 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGOS: Automated Functional Safety Requirement Synthesis for Embodied AI via Attribute-Guided Combinatorial Reasoning
Jan 30, 2026Ensuring functional safety is essential for the deployment of Embodied AI in complex open-world environments. However, traditional Hazard Analysis and Risk Assessment (HARA) methods struggle to scale in this domain. While HARA relies on enumerating risks for finite and pre-defined function lists, Embodied AI operates on open-ended natural language instructions, creating a challenge of combinatorial interaction risks. Whereas Large Language Models (LLMs) have emerged as a promising solution to this scalability challenge, they often lack physical grounding, yielding semantically superficial and incoherent hazard descriptions. To overcome these limitations, we propose a new framework ARGOS (AttRibute-Guided cOmbinatorial reaSoning), which bridges the gap between open-ended user instructions and concrete physical attributes. By dynamically decomposing entities from instructions into these fine-grained properties, ARGOS grounds LLM reasoning in causal risk factors to generate physically plausible hazard scenarios. It then instantiates abstract safety standards, such as ISO 13482, into context-specific Functional Safety Requirements (FSRs) by integrating these scenarios with robot capabilities. Extensive experiments validate that ARGOS produces high-quality FSRs and outperforms baselines in identifying long-tail risks. Overall, this work paves the way for systematic and grounded functional safety requirement generation, a critical step toward the safe industrial deployment of Embodied AI.
Beyond Parameter Finetuning: Test-Time Representation Refinement for Node Classification
Jan 29, 2026Graph Neural Networks frequently exhibit significant performance degradation in the out-of-distribution test scenario. While test-time training (TTT) offers a promising solution, existing Parameter Finetuning (PaFT) paradigm suffer from catastrophic forgetting, hindering their real-world applicability. We propose TTReFT, a novel Test-Time Representation FineTuning framework that transitions the adaptation target from model parameters to latent representations. Specifically, TTReFT achieves this through three key innovations: (1) uncertainty-guided node selection for specific interventions, (2) low-rank representation interventions that preserve pre-trained knowledge, and (3) an intervention-aware masked autoencoder that dynamically adjust masking strategy to accommodate the node selection scheme. Theoretically, we establish guarantees for TTReFT in OOD settings. Empirically, extensive experiments across five benchmark datasets demonstrate that TTReFT achieves consistent and superior performance. Our work establishes representation finetuning as a new paradigm for graph TTT, offering both theoretical grounding and immediate practical utility for real-world deployment.
Agentic Uncertainty Quantification
Jan 22, 2026Although AI agents have demonstrated impressive capabilities in long-horizon reasoning, their reliability is severely hampered by the ``Spiral of Hallucination,'' where early epistemic errors propagate irreversibly. Existing methods face a dilemma: uncertainty quantification (UQ) methods typically act as passive sensors, only diagnosing risks without addressing them, while self-reflection mechanisms suffer from continuous or aimless corrections. To bridge this gap, we propose a unified Dual-Process Agentic UQ (AUQ) framework that transforms verbalized uncertainty into active, bi-directional control signals. Our architecture comprises two complementary mechanisms: System 1 (Uncertainty-Aware Memory, UAM), which implicitly propagates verbalized confidence and semantic explanations to prevent blind decision-making; and System 2 (Uncertainty-Aware Reflection, UAR), which utilizes these explanations as rational cues to trigger targeted inference-time resolution only when necessary. This enables the agent to balance efficient execution and deep deliberation dynamically. Extensive experiments on closed-loop benchmarks and open-ended deep research tasks demonstrate that our training-free approach achieves superior performance and trajectory-level calibration. We believe this principled framework AUQ represents a significant step towards reliable agents.
