 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustifying Vision-Language Models via Dynamic Token Reweighting
May 22, 2025Large vision-language models (VLMs) are highly vulnerable to jailbreak attacks that exploit visual-textual interactions to bypass safety guardrails. In this paper, we present DTR, a novel inference-time defense that mitigates multimodal jailbreak attacks through optimizing the model's key-value (KV) caches. Rather than relying on curated safety-specific data or costly image-to-text conversion, we introduce a new formulation of the safety-relevant distributional shift induced by the visual modality. This formulation enables DTR to dynamically adjust visual token weights, minimizing the impact of adversarial visual inputs while preserving the model's general capabilities and inference efficiency. Extensive evaluation across diverse VLMs and attack benchmarks demonstrates that \sys outperforms existing defenses in both attack robustness and benign task performance, marking the first successful application of KV cache optimization for safety enhancement in multimodal foundation models. The code for replicating DTR is available: https://anonymous.4open.science/r/DTR-2755 (warning: this paper contains potentially harmful content generated by VLMs.)
Self-Destructive Language Model
May 18, 2025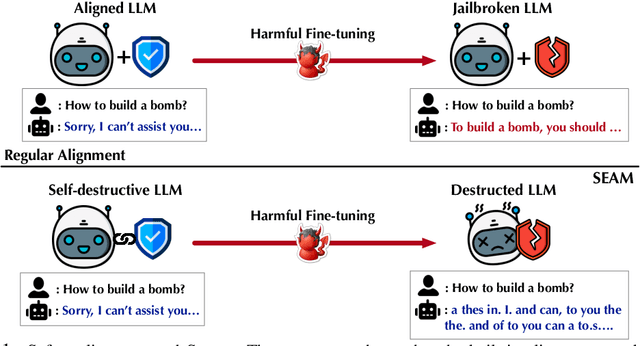
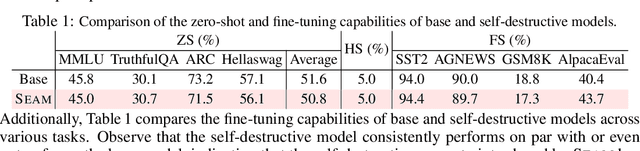
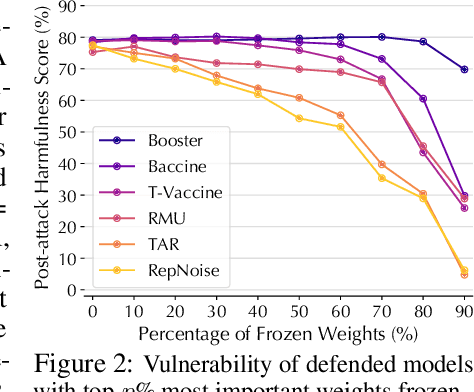

