 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Guided Topic Discovery with Out-of-Vocabulary Seeds
May 04, 2022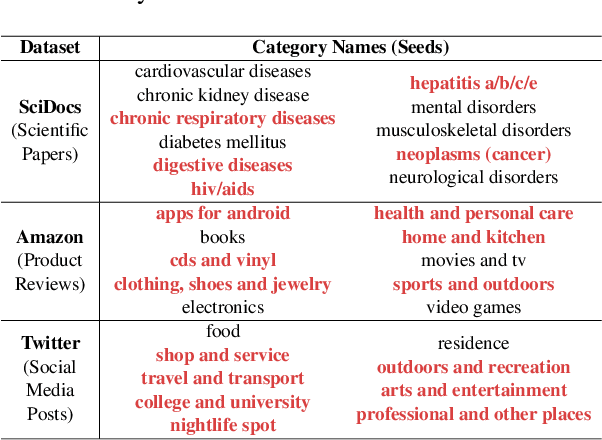
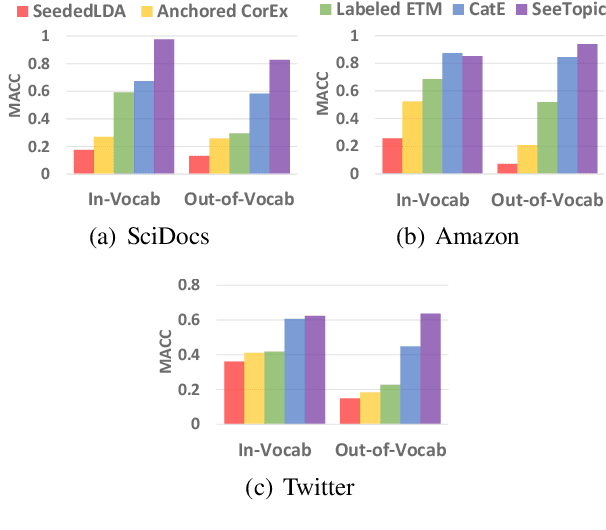
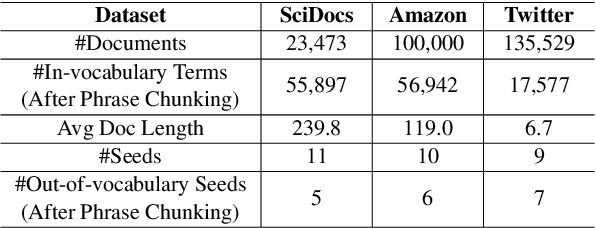
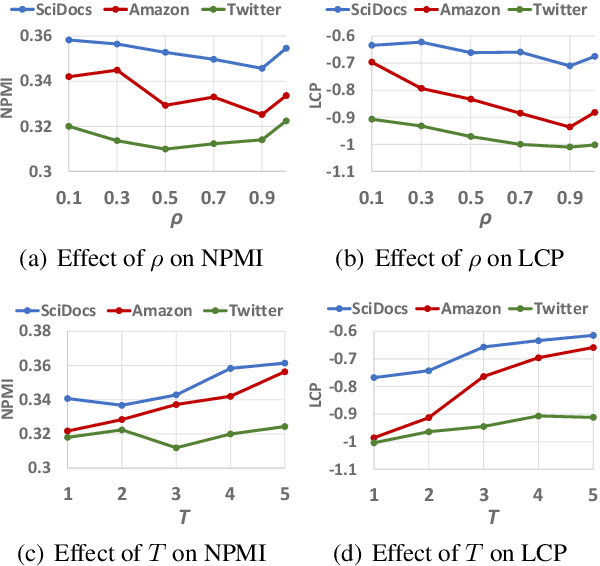
Discovering latent topics from text corpora has been studied for decades. Many existing topic models adopt a fully unsupervised setting, and their discovered topics may not cater to users' particular interests due to their inability of leveraging user guidance. Although there exist seed-guided topic discovery approaches that leverage user-provided seeds to discover topic-representative terms, they are less concerned with two factors: (1) the existence of out-of-vocabulary seeds and (2) the power of pre-trained language models (PLMs). In this paper, we generalize the task of seed-guided topic discovery to allow out-of-vocabulary seeds. We propose a novel framework, named SeeTopic, wherein the general knowledge of PLMs and the local semantics learned from the input corpus can mutually benefit each other. Experiments on three real datasets from different domains demonstrate the effectiveness of SeeTopic in terms of topic coherence, accuracy, and diversity.
