 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDW: Extreme Multimodal Summarisation of News Videos
Oct 16, 2022

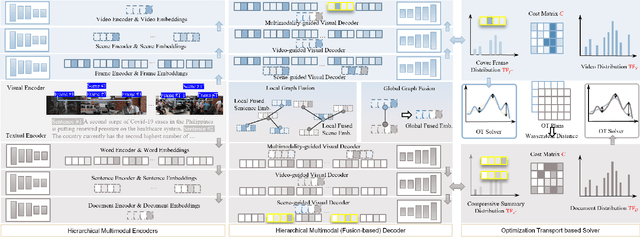
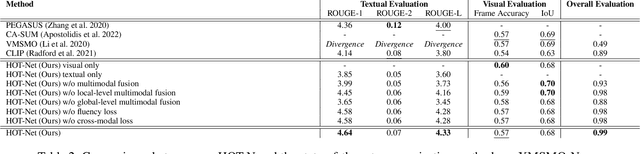
Multimodal summarisation with multimodal output is drawing increasing attention due to the rapid growth of multimedia data. While several methods have been proposed to summarise visual-text contents, their multimodal outputs are not succinct enough at an extreme level to address the information overload issue. To the end of extreme multimodal summarisation, we introduce a new task, eXtreme Multimodal Summarisation with Multimodal Output (XMSMO) for the scenario of TL;DW - Too Long; Didn't Watch, akin to TL;DR. XMSMO aims to summarise a video-document pair into a summary with an extremely short length, which consists of one cover frame as the visual summary and one sentence as the textual summary. We propose a novel unsupervised Hierarchical Optimal Transport Network (HOT-Net) consisting of three components: hierarchical multimodal encoders, hierarchical multimodal fusion decoders, and optimal transport solvers. Our method is trained, without using reference summaries, by optimising the visual and textual coverage from the perspectives of the distance between the semantic distributions under optimal transport plans. To facilitate the study on this task, we collect a large-scale dataset XMSMO-News by harvesting 4,891 video-document pairs. The experimental results show that our method achieves promising performance in terms of ROUGE and IoU metrics.
Contextual Modeling for 3D Dense Captioning on Point Clouds
Oct 08, 2022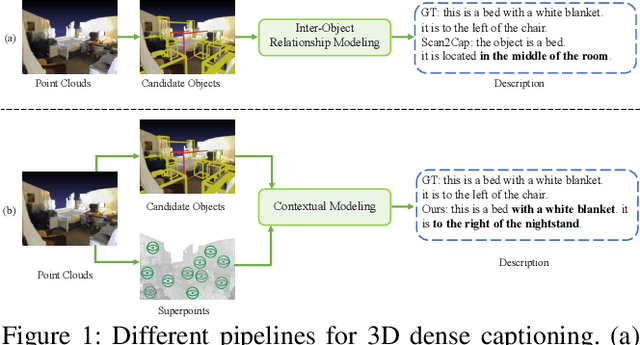
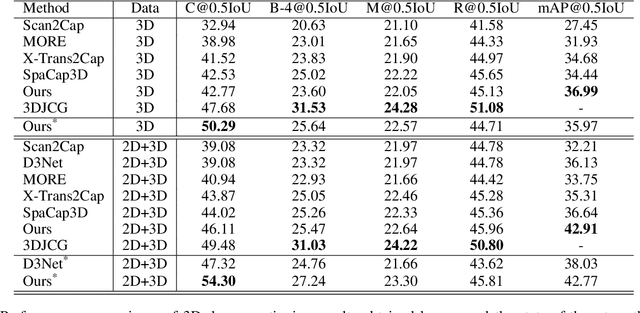
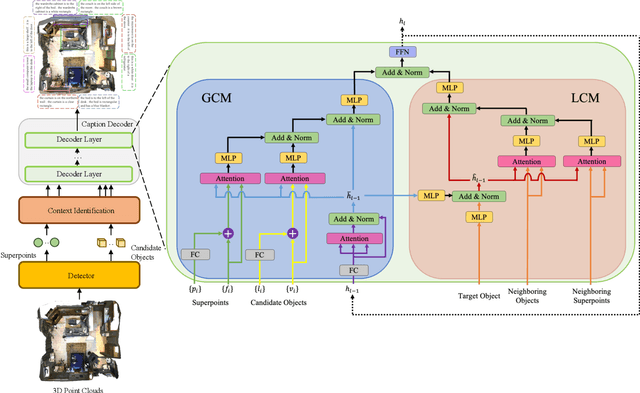
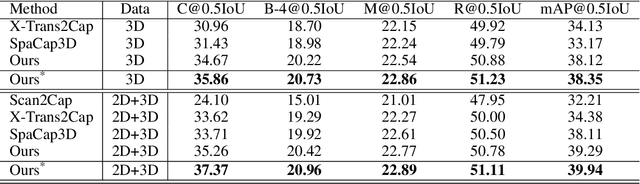
3D dense captioning, as an emerging vision-language task, aims to identify and locate each object from a set of point clouds and generate a distinctive natural language sentence for describing each located object. However, the existing methods mainly focus on mining inter-object relationship, while ignoring contextual information, especially the non-object details and background environment within the point clouds, thus leading to low-quality descriptions, such as inaccurate relative position information. In this paper, we make the first attempt to utilize the point clouds clustering features as the contextual information to supply the non-object details