 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRIUS-SQL: Anchoring Multi-Candidate Text-to-SQL in Execution Feedback
May 31, 2026Text-to-SQL on complex schemas is unreliable on a single pass, so recent systems generate multiple SQL candidates and let voting filter out errors. Yet voting alone is not enough, because the multi-candidate recipe has three coupled weaknesses: 1) sampling more from a single generator produces increasingly redundant candidates, 2) existing pipelines apply one generic correction to every non-clean execution result, while runtime errors, timeouts, and empty results each indicate a different distance from correctness, and 3) existing selectors rely on a single angle such as result-majority voting or pairwise SQL comparison, missing what other angles would have caught. We present SIRIUS-SQL, which addresses all three weaknesses. A difficulty-smoothing RL recipe trains SIRIUS-32B to generate diverse executable SQL candidates, paired with a generalist LLM that fills in gaps left by the specialist. An execution-grounded lifecycle classifies each outcome and applies targeted repair before candidates re-enter the pool. A confidence-gated hybrid selector combines execution-result agreement with pairwise SQL-form judgment, escalating only near-tied cases to a deterministic structural check. SIRIUS-SQL reaches 75.88% on BIRD dev and 91.20% on SPIDER test. Two of three generalist pairings surpass Agentar-Scale-SQL, the strongest published multi-candidate system on BIRD dev.
Efficient Agentic Reinforcement Learning with On-Policy Intrinsic Knowledge Boundary Enhancement
May 26, 2026Agentic reinforcement learning (RL) has proven effective for training LLM-based agents with external tool-use capabilities. However, we identify that agentic RL training induces increasing redundant tool calls and blurs the model's intrinsic knowledge boundary, where the model fails to distinguish when tools are needed versus when parametric knowledge suffices. Existing solutions based on reward shaping create coarse-grained optimization targets that tend to incentivize indiscriminate tool-call suppression, leading to reward hacking. In this paper, we propose AKBE (Agentic Knowledge Boundary Enhancement), an on-policy method that dynamically probes the model's intrinsic knowledge boundary through dual-path (with-tool and no-tool) rollouts during training. We define the knowledge boundary as the per-instance determination of whether tools are required and the minimum tool calls necessary. By comparing correctness across paths, AKBE categorizes trajectories and constructs targeted supervisory signals that guide efficient tool-use patterns for each question. These signals are integrated seamlessly into the agentic RL training loop. Experiments on seven QA benchmarks demonstrate that AKBE improves task accuracy by +1.85 on average and reduces tool calls by 18% over standard agentic RL, yielding 25% higher tool productivity without any accuracy-efficiency trade-off. Further analysis suggests its plug-and-play compatibility across different RL algorithms and the mechanism of each signal category. Our code is available at https://github.com/CuSO4-Chen/AKBE.
A$^2$TGPO: Agentic Turn-Group Policy Optimization with Adaptive Turn-level Clipping
May 07, 2026Reinforcement learning for agentic large language models (LLMs) typically relies on a sparse, trajectory-level outcome reward, making it difficult to evaluate the contribution of individual tool-calls within multi-turn interactions. Existing approaches to such process credit assignment either depend on separate external process reward models that introduce additional consumption, or tree-based structural rollout that merely redistributes the outcome signal while constraining trajectory diversity. A promising alternative leverages the per-turn change in the policy's predicted probability of the ground-truth, termed Information Gain (IG), as an intrinsic process signal without an external evaluator. However, prior work on leveraging IG signals within the RL training loop faces three systematic challenges: normalizing across turns that face heterogeneous positional contexts can distort the relative standing of individual turns, accumulating a variable number of terms causes advantage magnitudes to drift with trajectory depth, and a fixed clipping range governs policy updates identically for turns with vastly different IG signals. In this paper, we propose A$^2$TGPO (Agentic Turn-Group Policy Optimization with Adaptive Turn-level Clipping), which retains IG as the intrinsic signal but re-designs how it is normalized, accumulated, and consumed: (i) turn-group normalization: normalizes IG within each (prompt, turn-index) group so that each turn is compared only against peers at the same interaction depth; (ii) variance-rescaled discounted accumulation: divides cumulative normalized IG by square root of accumulated terms to keep advantage magnitudes comparable across turn positions; and (iii) adaptive turn-level clipping: modulates each turn's clipping range based on its normalized IG, widening the update region for informative turns and narrowing it for uninformative ones.
Multimodal Search in Chemical Documents and Reactions
Feb 24, 2025We present a multimodal search tool that facilitates retrieval of chemical reactions, molecular structures, and associated text from scientific literature. Queries may combine molecular diagrams, textual descriptions, and reaction data, allowing users to connect different representations of chemical information. To support this, the indexing process includes chemical diagram extraction and parsing, extraction of reaction data from text in tabular form, and cross-modal linking of diagrams and their mentions in text. We describe the system's architecture, key functionalities, and retrieval process, along with expert assessments of the system. This demo highlights the workflow and technical components of the search system.
Multiple resolution residual network for automatic thoracic organs-at-risk segmentation from CT
May 31, 2020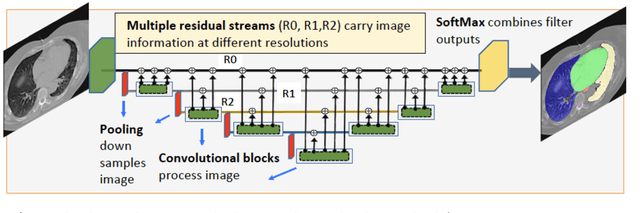
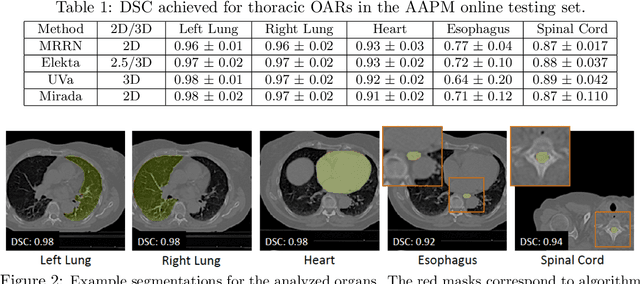
We implemented and evaluated a multiple resolution residual network (MRRN) for multiple normal organs-at-risk (OAR) segmentation from computed tomography (CT) images for thoracic radiotherapy treatment (RT) planning. Our approach simultaneously combines feature streams computed at multiple image resolutions and feature levels through residual connections. The feature streams at each level are updated as the images are passed through various feature levels. We trained our approach using 206 thoracic CT scans of lung cancer patients with 35 scans held out for validation to segment the left and right lungs, heart, esophagus, and spinal cord. This approach was tested on 60 CT scans from the open-source AAPM Thoracic Auto-Segmentation Challenge dataset. Performance was measured using the Dice Similarity Coefficient (DSC). Our approach outperformed the best-performing method in the grand challenge for hard-to-segment structures like the esophagus and achieved comparable results for all other structures. Median DSC using our method was 0.97 (interquartile range [IQR]: 0.97-0.98) for the left and right lungs, 0.93 (IQR: 0.93-0.95) for the heart, 0.78 (IQR: 0.76-0.80) for the esophagus, and 0.88 (IQR: 0.86-0.89) for the spinal cord.