OA-Mine: Open-World Attribute Mining for E-Commerce Products with Weak Supervision
Apr 29, 2022
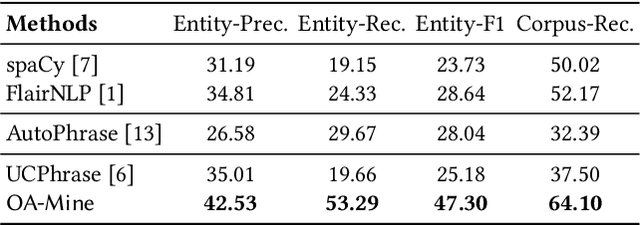
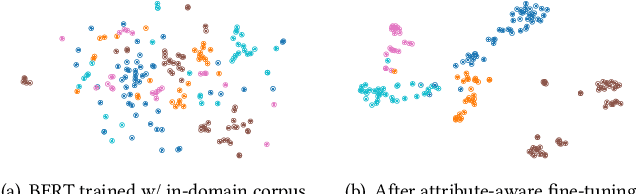
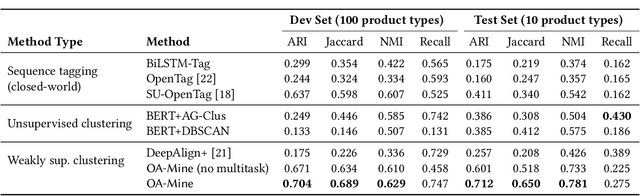
Automatic extraction of product attributes from their textual descriptions is essential for online shopper experience. One inherent challenge of this task is the emerging nature of e-commerce products -- we see new types of products with their unique set of new attributes constantly. Most prior works on this matter mine new values for a set of known attributes but cannot handle new attributes that arose from constantly changing data. In this work, we study the attribute mining problem in an open-world setting to extract novel attributes and their values. Instead of providing comprehensive training data, the user only needs to provide a few examples for a few known attribute types as weak supervision. We propose a principled framework that first generates attribute value candidates and then groups them into clusters of attributes. The candidate generation step probes a pre-trained language model to extract phrases from product titles. Then, an attribute-aware fine-tuning method optimizes a multitask objective and shapes the language model representation to be attribute-discriminative. Finally, we discover new attributes and values through the self-ensemble of our framework, which handles the open-world challenge. We run extensive experiments on a large distantly annotated development set and a gold standard human-annotated test set that we collected. Our model significantly outperforms strong baselines and can generalize to unseen attributes and product types.
Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Apr 07, 2022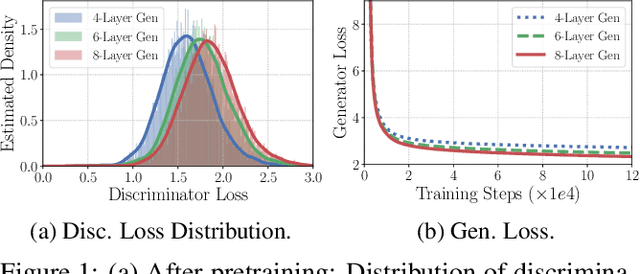
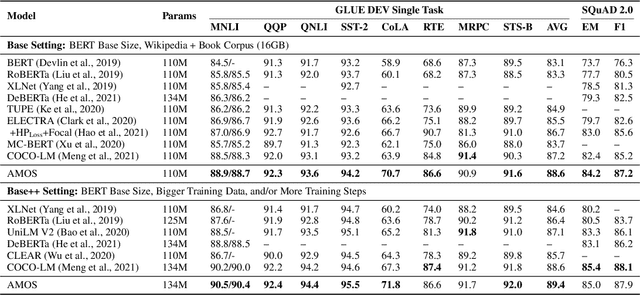
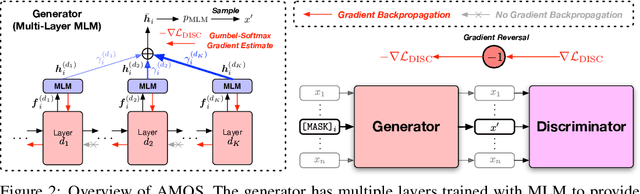
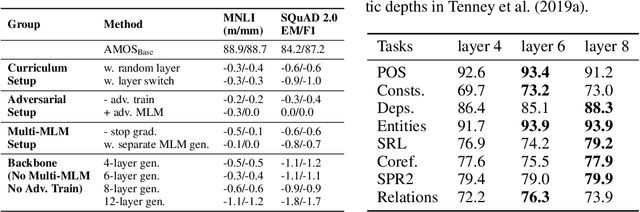
We present a new framework AMOS that pretrains text encoders with an Adversarial learning curriculum via a Mixture Of Signals from multiple auxiliary generators. Following ELECTRA-style pretraining, the main encoder is trained as a discriminator to detect replaced tokens generated by auxiliary masked language models (MLMs). Different from ELECTRA which trains one MLM as the generator, we jointly train multiple MLMs of different sizes to provide training signals at various levels of difficulty. To push the discriminator to learn better with challenging replaced tokens, we learn mixture weights over the auxiliary MLMs' outputs to maximize the discriminator loss by backpropagating the gradient from the discriminator via Gumbel-Softmax. For better pretraining efficiency, we propose a way to assemble multiple MLMs into one unified auxiliary model. AMOS outperforms ELECTRA and recent state-of-the-art pretrained models by about 1 point on the GLUE benchmark for BERT base-sized models.
Shift-Robust Node Classification via Graph Adversarial Clustering
Mar 07, 2022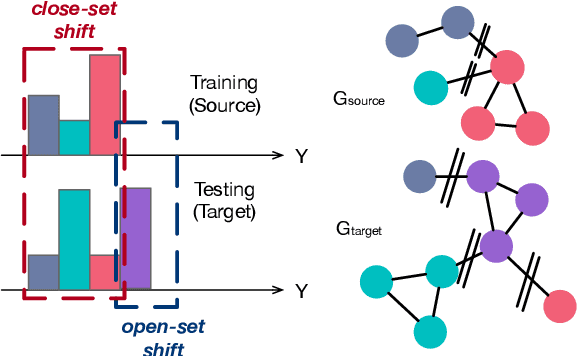
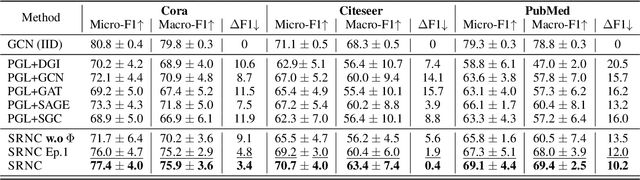
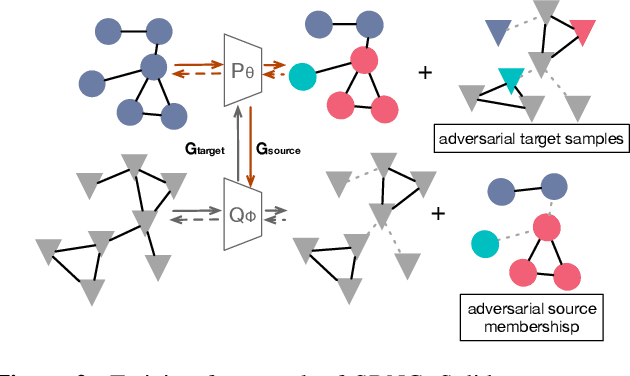
Graph Neural Networks (GNNs) are de facto node classification models in graph structured data. However, during testing-time, these algorithms assume no data shift, i.e., $\Pr_\text{train}(X,Y) = \Pr_\text{test}(X,Y)$. Domain adaption methods can be adopted for data shift, yet most of them are designed to only encourage similar feature distribution between source and target data. Conditional shift on classes can still affect such adaption. Fortunately, graph yields graph homophily across different data distributions. In response, we propose Shift-Robust Node Classification (SRNC) to address these limitations. We introduce an unsupervised cluster GNN on target graph to group the similar nodes by graph homophily. An adversarial loss with label information on source graph is used upon clustering objective. Then a shift-robust classifier is optimized on training graph and adversarial samples on target graph, which are generated by cluster GNN. We conduct experiments on both open-set shift and representation-shift, which demonstrates the superior accuracy of SRNC on generalizing to test graph with data shift. SRNC is consistently better than previous SoTA domain adaption algorithm on graph that progressively use model predictions on target graph for training.