and background environment of the point clouds and incorporate them into the 3D dense captioning task. We propose two separate modules, namely the Global Context Modeling (GCM) and Local Context Modeling (LCM), in a coarse-to-fine manner to perform the contextual modeling of the point clouds. Specifically, the GCM module captures the inter-object relationship among all objects with global contextual information to obtain more complete scene information of the whole point clouds. The LCM module exploits the influence of the neighboring objects of the target object and local contextual information to enrich the object representations. With such global and local contextual modeling strategies, our proposed model can effectively characterize the object representations and contextual information and thereby generate comprehensive and detailed descriptions of the located objects. Extensive experiments on the ScanRefer and Nr3D datasets demonstrate that our proposed method sets a new record on the 3D dense captioning task, and verify the effectiveness of our raised contextual modeling of point clouds.
Causal Inference via Nonlinear Variable Decorrelation for Healthcare Applications
Sep 29, 2022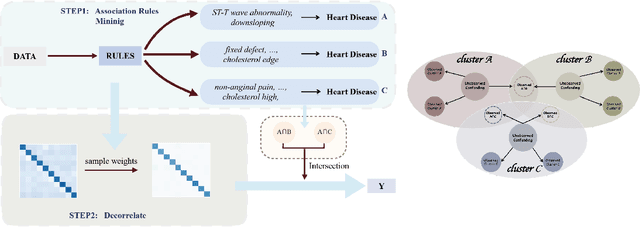
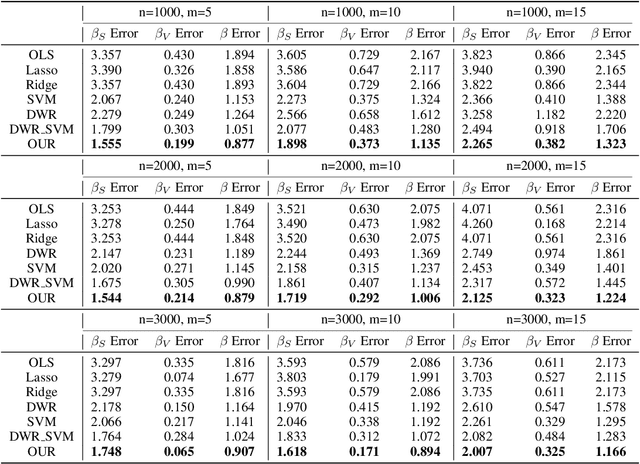
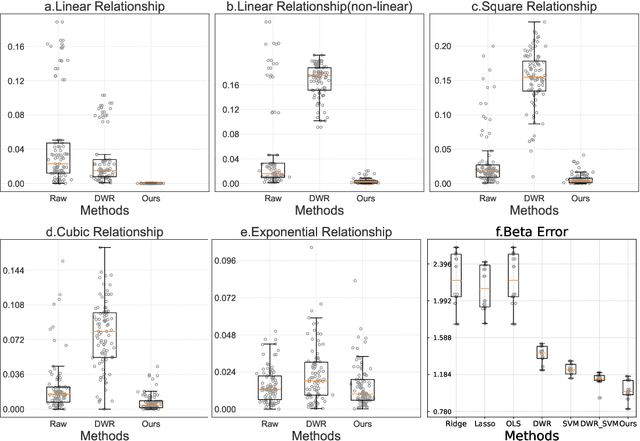
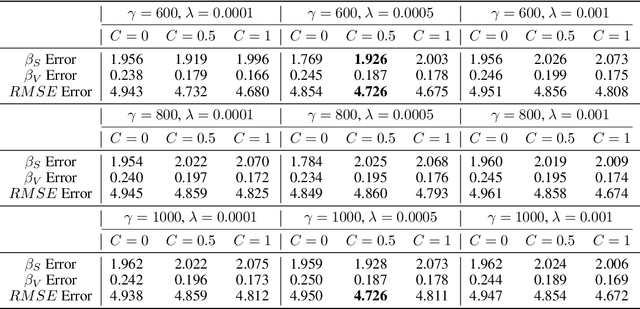
Causal inference and model interpretability research are gaining increasing attention, especially in the domains of healthcare and bioinformatics. Despite recent successes in this field, decorrelating features under nonlinear environments with human interpretable representations has not been adequately investigated. To address this issue, we introduce a novel method with a variable decorrelation regularizer to handle both linear and nonlinear confounding. Moreover, we employ association rules as new representations using association rule mining based on the original features to further proximate human decision patterns to increase model interpretability. Extensive experiments are conducted on four healthcare datasets (one synthetically generated and three real-world collections on different diseases). Quantitative results in comparison to baseline approaches on parameter estimation and causality computation indicate the model's superior performance. Furthermore, expert evaluation given by healthcare professionals validates the effectiveness and interpretability of the proposed model.
CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment
Sep 23, 2022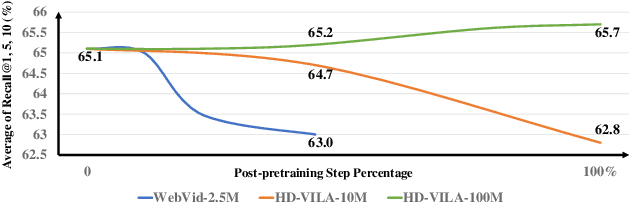
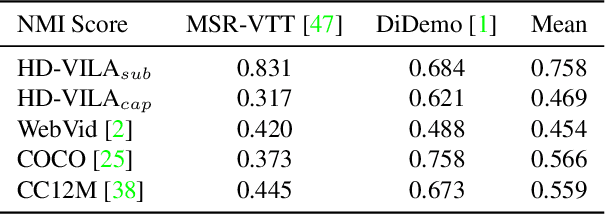
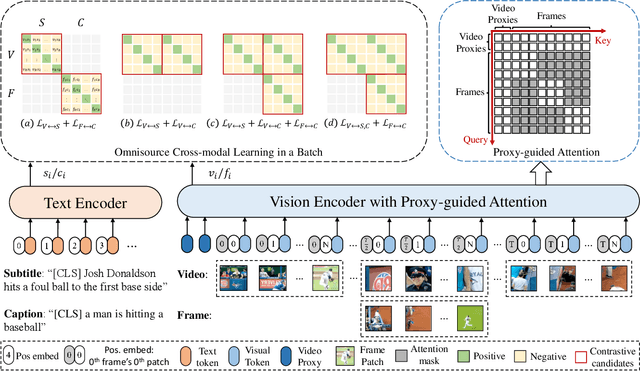
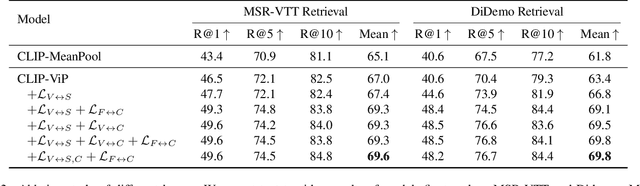
The pre-trained image-text models, like CLIP, have demonstrated the strong power of vision-language representation learned from a large scale of web-collected image-text data. In light of the well-learned visual features, some existing works transfer image representation to video domain and achieve good results. However, how to utilize image-language pre-trained model (e.g., CLIP) for video-language pre-training (post-pretraining) is still under explored. In this paper, we investigate two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? Through a series of comparative experiments and analyses, we find that the data scale and domain gap between language sources have great impacts. Motivated by these, we propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP. Extensive results show that our approach improves the performance of CLIP on video-text retrieval by a large margin. Our model also achieves SOTA results on a variety of datasets, including MSR-VTT, DiDeMo, LSMDC, and ActivityNet. We will release our code and pre-trained CLIP-ViP models at https://github.com/microsoft/XPretrain/tree/main/CLIP-ViP.
