 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation
May 28, 2018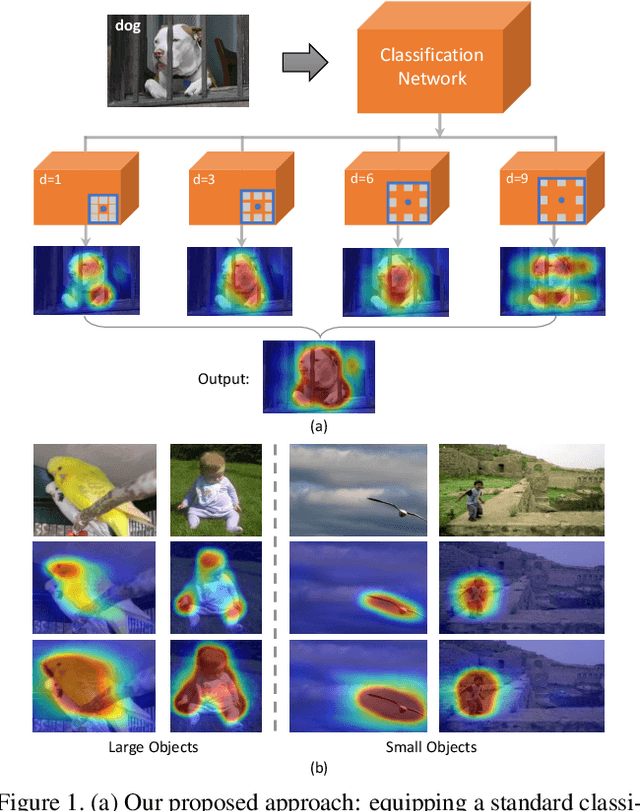
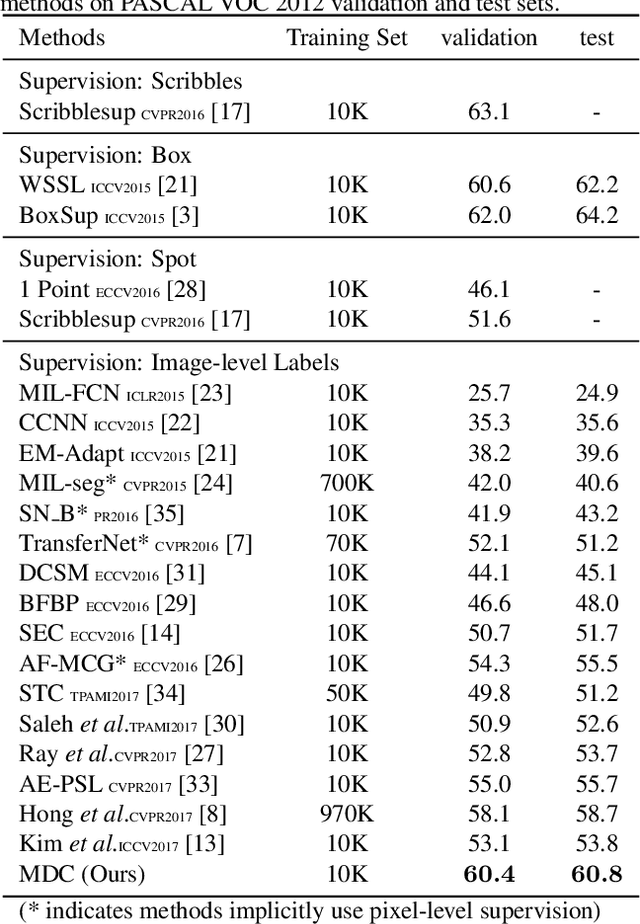


Despite the remarkable progress, weakly supervised segmentation approaches are still inferior to their fully supervised counterparts. We obverse the performance gap mainly comes from their limitation on learning to produce high-quality dense object localization maps from image-level supervision. To mitigate such a gap, we revisit the dilated convolution [1] and reveal how it can be utilized in a novel way to effectively overcome this critical limitation of weakly supervised segmentation approaches. Specifically, we find that varying dilation rates can effectively enlarge the receptive fields of convolutional kernels and more importantly transfer the surrounding discriminative information to non-discriminative object regions, promoting the emergence of these regions in the object localization maps. Then, we design a generic classification network equipped with convolutional blocks of different dilated rates. It can produce dense and reliable object localization maps and effectively benefit both weakly- and semi- supervised semantic segmentation. Despite the apparent simplicity, our proposed approach obtains superior performance over state-of-the-arts. In particular, it achieves 60.8% and 67.6% mIoU scores on Pascal VOC 2012 test set in weakly- (only image-level labels are available) and semi- (1,464 segmentation masks are available) supervised settings, which are the new state-of-the-arts.
Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization
May 26, 2018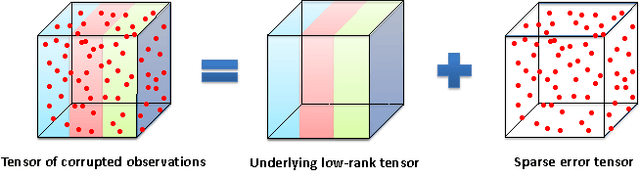
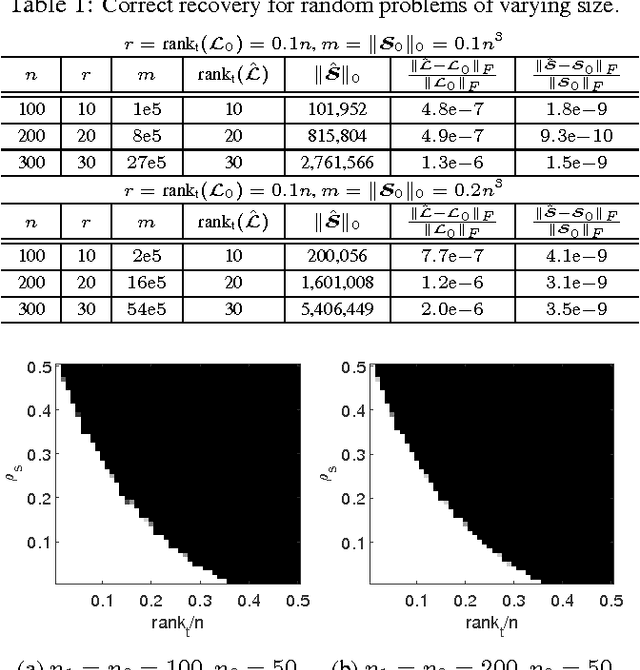
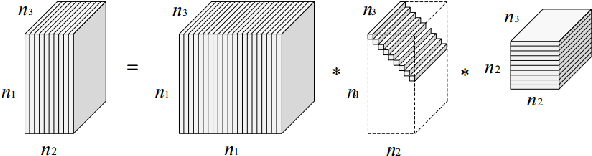

This paper studies the Tensor Robust Principal Component (TRPCA) problem which extends the known Robust PCA (Candes et al. 2011) to the tensor case. Our model is based on a new tensor Singular Value Decomposition (t-SVD) (Kilmer and Martin 2011) and its induced tensor tubal rank and tensor nuclear norm. Consider that we have a 3-way tensor ${\mathcal{X}}\in\mathbb{R}^{n_1\times n_2\times n_3}$ such that ${\mathcal{X}}={\mathcal{L}}_0+{\mathcal{E}}_0$, where ${\mathcal{L}}_0$ has low tubal rank and ${\mathcal{E}}_0$ is sparse. Is that possible to recover both components? In this work, we prove that under certain suitable assumptions, we can recover both the low-rank and the sparse components exactly by simply solving a convex program whose objective is a weighted combination of the tensor nuclear norm and the $\ell_1$-norm, i.e., $\min_{{\mathcal{L}},\ {\mathcal{E}}} \ \|{{\mathcal{L}}}\|_*+\lambda\|{{\mathcal{E}}}\|_1, \ \text{s.t.} \ {\mathcal{X}}={\mathcal{L}}+{\mathcal{E}}$, where $\lambda= {1}/{\sqrt{\max(n_1,n_2)n_3}}$. Interestingly, TRPCA involves RPCA as a special case when $n_3=1$ and thus it is a simple and elegant tensor extension of RPCA. Also numerical experiments verify our theory and the application for the image denoising demonstrates the effectiveness of our method.