PILED: An Identify-and-Localize Framework for Few-Shot Event Detection
Feb 15, 2022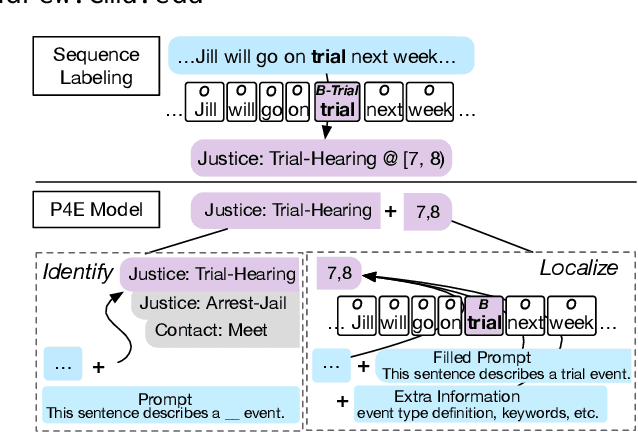
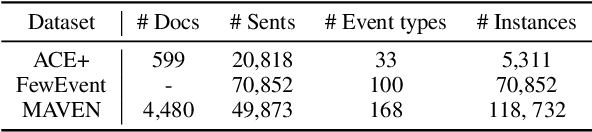
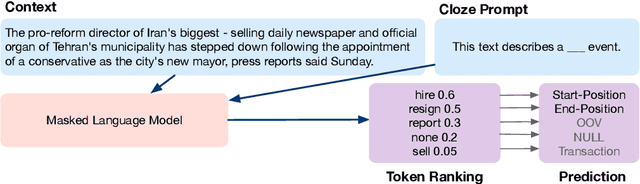
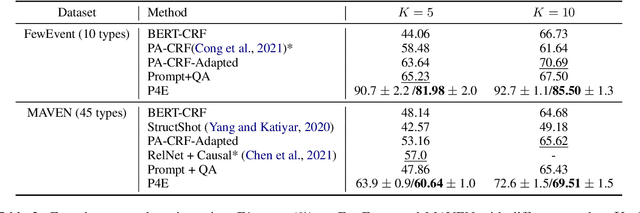
Practical applications of event extraction systems have long been hindered by their need for heavy human annotation. In order to scale up to new domains and event types, models must learn to cope with limited supervision, as in few-shot learning settings. To this end, the major challenge is to let the model master the semantics of event types, without requiring abundant event mention annotations. In our study, we employ cloze prompts to elicit event-related knowledge from pretrained language models and further use event definitions and keywords to pinpoint the trigger word. By formulating the event detection task as an identify-then-localize procedure, we minimize the number of type-specific parameters, enabling our model to quickly adapt to event detection tasks for new types. Experiments on three event detection benchmark datasets (ACE, FewEvent, MAVEN) show that our proposed method performs favorably under fully supervised settings and surpasses existing few-shot methods by 21% F1 on the FewEvent dataset and 20% on the MAVEN dataset when only 5 examples are provided for each event type.