Remote Medication Status Prediction for Individuals with Parkinson's Disease using Time-series Data from Smartphones
Jul 26, 2022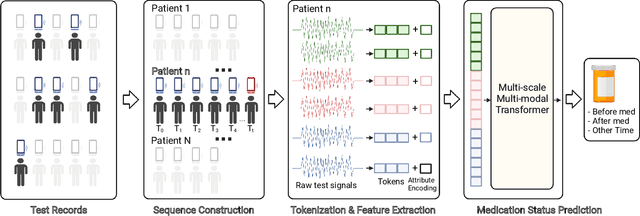
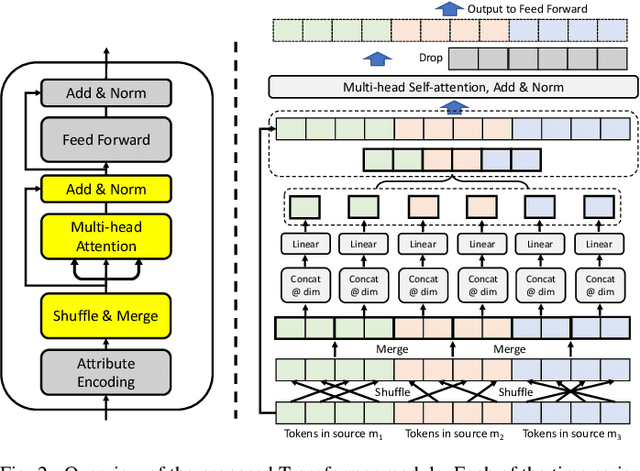
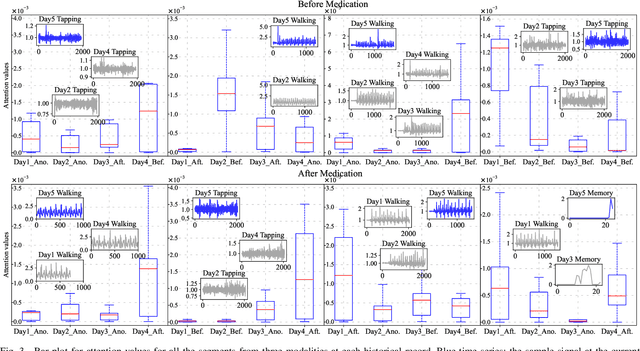
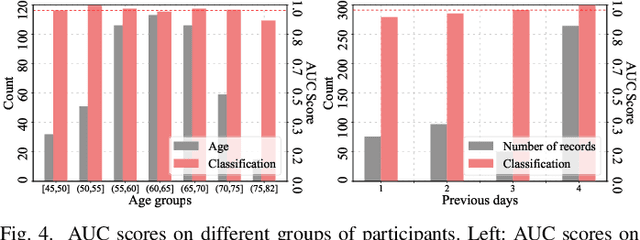
Medication for neurological diseases such as the Parkinson's disease usually happens remotely at home, away from hospitals. Such out-of-lab environments pose challenges in collecting timely and accurate health status data using the limited professional care devices for health condition analysis, medication adherence measurement and future dose or treatment planning. Individual differences in behavioral signals collected from wearable sensors also lead to difficulties in adopting current general machine learning analysis pipelines. To address these challenges, we present a method for predicting medication status of Parkinson's disease patients using the public mPower dataset, which contains 62,182 remote multi-modal test records collected on smartphones from 487 patients. The proposed method shows promising results in predicting three medication status objectively: Before Medication (AUC=0.95), After Medication (AUC=0.958), and Another Time (AUC=0.976) by examining patient-wise historical records with the attention weights learned through a Transformer model. We believe our method provides an innovative way for personalized remote health sensing in a timely and objective fashion which could benefit a broad range of similar applications.
