 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
M2I2HA: Multi-modal Object Detection Based on Intra- and Inter-Modal Hypergraph Attention
Jan 24, 2026Recent advances in multi-modal detection have significantly improved detection accuracy in challenging environments (e.g., low light, overexposure). By integrating RGB with modalities such as thermal and depth, multi-modal fusion increases data redundancy and system robustness. However, significant challenges remain in effectively extracting task-relevant information both within and across modalities, as well as in achieving precise cross-modal alignment. While CNNs excel at feature extraction, they are limited by constrained receptive fields, strong inductive biases, and difficulty in capturing long-range dependencies. Transformer-based models offer global context but suffer from quadratic computational complexity and are confined to pairwise correlation modeling. Mamba and other State Space Models (SSMs), on the other hand, are hindered by their sequential scanning mechanism, which flattens 2D spatial structures into 1D sequences, disrupting topological relationships and limiting the modeling of complex higher-order dependencies. To address these issues, we propose a multi-modal perception network based on hypergraph theory called M2I2HA. Our architecture includes an Intra-Hypergraph Enhancement module to capture global many-to-many high-order relationships within each modality, and an Inter-Hypergraph Fusion module to align, enhance, and fuse cross-modal features by bridging configuration and spatial gaps between data sources. We further introduce a M2-FullPAD module to enable adaptive multi-level fusion of multi-modal enhanced features within the network, meanwhile enhancing data distribution and flow across the architecture. Extensive object detection experiments on multiple public datasets against baselines demonstrate that M2I2HA achieves state-of-the-art performance in multi-modal object detection tasks.
M2I2HA: A Multi-modal Object Detection Method Based on Intra- and Inter-Modal Hypergraph Attention
Jan 21, 2026Recent advances in multi-modal detection have significantly improved detection accuracy in challenging environments (e.g., low light, overexposure). By integrating RGB with modalities such as thermal and depth, multi-modal fusion increases data redundancy and system robustness. However, significant challenges remain in effectively extracting task-relevant information both within and across modalities, as well as in achieving precise cross-modal alignment. While CNNs excel at feature extraction, they are limited by constrained receptive fields, strong inductive biases, and difficulty in capturing long-range dependencies. Transformer-based models offer global context but suffer from quadratic computational complexity and are confined to pairwise correlation modeling. Mamba and other State Space Models (SSMs), on the other hand, are hindered by their sequential scanning mechanism, which flattens 2D spatial structures into 1D sequences, disrupting topological relationships and limiting the modeling of complex higher-order dependencies. To address these issues, we propose a multi-modal perception network based on hypergraph theory called M2I2HA. Our architecture includes an Intra-Hypergraph Enhancement module to capture global many-to-many high-order relationships within each modality, and an Inter-Hypergraph Fusion module to align, enhance, and fuse cross-modal features by bridging configuration and spatial gaps between data sources. We further introduce a M2-FullPAD module to enable adaptive multi-level fusion of multi-modal enhanced features within the network, meanwhile enhancing data distribution and flow across the architecture. Extensive object detection experiments on multiple public datasets against baselines demonstrate that M2I2HA achieves state-of-the-art performance in multi-modal object detection tasks.
FastStair: Learning to Run Up Stairs with Humanoid Robots
Jan 15, 2026Running up stairs is effortless for humans but remains extremely challenging for humanoid robots due to the simultaneous requirements of high agility and strict stability. Model-free reinforcement learning (RL) can generate dynamic locomotion, yet implicit stability rewards and heavy reliance on task-specific reward shaping tend to result in unsafe behaviors, especially on stairs; conversely, model-based foothold planners encode contact feasibility and stability structure, but enforcing their hard constraints often induces conservative motion that limits speed. We present FastStair, a planner-guided, multi-stage learning framework that reconciles these complementary strengths to achieve fast and stable stair ascent. FastStair integrates a parallel model-based foothold planner into the RL training loop to bias exploration toward dynamically feasible contacts and to pretrain a safety-focused base policy. To mitigate planner-induced conservatism and the discrepancy between low- and high-speed action distributions, the base policy was fine-tuned into speed-specialized experts and then integrated via Low-Rank Adaptation (LoRA) to enable smooth operation across the full commanded-speed range. We deploy the resulting controller on the Oli humanoid robot, achieving stable stair ascent at commanded speeds up to 1.65 m/s and traversing a 33-step spiral staircase (17 cm rise per step) in 12 s, demonstrating robust high-speed performance on long staircases. Notably, the proposed approach served as the champion solution in the Canton Tower Robot Run Up Competition.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
AKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Dec 29, 2025Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system's modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46$\times$ over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
DiffPixelFormer: Differential Pixel-Aware Transformer for RGB-D Indoor Scene Segmentation
Nov 17, 2025Indoor semantic segmentation is fundamental to computer vision and robotics, supporting applications such as autonomous navigation, augmented reality, and smart environments. Although RGB-D fusion leverages complementary appearance and geometric cues, existing methods often depend on computationally intensive cross-attention mechanisms and insufficiently model intra- and inter-modal feature relationships, resulting in imprecise feature alignment and limited discriminative representation. To address these challenges, we propose DiffPixelFormer, a differential pixel-aware Transformer for RGB-D indoor scene segmentation that simultaneously enhances intra-modal representations and models inter-modal interactions. At its core, the Intra-Inter Modal Interaction Block (IIMIB) captures intra-modal long-range dependencies via self-attention and models inter-modal interactions with the Differential-Shared Inter-Modal (DSIM) module to disentangle modality-specific and shared cues, enabling fine-grained, pixel-level cross-modal alignment. Furthermore, a dynamic fusion strategy balances modality contributions and fully exploits RGB-D information according to scene characteristics. Extensive experiments on the SUN RGB-D and NYUDv2 benchmarks demonstrate that DiffPixelFormer-L achieves mIoU scores of 54.28% and 59.95%, outperforming DFormer-L by 1.78% and 2.75%, respectively. Code is available at https://github.com/gongyan1/DiffPixelFormer.