Subspace Clustering by Block Diagonal Representation
May 23, 2018
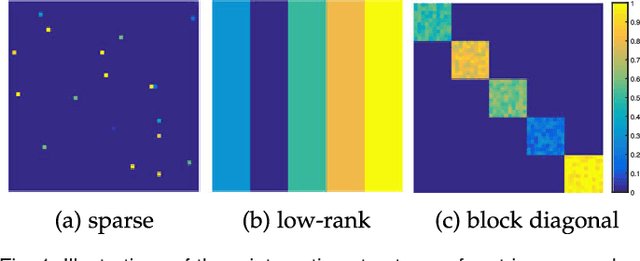
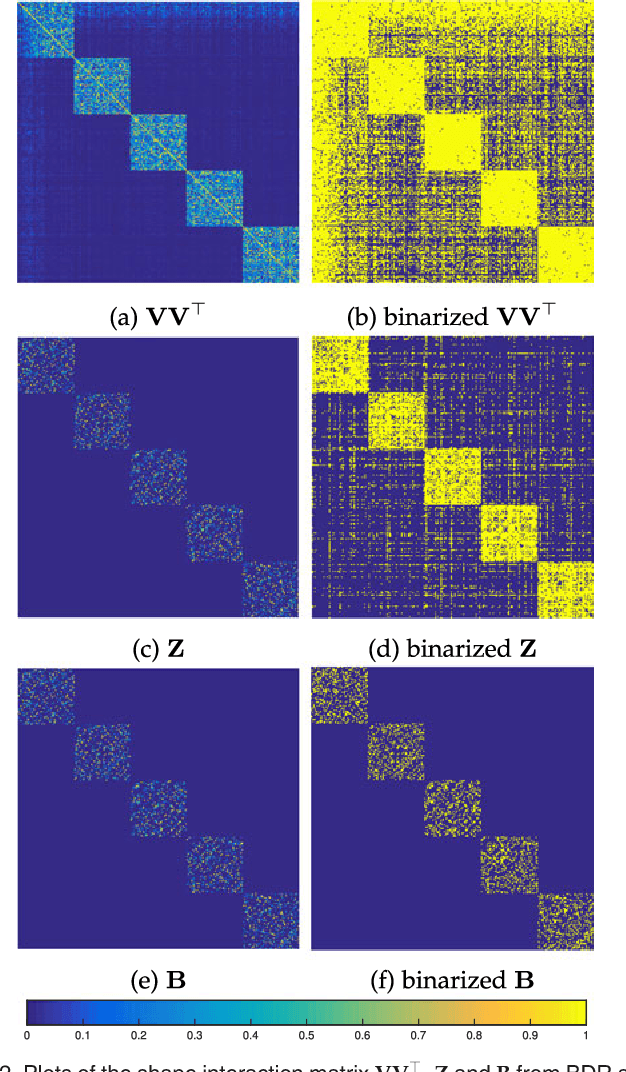
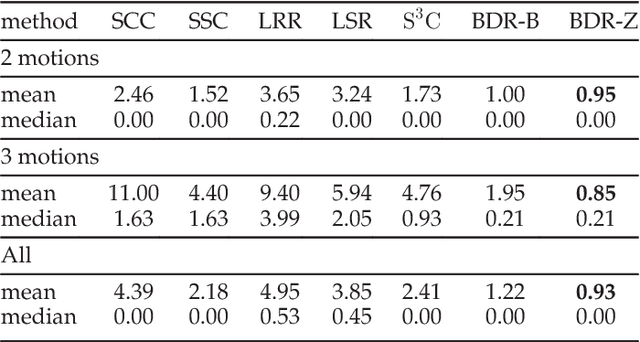
This paper studies the subspace clustering problem. Given some data points approximately drawn from a union of subspaces, the goal is to group these data points into their underlying subspaces. Many subspace clustering methods have been proposed and among which sparse subspace clustering and low-rank representation are two representative ones. Despite the different motivations, we observe that many existing methods own the common block diagonal property, which possibly leads to correct clustering, yet with their proofs given case by case. In this work, we consider a general formulation and provide a unified theoretical guarantee of the block diagonal property. The block diagonal property of many existing methods falls into our special case. Second, we observe that many existing methods approximate the block diagonal representation matrix by using different structure priors, e.g., sparsity and low-rankness, which are indirect. We propose the first block diagonal matrix induced regularizer for directly pursuing the block diagonal matrix. With this regularizer, we solve the subspace clustering problem by Block Diagonal Representation (BDR), which uses the block diagonal structure prior. The BDR model is nonconvex and we propose an alternating minimization solver and prove its convergence. Experiments on real datasets demonstrate the effectiveness of BDR.