Metadata-Induced Contrastive Learning for Zero-Shot Multi-Label Text Classification
Feb 11, 2022
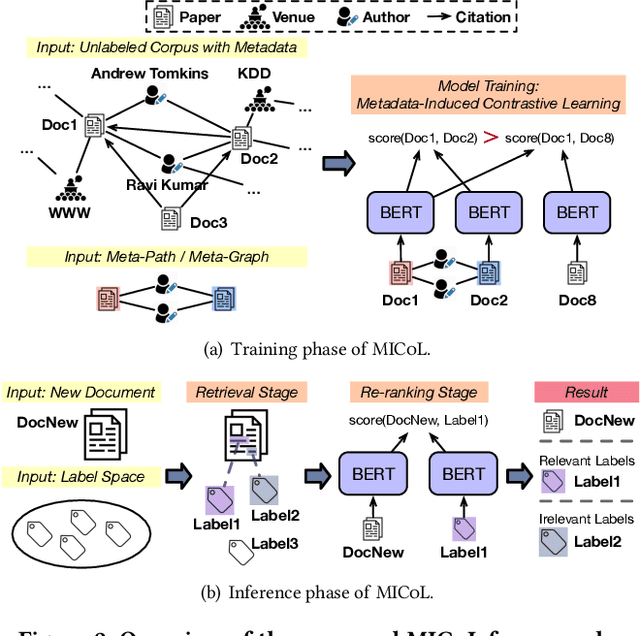
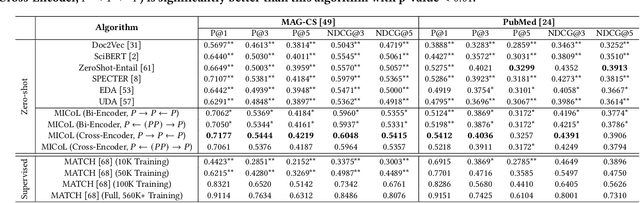
Large-scale multi-label text classification (LMTC) aims to associate a document with its relevant labels from a large candidate set. Most existing LMTC approaches rely on massive human-annotated training data, which are often costly to obtain and suffer from a long-tailed label distribution (i.e., many labels occur only a few times in the training set). In this paper, we study LMTC under the zero-shot setting, which does not require any annotated documents with labels and only relies on label surface names and descriptions. To train a classifier that calculates the similarity score between a document and a label, we propose a novel metadata-induced contrastive learning (MICoL) method. Different from previous text-based contrastive learning techniques, MICoL exploits document metadata (e.g., authors, venues, and references of research papers), which are widely available on the Web, to derive similar document-document pairs. Experimental results on two large-scale datasets show that: (1) MICoL significantly outperforms strong zero-shot text classification and contrastive learning baselines; (2) MICoL is on par with the state-of-the-art supervised metadata-aware LMTC method trained on 10K-200K labeled documents; and (3) MICoL tends to predict more infrequent labels than supervised methods, thus alleviates the deteriorated performance on long-tailed labels.
TaxoEnrich: Self-Supervised Taxonomy Completion via Structure-Semantic Representations
Feb 10, 2022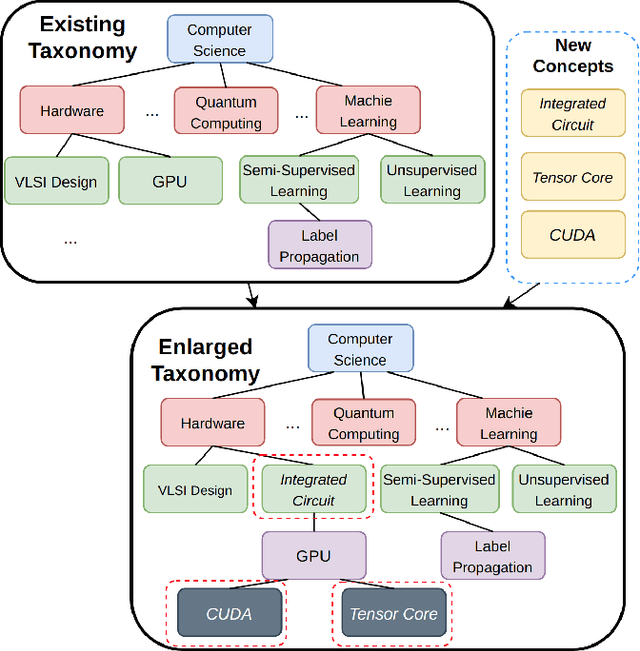
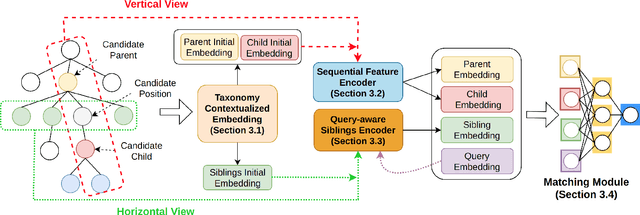
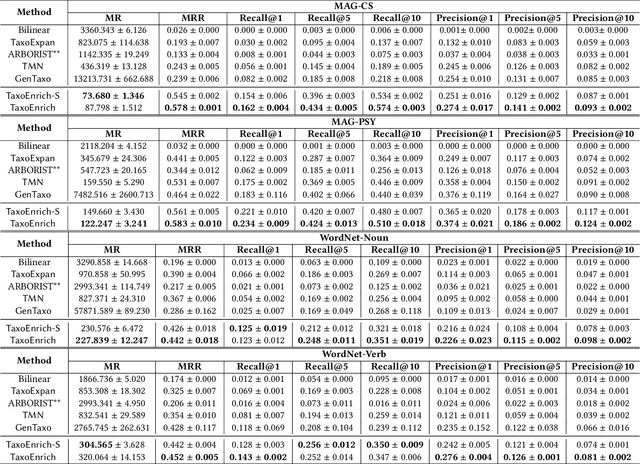
