 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMPersuade: A Dataset and Evaluation Framework for Multimodal Persuasion
Oct 26, 2025As Large Vision-Language Models (LVLMs) are increasingly deployed in domains such as shopping, health, and news, they are exposed to pervasive persuasive content. A critical question is how these models function as persuadees-how and why they can be influenced by persuasive multimodal inputs. Understanding both their susceptibility to persuasion and the effectiveness of different persuasive strategies is crucial, as overly persuadable models may adopt misleading beliefs, override user preferences, or generate unethical or unsafe outputs when exposed to manipulative messages. We introduce MMPersuade, a unified framework for systematically studying multimodal persuasion dynamics in LVLMs. MMPersuade contributes (i) a comprehensive multimodal dataset that pairs images and videos with established persuasion principles across commercial, subjective and behavioral, and adversarial contexts, and (ii) an evaluation framework that quantifies both persuasion effectiveness and model susceptibility via third-party agreement scoring and self-estimated token probabilities on conversation histories. Our study of six leading LVLMs as persuadees yields three key insights: (i) multimodal inputs substantially increase persuasion effectiveness-and model susceptibility-compared to text alone, especially in misinformation scenarios; (ii) stated prior preferences decrease susceptibility, yet multimodal information maintains its persuasive advantage; and (iii) different strategies vary in effectiveness across contexts, with reciprocity being most potent in commercial and subjective contexts, and credibility and logic prevailing in adversarial contexts. By jointly analyzing persuasion effectiveness and susceptibility, MMPersuade provides a principled foundation for developing models that are robust, preference-consistent, and ethically aligned when engaging with persuasive multimodal content.
LaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
Jun 08, 2025Recent advances in multimodal foundation models unifying image understanding and generation have opened exciting avenues for tackling a wide range of vision-language tasks within a single framework. Despite progress, existing unified models typically require extensive pretraining and struggle to achieve the same level of performance compared to models dedicated to each task. Additionally, many of these models suffer from slow image generation speeds, limiting their practical deployment in real-time or resource-constrained settings. In this work, we propose Layerwise Timestep-Expert Flow-based Transformer (LaTtE-Flow), a novel and efficient architecture that unifies image understanding and generation within a single multimodal model. LaTtE-Flow builds upon powerful pretrained Vision-Language Models (VLMs) to inherit strong multimodal understanding capabilities, and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. LaTtE-Flow distributes the flow-matching process across specialized groups of Transformer layers, each responsible for a distinct subset of timesteps. This design significantly improves sampling efficiency by activating only a small subset of layers at each sampling timestep. To further enhance performance, we propose a Timestep-Conditioned Residual Attention mechanism for efficient information reuse across layers. Experiments demonstrate that LaTtE-Flow achieves strong performance on multimodal understanding tasks, while achieving competitive image generation quality with around 6x faster inference speed compared to recent unified multimodal models.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