From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantification in Large Language Models
Jan 22, 2026While Large Language Models (LLMs) show remarkable capabilities, their unreliability remains a critical barrier to deployment in high-stakes domains. This survey charts a functional evolution in addressing this challenge: the evolution of uncertainty from a passive diagnostic metric to an active control signal guiding real-time model behavior. We demonstrate how uncertainty is leveraged as an active control signal across three frontiers: in \textbf{advanced reasoning} to optimize computation and trigger self-correction; in \textbf{autonomous agents} to govern metacognitive decisions about tool use and information seeking; and in \textbf{reinforcement learning} to mitigate reward hacking and enable self-improvement via intrinsic rewards. By grounding these advancements in emerging theoretical frameworks like Bayesian methods and Conformal Prediction, we provide a unified perspective on this transformative trend. This survey provides a comprehensive overview, critical analysis, and practical design patterns, arguing that mastering the new trend of uncertainty is essential for building the next generation of scalable, reliable, and trustworthy AI.
Agentic Confidence Calibration
Jan 22, 2026AI agents are rapidly advancing from passive language models to autonomous systems executing complex, multi-step tasks. Yet their overconfidence in failure remains a fundamental barrier to deployment in high-stakes settings. Existing calibration methods, built for static single-turn outputs, cannot address the unique challenges of agentic systems, such as compounding errors along trajectories, uncertainty from external tools, and opaque failure modes. To address these challenges, we introduce, for the first time, the problem of Agentic Confidence Calibration and propose Holistic Trajectory Calibration (HTC), a novel diagnostic framework that extracts rich process-level features ranging from macro dynamics to micro stability across an agent's entire trajectory. Powered by a simple, interpretable model, HTC consistently surpasses strong baselines in both calibration and discrimination, across eight benchmarks, multiple LLMs, and diverse agent frameworks. Beyond performance, HTC delivers three essential advances: it provides interpretability by revealing the signals behind failure, enables transferability by applying across domains without retraining, and achieves generalization through a General Agent Calibrator (GAC) that achieves the best calibration (lowest ECE) on the out-of-domain GAIA benchmark. Together, these contributions establish a new process-centric paradigm for confidence calibration, providing a framework for diagnosing and enhancing the reliability of AI agents.
Multi-Modal Feature Fusion for Spatial Morphology Analysis of Traditional Villages via Hierarchical Graph Neural Networks
Oct 31, 2025



Villages areas hold significant importance in the study of human-land relationships. However, with the advancement of urbanization, the gradual disappearance of spatial characteristics and the homogenization of landscapes have emerged as prominent issues. Existing studies primarily adopt a single-disciplinary perspective to analyze villages spatial morphology and its influencing factors, relying heavily on qualitative analysis methods. These efforts are often constrained by the lack of digital infrastructure and insufficient data. To address the current research limitations, this paper proposes a Hierarchical Graph Neural Network (HGNN) model that integrates multi-source data to conduct an in-depth analysis of villages spatial morphology. The framework includes two types of nodes-input nodes and communication nodes-and two types of edges-static input edges and dynamic communication edges. By combining Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT), the proposed model efficiently integrates multimodal features under a two-stage feature update mechanism. Additionally, based on existing principles for classifying villages spatial morphology, the paper introduces a relational pooling mechanism and implements a joint training strategy across 17 subtypes. Experimental results demonstrate that this method achieves significant performance improvements over existing approaches in multimodal fusion and classification tasks. Additionally, the proposed joint optimization of all sub-types lifts mean accuracy/F1 from 0.71/0.83 (independent models) to 0.82/0.90, driven by a 6% gain for parcel tasks. Our method provides scientific evidence for exploring villages spatial patterns and generative logic.
MMPersuade: A Dataset and Evaluation Framework for Multimodal Persuasion
Oct 26, 2025As Large Vision-Language Models (LVLMs) are increasingly deployed in domains such as shopping, health, and news, they are exposed to pervasive persuasive content. A critical question is how these models function as persuadees-how and why they can be influenced by persuasive multimodal inputs. Understanding both their susceptibility to persuasion and the effectiveness of different persuasive strategies is crucial, as overly persuadable models may adopt misleading beliefs, override user preferences, or generate unethical or unsafe outputs when exposed to manipulative messages. We introduce MMPersuade, a unified framework for systematically studying multimodal persuasion dynamics in LVLMs. MMPersuade contributes (i) a comprehensive multimodal dataset that pairs images and videos with established persuasion principles across commercial, subjective and behavioral, and adversarial contexts, and (ii) an evaluation framework that quantifies both persuasion effectiveness and model susceptibility via third-party agreement scoring and self-estimated token probabilities on conversation histories. Our study of six leading LVLMs as persuadees yields three key insights: (i) multimodal inputs substantially increase persuasion effectiveness-and model susceptibility-compared to text alone, especially in misinformation scenarios; (ii) stated prior preferences decrease susceptibility, yet multimodal information maintains its persuasive advantage; and (iii) different strategies vary in effectiveness across contexts, with reciprocity being most potent in commercial and subjective contexts, and credibility and logic prevailing in adversarial contexts. By jointly analyzing persuasion effectiveness and susceptibility, MMPersuade provides a principled foundation for developing models that are robust, preference-consistent, and ethically aligned when engaging with persuasive multimodal content.
LaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
Jun 08, 2025Recent advances in multimodal foundation models unifying image understanding and generation have opened exciting avenues for tackling a wide range of vision-language tasks within a single framework. Despite progress, existing unified models typically require extensive pretraining and struggle to achieve the same level of performance compared to models dedicated to each task. Additionally, many of these models suffer from slow image generation speeds, limiting their practical deployment in real-time or resource-constrained settings. In this work, we propose Layerwise Timestep-Expert Flow-based Transformer (LaTtE-Flow), a novel and efficient architecture that unifies image understanding and generation within a single multimodal model. LaTtE-Flow builds upon powerful pretrained Vision-Language Models (VLMs) to inherit strong multimodal understanding capabilities, and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. LaTtE-Flow distributes the flow-matching process across specialized groups of Transformer layers, each responsible for a distinct subset of timesteps. This design significantly improves sampling efficiency by activating only a small subset of layers at each sampling timestep. To further enhance performance, we propose a Timestep-Conditioned Residual Attention mechanism for efficient information reuse across layers. Experiments demonstrate that LaTtE-Flow achieves strong performance on multimodal understanding tasks, while achieving competitive image generation quality with around 6x faster inference speed compared to recent unified multimodal models.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

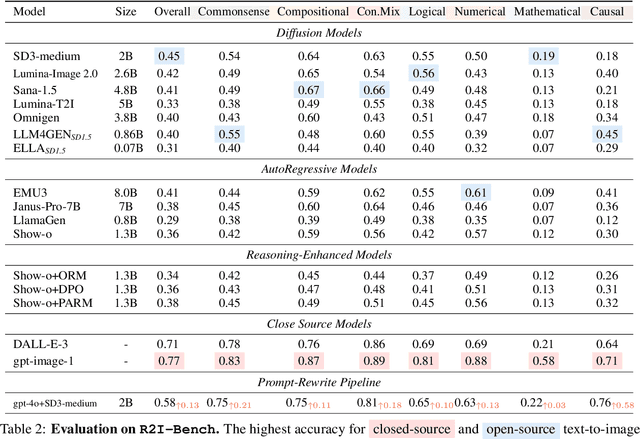

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
COB-GS: Clear Object Boundaries in 3DGS Segmentation Based on Boundary-Adaptive Gaussian Splitting
Mar 26, 2025Accurate object segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D segmentation based on 3D Gaussian Splatting (3DGS) struggles with accurately delineating object boundaries, as Gaussian primitives often span across object edges due to their inherent volume and the lack of semantic guidance during training. In order to tackle these challenges, we introduce Clear Object Boundaries for 3DGS Segmentation (COB-GS), which aims to improve segmentation accuracy by clearly delineating blurry boundaries of interwoven Gaussian primitives within the scene. Unlike existing approaches that remove ambiguous Gaussians and sacrifice visual quality, COB-GS, as a 3DGS refinement method, jointly optimizes semantic and visual information, allowing the two different levels to cooperate with each other effectively. Specifically, for the semantic guidance, we introduce a boundary-adaptive Gaussian splitting technique that leverages semantic gradient statistics to identify and split ambiguous Gaussians, aligning them closely with object boundaries. For the visual optimization, we rectify the degraded suboptimal texture of the 3DGS scene, particularly along the refined boundary structures. Experimental results show that COB-GS substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained model, yielding clear boundaries while preserving high visual quality. Code is available at https://github.com/ZestfulJX/COB-GS.