Taxonomies are fundamental to many real-world applications in various domains, serving as structural representations of knowledge. To deal with the increasing volume of new concepts needed to be organized as taxonomies, researchers turn to automatically completion of an existing taxonomy with new concepts. In this paper, we propose TaxoEnrich, a new taxonomy completion framework, which effectively leverages both semantic features and structural information in the existing taxonomy and offers a better representation of candidate position to boost the performance of taxonomy completion. Specifically, TaxoEnrich consists of four components: (1) taxonomy-contextualized embedding which incorporates both semantic meanings of concept and taxonomic relations based on powerful pretrained language models; (2) a taxonomy-aware sequential encoder which learns candidate position representations by encoding the structural information of taxonomy; (3) a query-aware sibling encoder which adaptively aggregates candidate siblings to augment candidate position representations based on their importance to the query-position matching; (4) a query-position matching model which extends existing work with our new candidate position representations. Extensive experiments on four large real-world datasets from different domains show that \TaxoEnrich achieves the best performance among all evaluation metrics and outperforms previous state-of-the-art methods by a large margin.
Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations
Feb 09, 2022
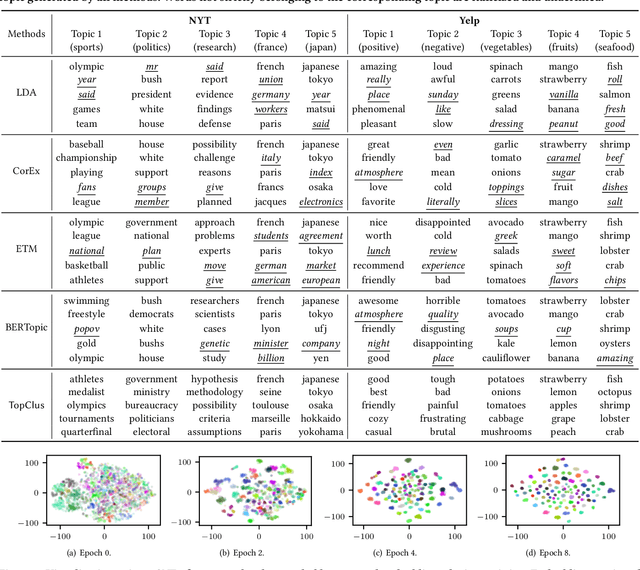
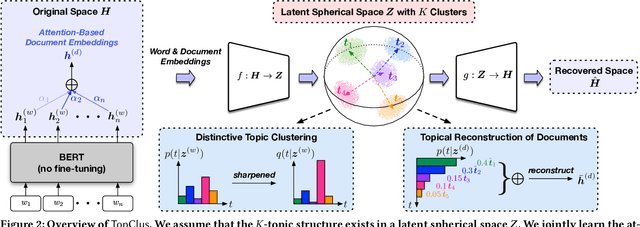
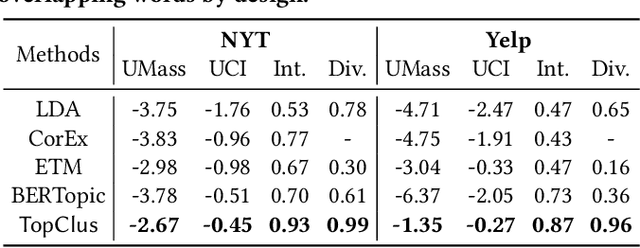
Topic models have been the prominent tools for automatic topic discovery from text corpora. Despite their effectiveness, topic models suffer from several limitations including the inability of modeling word ordering information in documents, the difficulty of incorporating external linguistic knowledge, and the lack of both accurate and efficient inference methods for approximating the intractable posterior. Recently, pretrained language models (PLMs) have brought astonishing performance improvements to a wide variety of tasks due to their superior representations of text. Interestingly, there have not been standard approaches to deploy PLMs for topic discovery as better alternatives to topic models. In this paper, we