Bi-Calibration Networks for Weakly-Supervised Video Representation Learning
Jun 21, 2022

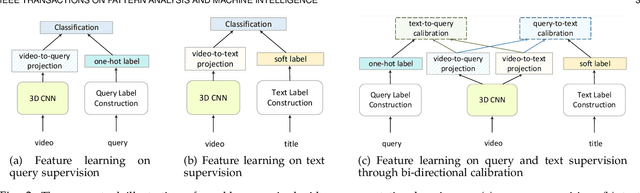
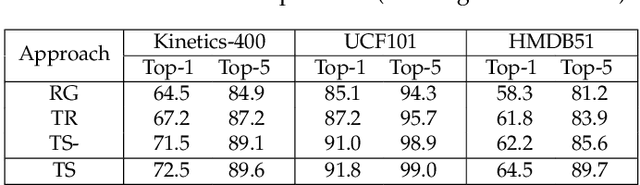
The leverage of large volumes of web videos paired with the searched queries or surrounding texts (e.g., title) offers an economic and extensible alternative to supervised video representation learning. Nevertheless, modeling such weakly visual-textual connection is not trivial due to query polysemy (i.e., many possible meanings for a query) and text isomorphism (i.e., same syntactic structure of different text). In this paper, we introduce a new design of mutual calibration between query and text to boost weakly-supervised video representation learning. Specifically, we present Bi-Calibration Networks (BCN) that novelly couples two calibrations to learn the amendment from text to query and vice versa. Technically, BCN executes clustering on all the titles of the videos searched by an identical query and takes the centroid of each cluster as a text prototype. The query vocabulary is built directly on query words. The video-to-text/video-to-query projections over text prototypes/query vocabulary then start the text-to-query or query-to-text calibration to estimate the amendment to query or text. We also devise a selection scheme to balance the two corrections. Two large-scale web video datasets paired with query and title for each video are newly collected for weakly-supervised video representation learning, which are named as YOVO-3M and YOVO-10M, respectively. The video features of BCN learnt on 3M web videos obtain superior results under linear model protocol on downstream tasks. More remarkably, BCN trained on the larger set of 10M web videos with further fine-tuning leads to 1.6%, and 1.8% gains in top-1 accuracy on Kinetics-400, and Something-Something V2 datasets over the state-of-the-art TDN, and ACTION-Net methods with ImageNet pre-training. Source code and datasets are available at \url{https://github.com/FuchenUSTC/BCN}.