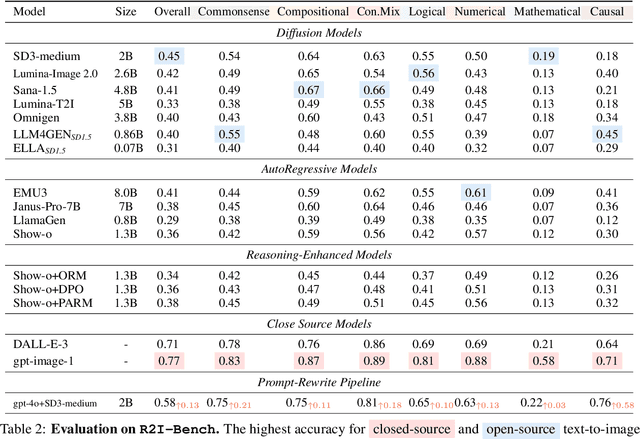

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
COB-GS: Clear Object Boundaries in 3DGS Segmentation Based on Boundary-Adaptive Gaussian Splitting
Mar 26, 2025Accurate object segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D segmentation based on 3D Gaussian Splatting (3DGS) struggles with accurately delineating object boundaries, as Gaussian primitives often span across object edges due to their inherent volume and the lack of semantic guidance during training. In order to tackle these challenges, we introduce Clear Object Boundaries for 3DGS Segmentation (COB-GS), which aims to improve segmentation accuracy by clearly delineating blurry boundaries of interwoven Gaussian primitives within the scene. Unlike existing approaches that remove ambiguous Gaussians and sacrifice visual quality, COB-GS, as a 3DGS refinement method, jointly optimizes semantic and visual information, allowing the two different levels to cooperate with each other effectively. Specifically, for the semantic guidance, we introduce a boundary-adaptive Gaussian splitting technique that leverages semantic gradient statistics to identify and split ambiguous Gaussians, aligning them closely with object boundaries. For the visual optimization, we rectify the degraded suboptimal texture of the 3DGS scene, particularly along the refined boundary structures. Experimental results show that COB-GS substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained model, yielding clear boundaries while preserving high visual quality. Code is available at https://github.com/ZestfulJX/COB-GS.
SCE: Scalable Consistency Ensembles Make Blackbox Large Language Model Generation More Reliable
Mar 13, 2025Large language models (LLMs) have demonstrated remarkable performance, yet their diverse strengths and weaknesses prevent any single LLM from achieving dominance across all tasks. Ensembling multiple LLMs is a promising approach to generate reliable responses but conventional ensembling frameworks suffer from high computational overheads. This work introduces Scalable Consistency Ensemble (SCE), an efficient framework for ensembling LLMs by prompting consistent outputs. The SCE framework systematically evaluates and integrates outputs to produce a cohesive result through two core components: SCE-CHECK, a mechanism that gauges the consistency between response pairs via semantic equivalence; and SCE-FUSION, which adeptly merges the highest-ranked consistent responses from SCE-CHECK, to optimize collective strengths and mitigating potential weaknesses. To improve the scalability with multiple inference queries, we further propose ``{You Only Prompt Once}'' (YOPO), a novel technique that reduces the inference complexity of pairwise comparison from quadratic to constant time. We perform extensive empirical evaluations on diverse benchmark datasets to demonstrate \methodName's effectiveness. Notably, the \saccheckcomponent outperforms conventional baselines with enhanced performance and a significant reduction in computational overhead.
Gradient-guided Attention Map Editing: Towards Efficient Contextual Hallucination Mitigation
Mar 11, 2025In tasks like summarization and open-book question answering (QA), Large Language Models (LLMs) often encounter "contextual hallucination", where they produce irrelevant or incorrect responses despite having access to accurate source information. This typically occurs because these models tend to prioritize self-generated content over the input context, causing them to disregard pertinent details. To address this challenge, we introduce a novel method called "Guided Attention Map Editing" (GAME), which dynamically adjusts attention maps to improve contextual relevance. During inference, GAME employs a trained classifier to identify attention maps prone to inducing hallucinations and executes targeted interventions. These interventions, guided by gradient-informed "edit directions'', strategically redistribute attention weights across various heads to effectively reduce hallucination. Comprehensive evaluations on challenging summarization and open-book QA tasks show that GAME consistently reduces hallucinations across a variety of open-source models. Specifically, GAME reduces hallucinations by 10% in the XSum summarization task while achieving a 7X speed-up in computational efficiency compared to the state-of-the-art baselines.
Towards Statistical Factuality Guarantee for Large Vision-Language Models
Feb 27, 2025Advancements in Large Vision-Language Models (LVLMs) have demonstrated promising performance in a variety of vision-language tasks involving image-conditioned free-form text generation. However, growing concerns about hallucinations in LVLMs, where the generated text is inconsistent with the visual context, are becoming a major impediment to deploying these models in applications that demand guaranteed reliability. In this paper, we introduce a framework to address this challenge, ConfLVLM, which is grounded on conformal prediction to achieve finite-sample distribution-free statistical guarantees on the factuality of LVLM output. This framework treats an LVLM as a hypothesis generator, where each generated text detail (or claim) is considered an individual hypothesis. It then applies a statistical hypothesis testing procedure to verify each claim using efficient heuristic uncertainty measures to filter out unreliable claims before returning any responses to users. We conduct extensive experiments covering three representative application domains, including general scene understanding, medical radiology report generation, and document understanding. Remarkably, ConfLVLM reduces the error rate of claims generated by LLaVa-1.5 for scene descriptions from 87.8\% to 10.0\% by filtering out erroneous claims with a 95.3\% true positive rate. Our results further demonstrate that ConfLVLM is highly flexible, and can be applied to any black-box LVLMs paired with any uncertainty measure for any image-conditioned free-form text generation task while providing a rigorous guarantee on controlling the risk of hallucination.
Automatic Prompt Optimization via Heuristic Search: A Survey
Feb 26, 2025



Recent advances in Large Language Models have led to remarkable achievements across a variety of Natural Language Processing tasks, making prompt engineering increasingly central to guiding model outputs. While manual methods can be effective, they typically rely on intuition and do not automatically refine prompts over time. In contrast, automatic prompt optimization employing heuristic-based search algorithms can systematically explore and improve prompts with minimal human oversight. This survey proposes a comprehensive taxonomy of these methods, categorizing them by where optimization occurs, what is optimized, what criteria drive the optimization, which operators generate new prompts, and which iterative search algorithms are applied. We further highlight specialized datasets and tools that support and accelerate automated prompt refinement. We conclude by discussing key open challenges pointing toward future opportunities for more robust and versatile LLM applications.
From System 1 to System 2: A Survey of Reasoning Large Language Models
Feb 25, 2025Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
Smaller But Better: Unifying Layout Generation with Smaller Large Language Models
Feb 19, 2025We propose LGGPT, an LLM-based model tailored for unified layout generation. First, we propose Arbitrary Layout Instruction (ALI) and Universal Layout Response (ULR) as the uniform I/O template. ALI accommodates arbitrary layout generation task inputs across multiple layout domains, enabling LGGPT to unify both task-generic and domain-generic layout generation hitherto unexplored. Collectively, ALI and ULR boast a succinct structure that forgoes superfluous tokens typically found in existing HTML-based formats, facilitating efficient instruction tuning and boosting unified generation performance. In addition, we propose an Interval Quantization Encoding (IQE) strategy that compresses ALI into a more condensed structure. IQE precisely preserves valid layout clues while eliminating the less informative placeholders, facilitating LGGPT to capture complex and variable layout generation conditions during the unified training process. Experimental results demonstrate that LGGPT achieves superior or on par performance compared to existing methods. Notably, LGGPT strikes a prominent balance between proficiency and efficiency with a compact 1.5B parameter LLM, which beats prior 7B or 175B models even in the most extensive and challenging unified scenario. Furthermore, we underscore the necessity of employing LLMs for unified layout generation and suggest that 1.5B could be an optimal parameter size by comparing LLMs of varying scales. Code is available at https://github.com/NiceRingNode/LGGPT.