begin by analyzing the challenges of using PLM representations for topic discovery, and then propose a joint latent space learning and clustering framework built upon PLM embeddings. In the latent space, topic-word and document-topic distributions are jointly modeled so that the discovered topics can be interpreted by coherent and distinctive terms and meanwhile serve as meaningful summaries of the documents. Our model effectively leverages the strong representation power and superb linguistic features brought by PLMs for topic discovery, and is conceptually simpler than topic models. On two benchmark datasets in different domains, our model generates significantly more coherent and diverse topics than strong topic models, and offers better topic-wise document representations, based on both automatic and human evaluations.
Generating Training Data with Language Models: Towards Zero-Shot Language Understanding
Feb 09, 2022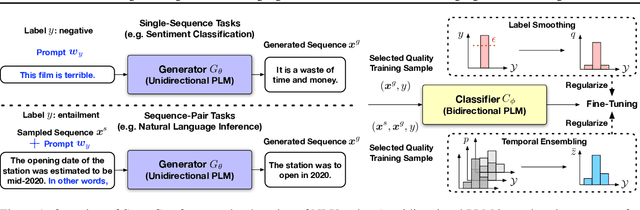
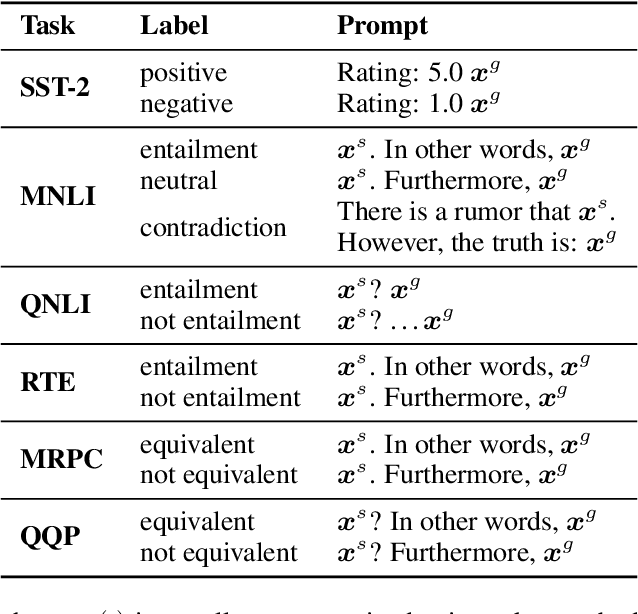
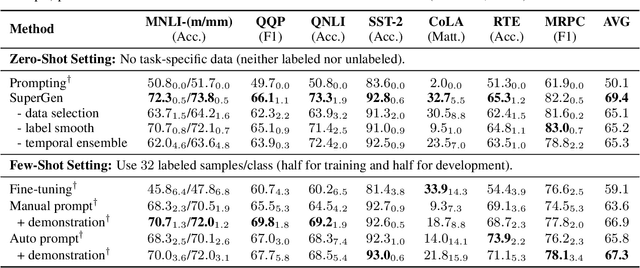
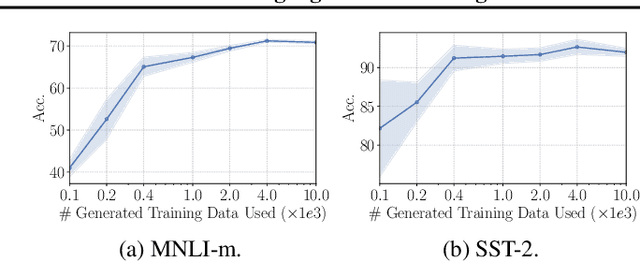
Pretrained language models (PLMs) have demonstrated remarkable performance in various natural language processing tasks: Unidirectional PLMs (e.g., GPT) are well known for their superior text generation capabilities; bidirectional PLMs (e.g., BERT) have been the prominent choice for natural language understanding (NLU) tasks. While both types of models have achieved promising few-shot learning performance, their potential for zero-shot learning has been underexplored. In this paper, we present a simple approach that uses both types of PLMs for fully zero-shot learning of NLU tasks without requiring any task-specific data: A unidirectional PLM generates class-conditioned texts guided by prompts, which are used as the training data for fine-tuning a bidirectional PLM. With quality training data selected based on the generation probability and regularization techniques (label smoothing and temporal ensembling) applied to the fine-tuning stage for better generalization and