WSNet: Compact and Efficient Networks Through Weight Sampling
May 22, 2018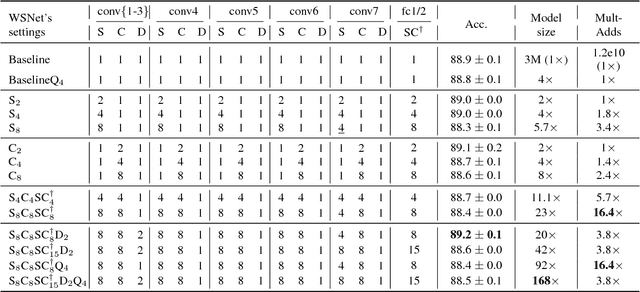
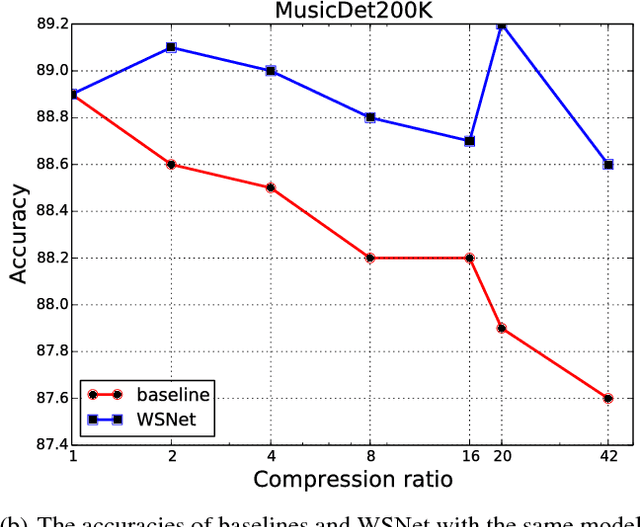

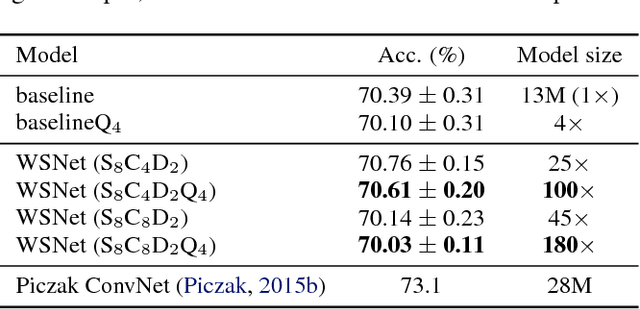
We present a new approach and a novel architecture, termed WSNet, for learning compact and efficient deep neural networks. Existing approaches conventionally learn full model parameters independently and then compress them via ad hoc processing such as model pruning or filter factorization. Alternatively, WSNet proposes learning model parameters by sampling from a compact set of learnable parameters, which naturally enforces {parameter sharing} throughout the learning process. We demonstrate that such a novel weight sampling approach (and induced WSNet) promotes both weights and computation sharing favorably. By employing this method, we can more efficiently learn much smaller networks with competitive performance compared to baseline networks with equal numbers of convolution filters. Specifically, we consider learning compact and efficient 1D convolutional neural networks for audio classification. Extensive experiments on multiple audio classification datasets verify the effectiveness of WSNet. Combined with weight quantization, the resulted models are up to 180 times smaller and theoretically up to 16 times faster than the well-established baselines, without noticeable performance drop.