Design and Control of a Perching Drone Inspired by the Prey-Capturing Mechanism of Venus Flytrap
Sep 16, 2025
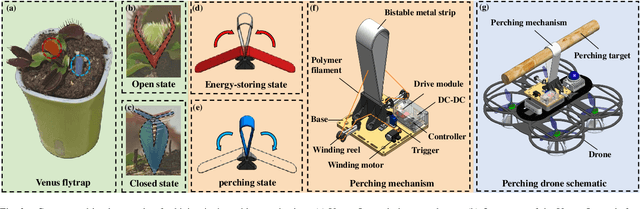
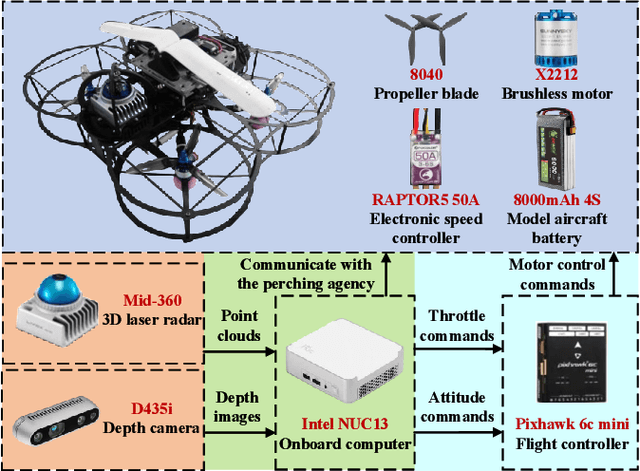
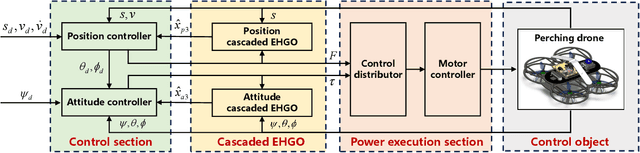
The endurance and energy efficiency of drones remain critical challenges in their design and operation. To extend mission duration, numerous studies explored perching mechanisms that enable drones to conserve energy by temporarily suspending flight. This paper presents a new perching drone that utilizes an active flexible perching mechanism inspired by the rapid predation mechanism of the Venus flytrap, achieving perching in less than 100 ms. The proposed system is designed for high-speed adaptability to the perching targets. The overall drone design is outlined, followed by the development and validation of the biomimetic perching structure. To enhance the system stability, a cascade extended high-gain observer (EHGO) based control method is developed, which can estimate and compensate for the external disturbance in real time. The experimental results demonstrate the adaptability of the perching structure and the superiority of the cascaded EHGO in resisting wind and perching disturbances.
GDLLM: A Global Distance-aware Modeling Approach Based on Large Language Models for Event Temporal Relation Extraction
Aug 28, 2025In Natural Language Processing(NLP), Event Temporal Relation Extraction (ETRE) is to recognize the temporal relations of two events. Prior studies have noted the importance of language models for ETRE. However, the restricted pre-trained knowledge of Small Language Models(SLMs) limits their capability to handle minority class relations in imbalanced classification datasets. For Large Language Models(LLMs), researchers adopt manually designed prompts or instructions, which may introduce extra noise, leading to interference with the model's judgment of the long-distance dependencies between events. To address these issues, we propose GDLLM, a Global Distance-aware modeling approach based on LLMs. We first present a distance-aware graph structure utilizing Graph Attention Network(GAT) to assist the LLMs in capturing long-distance dependency features. Additionally, we design a temporal feature learning paradigm based on soft inference to augment the identification of relations with a short-distance proximity band, which supplements the probabilistic information generated by LLMs into the multi-head attention mechanism. Since the global feature can be captured effectively, our framework substantially enhances the performance of minority relation classes and improves the overall learning ability. Experiments on two publicly available datasets, TB-Dense and MATRES, demonstrate that our approach achieves state-of-the-art (SOTA) performance.
Progressive Bird's Eye View Perception for Safety-Critical Autonomous Driving: A Comprehensive Survey
Aug 11, 2025Bird's-Eye-View (BEV) perception has become a foundational paradigm in autonomous driving, enabling unified spatial representations that support robust multi-sensor fusion and multi-agent collaboration. As autonomous vehicles transition from controlled environments to real-world deployment, ensuring the safety and reliability of BEV perception in complex scenarios - such as occlusions, adverse weather, and dynamic traffic - remains a critical challenge. This survey provides the first comprehensive review of BEV perception from a safety-critical perspective, systematically analyzing state-of-the-art frameworks and implementation strategies across three progressive stages: single-modality vehicle-side, multimodal vehicle-side, and multi-agent collaborative perception. Furthermore, we examine public datasets encompassing vehicle-side, roadside, and collaborative settings, evaluating their relevance to safety and robustness. We also identify key open-world challenges - including open-set recognition, large-scale unlabeled data, sensor degradation, and inter-agent communication latency - and outline future research directions, such as integration with end-to-end autonomous driving systems, embodied intelligence, and large language models.