stability, our approach demonstrates strong performance across seven classification tasks of the GLUE benchmark (e.g., 72.3/73.8 on MNLI-m/mm and 92.8 on SST-2), significantly outperforming zero-shot prompting methods and achieving even comparable results to strong few-shot approaches using 32 training samples per class.
Unsupervised Summarization with Customized Granularities
Jan 29, 2022
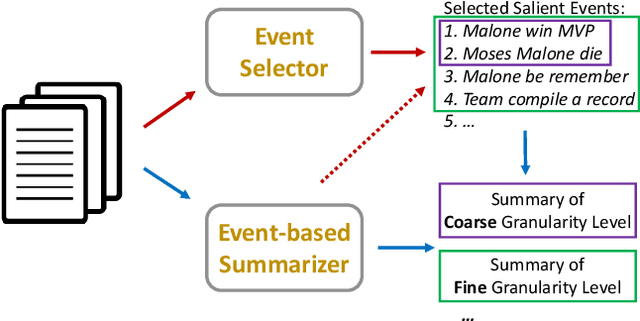


Text summarization is a personalized and customized task, i.e., for one document, users often have different preferences for the summary. As a key aspect of customization in summarization, granularity is used to measure the semantic coverage between summary and source document. Coarse-grained summaries can only contain the most central event in the original text, while fine-grained summaries cover more sub-events and corresponding details. However, previous studies mostly develop systems in the single-granularity scenario. And models that can generate summaries with customizable semantic coverage still remain an under-explored topic. In this paper, we propose the first unsupervised multi-granularity summarization framework, GranuSum. We take events as the basic semantic units of the source documents and propose to rank these events by their salience. We also develop a model to summarize input documents with given events as anchors and hints. By inputting different numbers of events, GranuSum is capable of producing multi-granular summaries in an unsupervised manner. Meanwhile, to evaluate multi-granularity summarization models, we annotate a new benchmark GranuDUC, in which we write multiple summaries of different granularities for each document cluster. Experimental results confirm the substantial superiority of GranuSum on multi-granularity summarization over several baseline systems. Furthermore, by experimenting on conventional unsupervised abstractive summarization tasks, we find that GranuSum, by exploiting the event information, can also achieve new state-of-the-art results under this scenario, outperforming strong baselines.