Stand-Alone Inter-Frame Attention in Video Models
Jun 14, 2022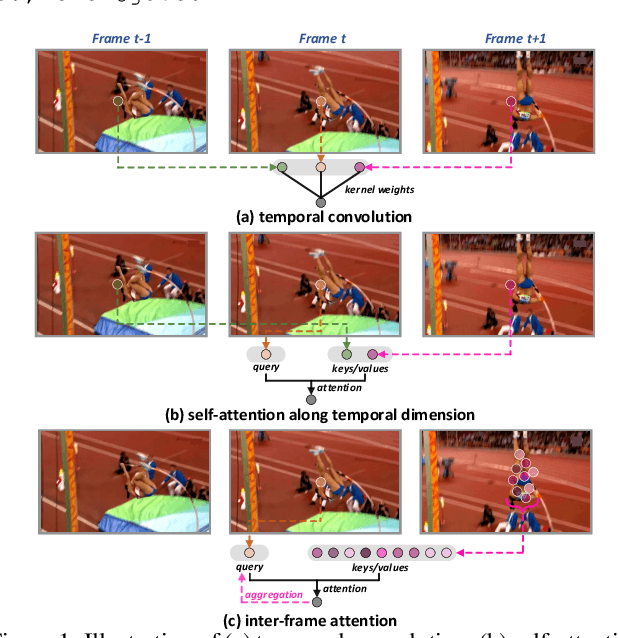
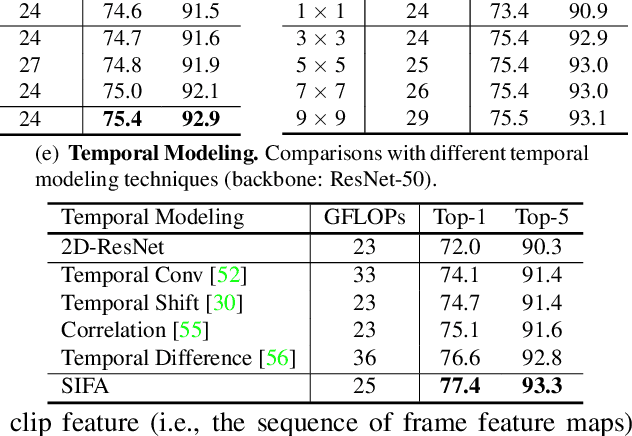
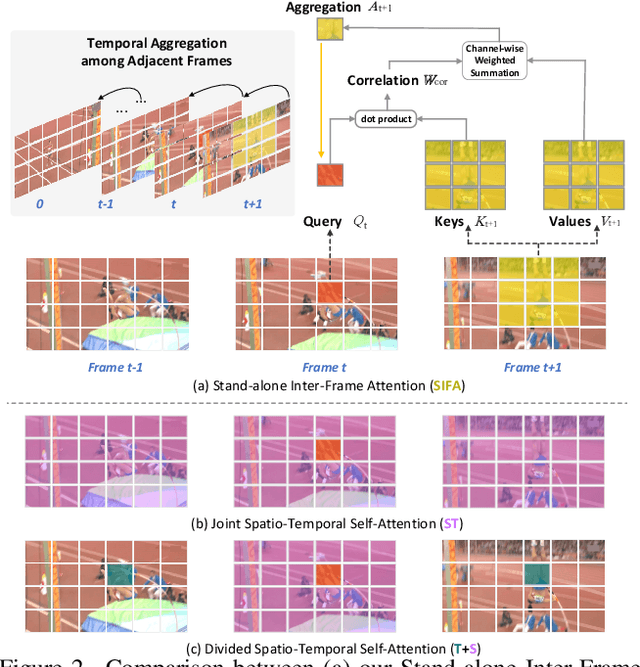
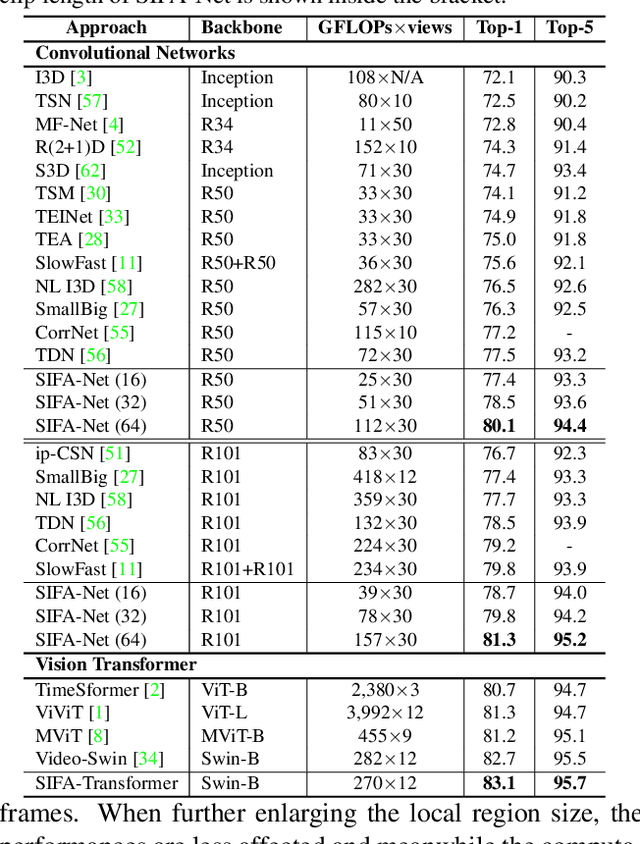
Motion, as the uniqueness of a video, has been critical to the development of video understanding models. Modern deep learning models leverage motion by either executing spatio-temporal 3D convolutions, factorizing 3D convolutions into spatial and temporal convolutions separately, or computing self-attention along temporal dimension. The implicit assumption behind such successes is that the feature maps across consecutive frames can be nicely aggregated. Nevertheless, the assumption may not always hold especially for the regions with large deformation. In this paper, we present a new recipe of inter-frame attention block, namely Stand-alone Inter-Frame Attention (SIFA), that novelly delves into the deformation across frames to estimate local self-attention on each spatial location. Technically, SIFA remoulds the deformable design via re-scaling the offset predictions by the difference between two frames. Taking each spatial location in the current frame as the query, the locally deformable neighbors in the next frame are regarded as the keys/values. Then, SIFA measures the similarity between query and keys as stand-alone attention to weighted average the values for temporal aggregation. We further plug SIFA block into ConvNets and Vision Transformer, respectively, to devise SIFA-Net and SIFA-Transformer. Extensive experiments conducted on four video datasets demonstrate the superiority of SIFA-Net and SIFA-Transformer as stronger backbones. More remarkably, SIFA-Transformer achieves an accuracy of 83.1% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/SIFA}.
