, our "confidence" design imposes a desirable bias toward the strong expert to benefit from GNN's better generalization capability. Mowst is easy to optimize and achieves strong expressive power, with a computation cost comparable to a single GNN. Empirically, Mowst shows significant accuracy improvement on 6 standard node classification benchmarks (including both homophilous and heterophilous graphs).
Learning Practical Communication Strategies in Cooperative Multi-Agent Reinforcement Learning
Sep 02, 2022

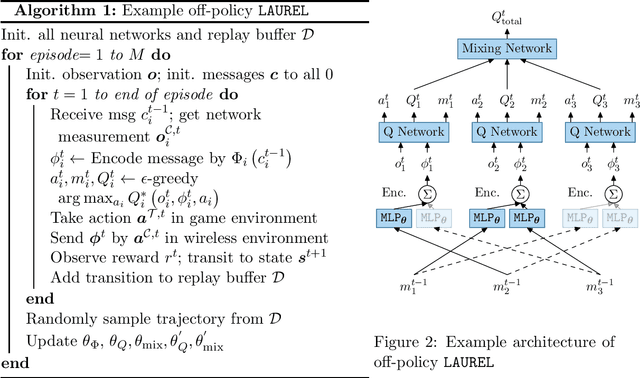

In Multi-Agent Reinforcement Learning, communication is critical to encourage cooperation among agents. Communication in realistic wireless networks can be highly unreliable due to network conditions varying with agents' mobility, and stochasticity in the transmission process. We propose a framework to learn practical communication strategies by addressing three fundamental questions: (1) When: Agents learn the timing of communication based on not only message importance but also wireless channel conditions. (2) What: Agents augment message contents with wireless network measurements to better select the game and communication actions. (3) How: Agents use a novel neural message encoder to preserve all information from received messages, regardless of the number and order of messages. Simulating standard benchmarks under realistic wireless network settings, we show significant improvements in game performance, convergence speed and communication efficiency compared with state-of-the-art.