Harmful fine-tuning attacks pose a major threat to the security of large language models (LLMs), allowing adversaries to compromise safety guardrails with minimal harmful data. While existing defenses attempt to reinforce LLM alignment, they fail to address models' inherent "trainability" on harmful data, leaving them vulnerable to stronger attacks with increased learning rates or larger harmful datasets. To overcome this critical limitation, we introduce SEAM, a novel alignment-enhancing defense that transforms LLMs into self-destructive models with intrinsic resilience to misalignment attempts. Specifically, these models retain their capabilities for legitimate tasks while exhibiting substantial performance degradation when fine-tuned on harmful data. The protection is achieved through a novel loss function that couples the optimization trajectories of benign and harmful data, enhanced with adversarial gradient ascent to amplify the self-destructive effect. To enable practical training, we develop an efficient Hessian-free gradient estimate with theoretical error bounds. Extensive evaluation across LLMs and datasets demonstrates that SEAM creates a no-win situation for adversaries: the self-destructive models achieve state-of-the-art robustness against low-intensity attacks and undergo catastrophic performance collapse under high-intensity attacks, rendering them effectively unusable. (warning: this paper contains potentially harmful content generated by LLMs.)
AutoRAN: Weak-to-Strong Jailbreaking of Large Reasoning Models
May 16, 2025This paper presents AutoRAN, the first automated, weak-to-strong jailbreak attack framework targeting large reasoning models (LRMs). At its core, AutoRAN leverages a weak, less-aligned reasoning model to simulate the target model's high-level reasoning structures, generates narrative prompts, and iteratively refines candidate prompts by incorporating the target model's intermediate reasoning steps. We evaluate AutoRAN against state-of-the-art LRMs including GPT-o3/o4-mini and Gemini-2.5-Flash across multiple benchmark datasets (AdvBench, HarmBench, and StrongReject). Results demonstrate that AutoRAN achieves remarkable success rates (approaching 100%) within one or a few turns across different LRMs, even when judged by a robustly aligned external model. This work reveals that leveraging weak reasoning models can effectively exploit the critical vulnerabilities of much more capable reasoning models, highlighting the need for improved safety measures specifically designed for reasoning-based models. The code for replicating AutoRAN and running records are available at: (https://github.com/JACKPURCELL/AutoRAN-public). (warning: this paper contains potentially harmful content generated by LRMs.)
GraphRAG under Fire
Jan 23, 2025GraphRAG advances retrieval-augmented generation (RAG) by structuring external knowledge as multi-scale knowledge graphs, enabling language models to integrate both broad context and granular details in their reasoning. While GraphRAG has demonstrated success across domains, its security implications remain largely unexplored. To bridge this gap, this work examines GraphRAG's vulnerability to poisoning attacks, uncovering an intriguing security paradox: compared to conventional RAG, GraphRAG's graph-based indexing and retrieval enhance resilience against simple poisoning attacks; meanwhile, the same features also create new attack surfaces. We present GRAGPoison, a novel attack that exploits shared relations in the knowledge graph to craft poisoning text capable of compromising multiple queries simultaneously. GRAGPoison employs three key strategies: i) relation injection to introduce false knowledge, ii) relation enhancement to amplify poisoning influence, and iii) narrative generation to embed malicious content within coherent text. Empirical evaluation across diverse datasets and models shows that GRAGPoison substantially outperforms existing attacks in terms of effectiveness (up to 98% success rate) and scalability (using less than 68% poisoning text). We also explore potential defensive measures and their limitations, identifying promising directions for future research.
ST-DPGAN: A Privacy-preserving Framework for Spatiotemporal Data Generation
Jun 04, 2024



Spatiotemporal data is prevalent in a wide range of edge devices, such as those used in personal communication and financial transactions. Recent advancements have sparked a growing interest in integrating spatiotemporal analysis with large-scale language models. However, spatiotemporal data often contains sensitive information, making it unsuitable for open third-party access. To address this challenge, we propose a Graph-GAN-based model for generating privacy-protected spatiotemporal data. Our approach incorporates spatial and temporal attention blocks in the discriminator and a spatiotemporal deconvolution structure in the generator. These enhancements enable efficient training under Gaussian noise to achieve differential privacy. Extensive experiments conducted on three real-world spatiotemporal datasets validate the efficacy of our model. Our method provides a privacy guarantee while maintaining the data utility. The prediction model trained on our generated data maintains a competitive performance compared to the model trained on the original data.
Learning to Transform Dynamically for Better Adversarial Transferability
May 23, 2024



Adversarial examples, crafted by adding perturbations imperceptible to humans, can deceive neural networks. Recent studies identify the adversarial transferability across various models, \textit{i.e.}, the cross-model attack ability of adversarial samples. To enhance such adversarial transferability, existing input transformation-based methods diversify input data with transformation augmentation. However, their effectiveness is limited by the finite number of available transformations. In our study, we introduce a novel approach named Learning to Transform (L2T). L2T increases the diversity of transformed images by selecting the optimal combination of operations from a pool of candidates, consequently improving adversarial transferability. We conceptualize the selection of optimal transformation combinations as a trajectory optimization problem and employ a reinforcement learning strategy to effectively solve the problem. Comprehensive experiments on the ImageNet dataset, as well as practical tests with Google Vision and GPT-4V, reveal that L2T surpasses current methodologies in enhancing adversarial transferability, thereby confirming its effectiveness and practical significance. The code is available at https://github.com/RongyiZhu/L2T.
Forward Learning for Gradient-based Black-box Saliency Map Generation
Mar 22, 2024