Fine-tuning Pre-trained Language Models with Noise Stability Regularization
Jun 12, 2022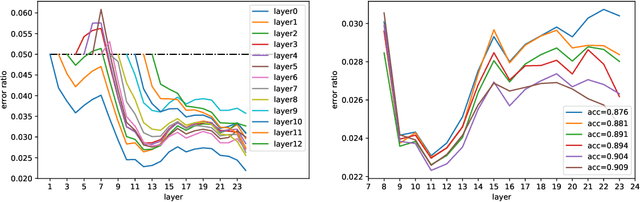
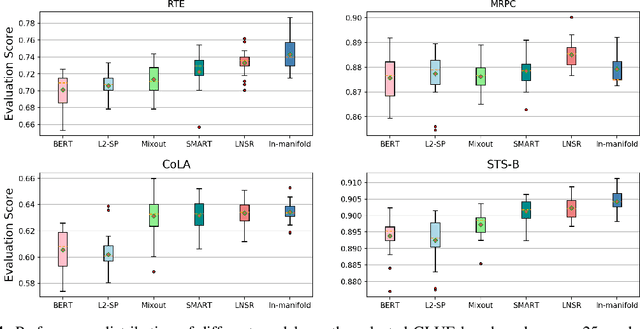
The advent of large-scale pre-trained language models has contributed greatly to the recent progress in natural language processing. Many state-of-the-art language models are first trained on a large text corpus and then fine-tuned on downstream tasks. Despite its recent success and wide adoption, fine-tuning a pre-trained language model often suffers from overfitting, which leads to poor generalizability due to the extremely high complexity of the model and the limited training samples from downstream tasks. To address this problem, we propose a novel and effective fine-tuning framework, named Layerwise Noise Stability Regularization (LNSR). Specifically, we propose to inject the standard Gaussian noise or In-manifold noise and regularize hidden representations of the fine-tuned model. We first provide theoretical analyses to support the efficacy of our method. We then demonstrate the advantages of the proposed method over other state-of-the-art algorithms including L2-SP, Mixout and SMART. While these previous works only verify the effectiveness of their methods on relatively simple text classification tasks, we also verify the effectiveness of our method on question answering tasks, where the target problem is much more difficult and more training examples are available. Furthermore, extensive experimental results indicate that the proposed algorithm can not only enhance the in-domain performance of the language models but also improve the domain generalization performance on out-of-domain data.
Automatic Relation-aware Graph Network Proliferation
May 31, 2022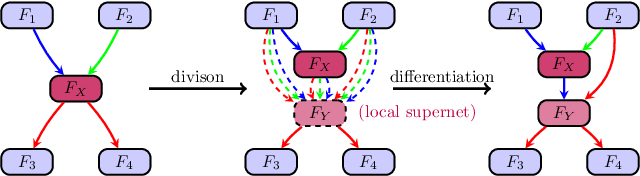
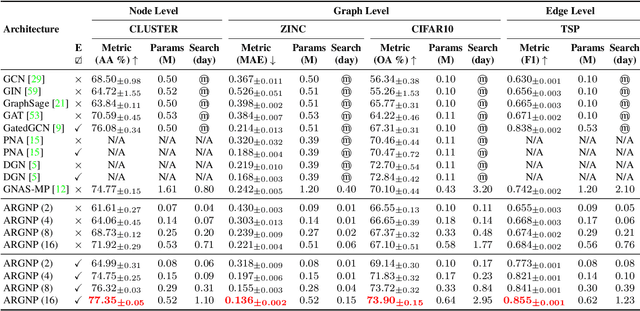
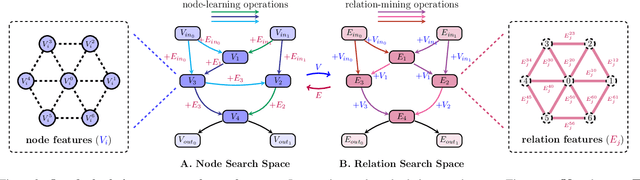
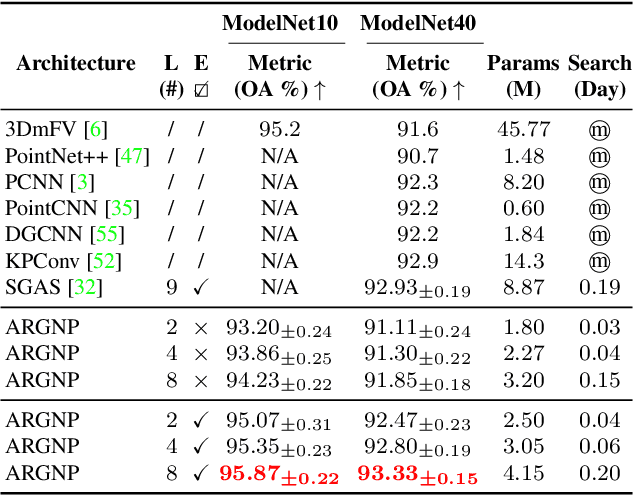
Graph neural architecture search has sparked much attention as Graph Neural Networks (GNNs) have shown powerful reasoning capability in many relational tasks. However, the currently used graph search space overemphasizes learning node features and neglects mining hierarchical relational information. Moreover, due to diverse mechanisms in the message passing, the graph search space is much larger than that of CNNs. This hinders the straightforward application of classical search strategies for exploring complicated graph search space. We propose Automatic Relation-aware Graph Network Proliferation (ARGNP) for efficiently searching GNNs with a relation-guided message passing mechanism. Specifically, we first devise a novel dual relation-aware graph search space that comprises both node and relation learning operations. These operations can extract hierarchical node/relational information and provide anisotropic guidance for message passing on a graph. Second, analogous to cell proliferation, we design a network proliferation search paradigm to progressively determine the GNN architectures by iteratively performing network division and differentiation. The experiments on six datasets for four graph learning tasks demonstrate that GNNs produced by our method are superior to the current state-of-the-art hand-crafted and search-based GNNs. Codes are available at https://github.com/phython96/ARGNP.