Learning Markov Clustering Networks for Scene Text Detection
May 22, 2018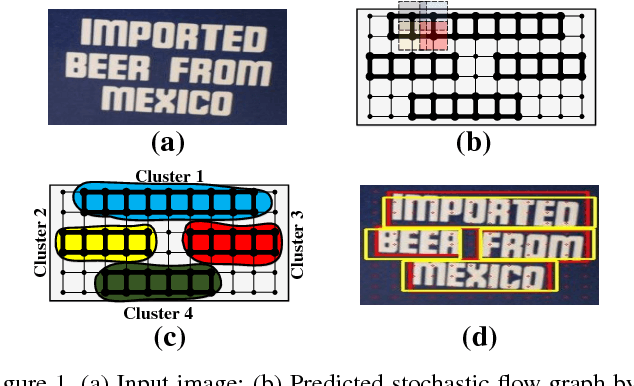
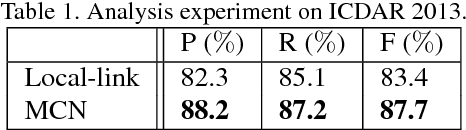
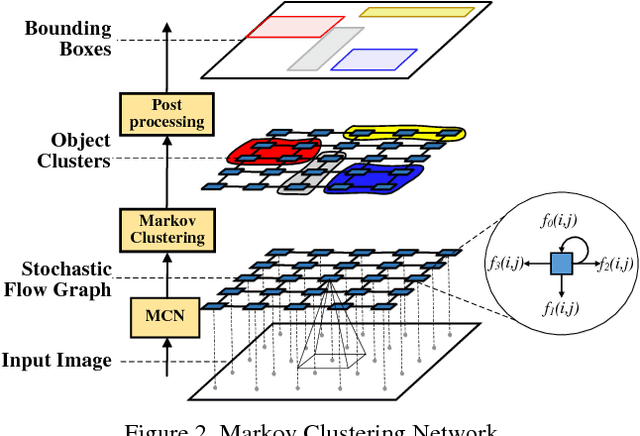
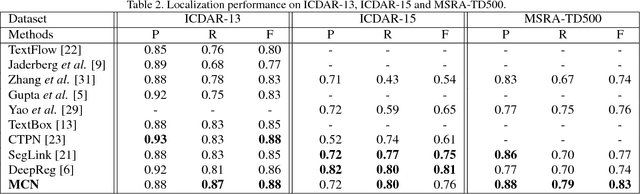
A novel framework named Markov Clustering Network (MCN) is proposed for fast and robust scene text detection. MCN predicts instance-level bounding boxes by firstly converting an image into a Stochastic Flow Graph (SFG) and then performing Markov Clustering on this graph. Our method can detect text objects with arbitrary size and orientation without prior knowledge of object size. The stochastic flow graph encode objects' local correlation and semantic information. An object is modeled as strongly connected nodes, which allows flexible bottom-up detection for scale-varying and rotated objects. MCN generates bounding boxes without using Non-Maximum Suppression, and it can be fully parallelized on GPUs. The evaluation on public benchmarks shows that our method outperforms the existing methods by a large margin in detecting multioriented text objects. MCN achieves new state-of-art performance on challenging MSRA-TD500 dataset with precision of 0.88, recall of 0.79 and F-score of 0.83. Also, MCN achieves realtime inference with frame rate of 34 FPS, which is $1.5\times$ speedup when compared with the fastest scene text detection algorithm.