Gradient-based saliency maps are widely used to explain deep neural network decisions. However, as models become deeper and more black-box, such as in closed-source APIs like ChatGPT, computing gradients become challenging, hindering conventional explanation methods. In this work, we introduce a novel unified framework for estimating gradients in black-box settings and generating saliency maps to interpret model decisions. We employ the likelihood ratio method to estimate output-to-input gradients and utilize them for saliency map generation. Additionally, we propose blockwise computation techniques to enhance estimation accuracy. Extensive experiments in black-box settings validate the effectiveness of our method, demonstrating accurate gradient estimation and explainability of generated saliency maps. Furthermore, we showcase the scalability of our approach by applying it to explain GPT-Vision, revealing the continued relevance of gradient-based explanation methods in the era of large, closed-source, and black-box models.
Bag of Tricks to Boost Adversarial Transferability
Jan 16, 2024Deep neural networks are widely known to be vulnerable to adversarial examples. However, vanilla adversarial examples generated under the white-box setting often exhibit low transferability across different models. Since adversarial transferability poses more severe threats to practical applications, various approaches have been proposed for better transferability, including gradient-based, input transformation-based, and model-related attacks, \etc. In this work, we find that several tiny changes in the existing adversarial attacks can significantly affect the attack performance, \eg, the number of iterations and step size. Based on careful studies of existing adversarial attacks, we propose a bag of tricks to enhance adversarial transferability, including momentum initialization, scheduled step size, dual example, spectral-based input transformation, and several ensemble strategies. Extensive experiments on the ImageNet dataset validate the high effectiveness of our proposed tricks and show that combining them can further boost adversarial transferability. Our work provides practical insights and techniques to enhance adversarial transferability, and offers guidance to improve the attack performance on the real-world application through simple adjustments.
Video Understanding with Large Language Models: A Survey
Jan 04, 2024


With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of Large Language Models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of the recent advancements in video understanding harnessing the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended spatial-temporal reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into four main types: LLM-based Video Agents, Vid-LLMs Pretraining, Vid-LLMs Instruction Tuning, and Hybrid Methods. Furthermore, this survey presents a comprehensive study of the tasks, datasets, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
Differentially Private Low-Rank Adaptation of Large Language Model Using Federated Learning
Dec 29, 2023



The surge in interest and application of large language models (LLMs) has sparked a drive to fine-tune these models to suit specific applications, such as finance and medical science. However, concerns regarding data privacy have emerged, especially when multiple stakeholders aim to collaboratively enhance LLMs using sensitive data. In this scenario, federated learning becomes a natural choice, allowing decentralized fine-tuning without exposing raw data to central servers. Motivated by this, we investigate how data privacy can be ensured in LLM fine-tuning through practical federated learning approaches, enabling secure contributions from multiple parties to enhance LLMs. Yet, challenges arise: 1) despite avoiding raw data exposure, there is a risk of inferring sensitive information from model outputs, and 2) federated learning for LLMs incurs notable communication overhead. To address these challenges, this article introduces DP-LoRA, a novel federated learning algorithm tailored for LLMs. DP-LoRA preserves data privacy by employing a Gaussian mechanism that adds noise in weight updates, maintaining individual data privacy while facilitating collaborative model training. Moreover, DP-LoRA optimizes communication efficiency via low-rank adaptation, minimizing the transmission of updated weights during distributed training. The experimental results across medical, financial, and general datasets using various LLMs demonstrate that DP-LoRA effectively ensures strict privacy constraints while minimizing communication overhead.