Localized Adversarial Domain Generalization
May 09, 2022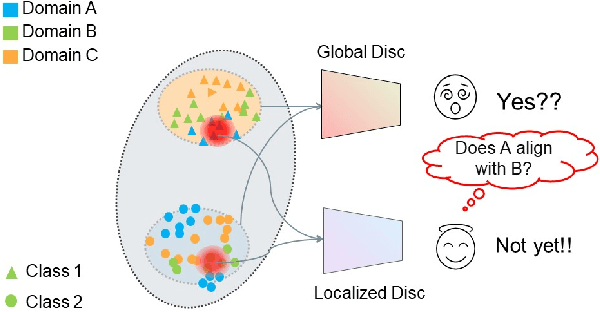
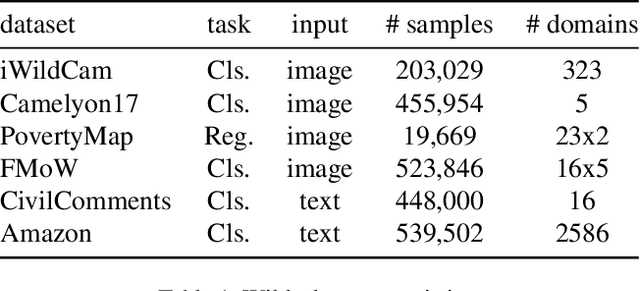
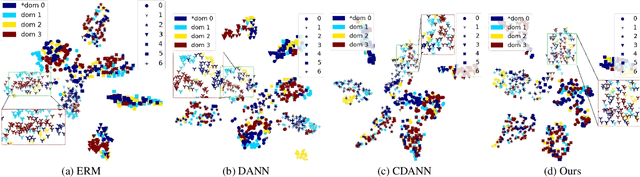
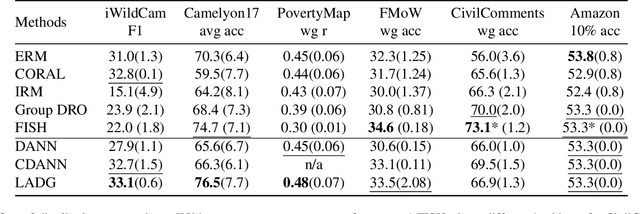
Deep learning methods can struggle to handle domain shifts not seen in training data, which can cause them to not generalize well to unseen domains. This has led to research attention on domain generalization (DG), which aims to the model's generalization ability to out-of-distribution. Adversarial domain generalization is a popular approach to DG, but conventional approaches (1) struggle to sufficiently align features so that local neighborhoods are mixed across domains; and (2) can suffer from feature space over collapse which can threaten generalization performance. To address these limitations, we propose localized adversarial domain generalization with space compactness maintenance~(LADG) which constitutes two major contributions. First, we propose an adversarial localized classifier as the domain discriminator, along with a principled primary branch. This constructs a min-max game whereby the aim of the featurizer is to produce locally mixed domains. Second, we propose to use a coding-rate loss to alleviate feature space over collapse. We conduct comprehensive experiments on the Wilds DG benchmark to validate our approach, where LADG outperforms leading competitors on most datasets.