Learning Pixel-wise Labeling from the Internet without Human Interaction
May 19, 2018

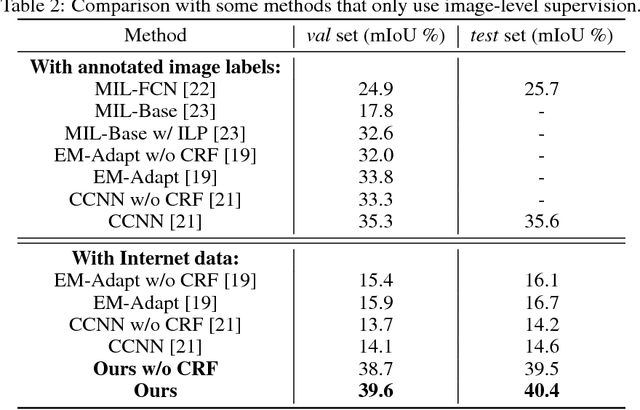

Deep learning stands at the forefront in many computer vision tasks. However, deep neural networks are usually data-hungry and require a huge amount of well-annotated training samples. Collecting sufficient annotated data is very expensive in many applications, especially for pixel-level prediction tasks such as semantic segmentation. To solve this fundamental issue, we consider a new challenging vision task, Internetly supervised semantic segmentation, which only uses Internet data with noisy image-level supervision of corresponding query keywords for segmentation model training. We address this task by proposing the following solution. A class-specific attention model unifying multiscale forward and backward convolutional features is proposed to provide initial segmentation "ground truth". The model trained with such noisy annotations is then improved by an online fine-tuning procedure. It achieves state-of-the-art performance under the weakly-supervised setting on PASCAL VOC2012 dataset. The proposed framework also paves a new way towards learning from the Internet without human interaction and could serve as a strong baseline therein. Code and data will be released upon the paper acceptance.
Transferable Semi-supervised Semantic Segmentation
May 09, 2018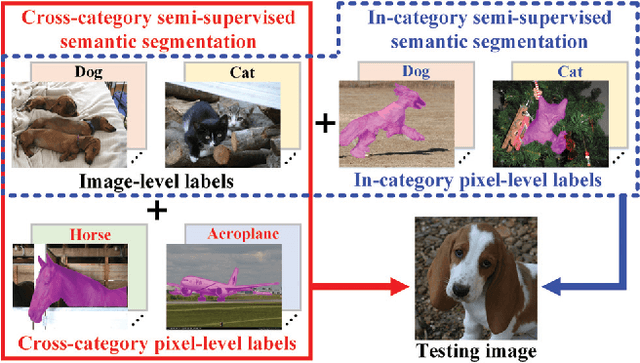
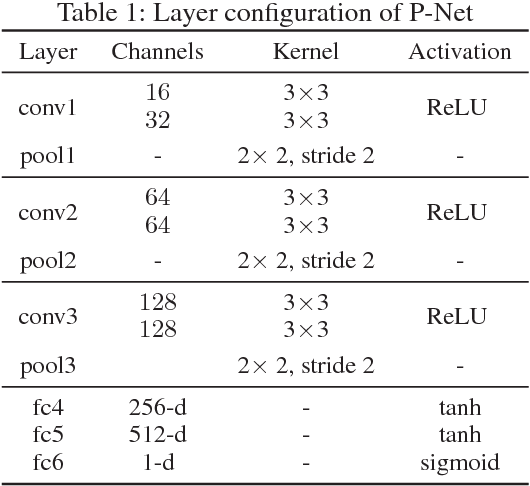
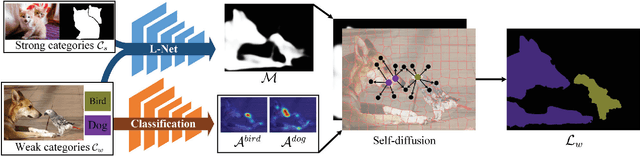
The performance of deep learning based semantic segmentation models heavily depends on sufficient data with careful annotations. However, even the largest public datasets only provide samples with pixel-level annotations for rather limited semantic categories. Such data scarcity critically limits scalability and applicability of semantic segmentation models in real applications. In this paper, we propose a novel transferable semi-supervised semantic