 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edges3: You Don't Need That Much Data to Train a Search Agent via RL
May 20, 2025Retrieval-augmented generation (RAG) systems empower large language models (LLMs) to access external knowledge during inference. Recent advances have enabled LLMs to act as search agents via reinforcement learning (RL), improving information acquisition through multi-turn interactions with retrieval engines. However, existing approaches either optimize retrieval using search-only metrics (e.g., NDCG) that ignore downstream utility or fine-tune the entire LLM to jointly reason and retrieve-entangling retrieval with generation and limiting the real search utility and compatibility with frozen or proprietary models. In this work, we propose s3, a lightweight, model-agnostic framework that decouples the searcher from the generator and trains the searcher using a Gain Beyond RAG reward: the improvement in generation accuracy over naive RAG. s3 requires only 2.4k training samples to outperform baselines trained on over 70x more data, consistently delivering stronger downstream performance across six general QA and five medical QA benchmarks.
LLM-Based Compact Reranking with Document Features for Scientific Retrieval
May 19, 2025



Scientific retrieval is essential for advancing academic discovery. Within this process, document reranking plays a critical role by refining first-stage retrieval results. However, large language model (LLM) listwise reranking faces unique challenges in the scientific domain. First-stage retrieval is often suboptimal in the scientific domain, so relevant documents are ranked lower. Moreover, conventional listwise reranking uses the full text of candidate documents in the context window, limiting the number of candidates that can be considered. As a result, many relevant documents are excluded before reranking, which constrains overall retrieval performance. To address these challenges, we explore compact document representations based on semantic features such as categories, sections, and keywords, and propose a training-free, model-agnostic reranking framework for scientific retrieval called CoRank. The framework involves three stages: (i) offline extraction of document-level features, (ii) coarse reranking using these compact representations, and (iii) fine-grained reranking on full texts of the top candidates from stage (ii). This hybrid design provides a high-level abstraction of document semantics, expands candidate coverage, and retains critical details required for precise ranking. Experiments on LitSearch and CSFCube show that CoRank significantly improves reranking performance across different LLM backbones, increasing nDCG@10 from 32.0 to 39.7. Overall, these results highlight the value of information extraction for reranking in scientific retrieval.
Pave Your Own Path: Graph Gradual Domain Adaptation on Fused Gromov-Wasserstein Geodesics
May 19, 2025



Graph neural networks, despite their impressive performance, are highly vulnerable to distribution shifts on graphs. Existing graph domain adaptation (graph DA) methods often implicitly assume a \textit{mild} shift between source and target graphs, limiting their applicability to real-world scenarios with \textit{large} shifts. Gradual domain adaptation (GDA) has emerged as a promising approach for addressing large shifts by gradually adapting the source model to the target domain via a path of unlabeled intermediate domains. Existing GDA methods exclusively focus on independent and identically distributed (IID) data with a predefined path, leaving their extension to \textit{non-IID graphs without a given path} an open challenge. To bridge this gap, we present Gadget, the first GDA framework for non-IID graph data. First (\textit{theoretical foundation}), the Fused Gromov-Wasserstein (FGW) distance is adopted as the domain discrepancy for non-IID graphs, based on which, we derive an error bound revealing that the target domain error is proportional to the length of the path. Second (\textit{optimal path}), guided by the error bound, we identify the FGW geodesic as the optimal path, which can be efficiently generated by our proposed algorithm. The generated path can be seamlessly integrated with existing graph DA methods to handle large shifts on graphs, improving state-of-the-art graph DA methods by up to 6.8\% in node classification accuracy on real-world datasets.
mCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025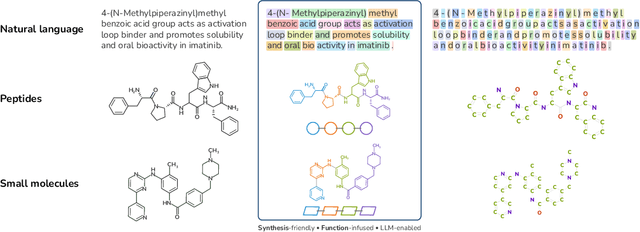
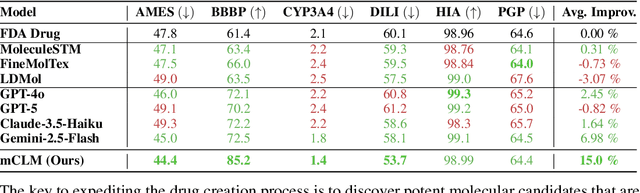
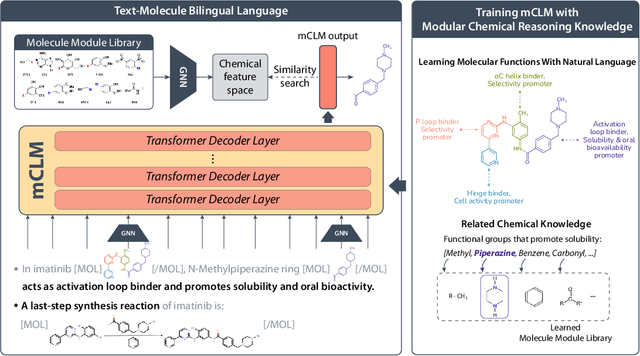
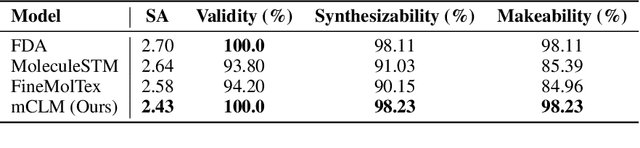
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.
DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation
May 12, 2025Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with external knowledge retrieval, making them highly effective for knowledge-intensive tasks. A crucial but often under-explored component of these systems is the reranker, which refines retrieved documents to enhance generation quality and explainability. The challenge of selecting the optimal number of documents (k) remains unsolved: too few may omit critical information, while too many introduce noise and inefficiencies. Although recent studies have explored LLM-based rerankers, they primarily leverage internal model knowledge and overlook the rich supervisory signals that LLMs can provide, such as using response quality as feedback for optimizing reranking decisions. In this paper, we propose DynamicRAG, a novel RAG framework where the reranker dynamically adjusts both the order and number of retrieved documents based on the query. We model the reranker as an agent optimized through reinforcement learning (RL), using rewards derived from LLM output quality. Across seven knowledge-intensive datasets, DynamicRAG demonstrates superior performance, achieving state-of-the-art results. The model, data and code are available at https://github.com/GasolSun36/DynamicRAG
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
GTR: Graph-Table-RAG for Cross-Table Question Answering
Apr 03, 2025Beyond pure text, a substantial amount of knowledge is stored in tables. In real-world scenarios, user questions often require retrieving answers that are distributed across multiple tables. GraphRAG has recently attracted much attention for enhancing LLMs' reasoning capabilities by organizing external knowledge to address ad-hoc and complex questions, exemplifying a promising direction for cross-table question answering. In this paper, to address the current gap in available data, we first introduce a multi-table benchmark, MutliTableQA, comprising 60k tables and 25k user queries collected from real-world sources. Then, we propose the first Graph-Table-RAG framework, namely GTR, which reorganizes table corpora into a heterogeneous graph, employs a hierarchical coarse-to-fine retrieval process to extract the most relevant tables, and integrates graph-aware prompting for downstream LLMs' tabular reasoning. Extensive experiments show that GTR exhibits superior cross-table question-answering performance while maintaining high deployment efficiency, demonstrating its real-world practical applicability.
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Mar 12, 2025Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Retrieval augmentation and tool-use training approaches where a search engine is treated as a tool lack complex multi-turn retrieval flexibility or require large-scale supervised data. Prompting advanced LLMs with reasoning capabilities during inference to use search engines is not optimal, since the LLM does not learn how to optimally interact with the search engine. This paper introduces Search-R1, an extension of the DeepSeek-R1 model where the LLM learns -- solely through reinforcement learning (RL) -- to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM rollouts with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 26% (Qwen2.5-7B), 21% (Qwen2.5-3B), and 10% (LLaMA3.2-3B) over SOTA baselines. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
Multimodal Search in Chemical Documents and Reactions
Feb 24, 2025We present a multimodal search tool that facilitates retrieval of chemical reactions, molecular structures, and associated text from scientific literature. Queries may combine molecular diagrams, textual descriptions, and reaction data, allowing users to connect different representations of chemical information. To support this, the indexing process includes chemical diagram extraction and parsing, extraction of reaction data from text in tabular form, and cross-modal linking of diagrams and their mentions in text. We describe the system's architecture, key functionalities, and retrieval process, along with expert assessments of the system. This demo highlights the workflow and technical components of the search system.
Tree-of-Debate: Multi-Persona Debate Trees Elicit Critical Thinking for Scientific Comparative Analysis
Feb 20, 2025With the exponential growth of research facilitated by modern technology and improved accessibility, scientific discoveries have become increasingly fragmented within and across fields. This makes it challenging to assess the significance, novelty, incremental findings, and equivalent ideas between related works, particularly those from different research communities. Large language models (LLMs) have recently demonstrated strong quantitative and qualitative reasoning abilities, and multi-agent LLM debates have shown promise in handling complex reasoning tasks by exploring diverse perspectives and reasoning paths. Inspired by this, we introduce Tree-of-Debate (ToD), a framework which converts scientific papers into LLM personas that debate their respective novelties. To emphasize structured, critical reasoning rather than focusing solely on outcomes, ToD dynamically constructs a debate tree, enabling fine-grained analysis of independent novelty arguments within scholarly articles. Through experiments on scientific literature across various domains, evaluated by expert researchers, we demonstrate that ToD generates informative arguments, effectively contrasts papers, and supports researchers in their literature review.