segmentation model that can transfer the learned segmentation knowledge from a few strong categories with pixel-level annotations to unseen weak categories with only image-level annotations, significantly broadening the applicable territory of deep segmentation models. In particular, the proposed model consists of two complementary and learnable components: a Label transfer Network (L-Net) and a Prediction transfer Network (P-Net). The L-Net learns to transfer the segmentation knowledge from strong categories to the images in the weak categories and produces coarse pixel-level semantic maps, by effectively exploiting the similar appearance shared across categories. Meanwhile, the P-Net tailors the transferred knowledge through a carefully designed adversarial learning strategy and produces refined segmentation results with better details. Integrating the L-Net and P-Net achieves 96.5% and 89.4% performance of the fully-supervised baseline using 50% and 0% categories with pixel-level annotations respectively on PASCAL VOC 2012. With such a novel transfer mechanism, our proposed model is easily generalizable to a variety of new categories, only requiring image-level annotations, and offers appealing scalability in real applications.
Zigzag Learning for Weakly Supervised Object Detection
Apr 25, 2018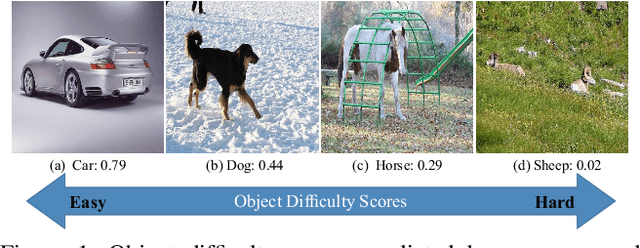
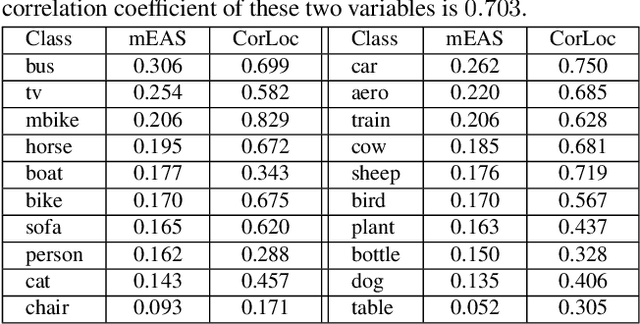
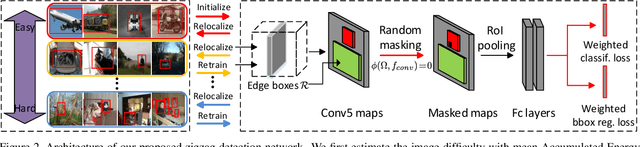

This paper addresses weakly supervised object detection with only image-level supervision at training stage. Previous approaches train detection models with entire images all at once, making the models prone to being trapped in sub-optimums due to the introduced false positive examples. Unlike them, we propose a zigzag learning strategy to simultaneously discover reliable object instances and prevent the model from overfitting initial seeds. Towards this goal, we first develop a criterion named mean Energy Accumulation Scores (mEAS) to automatically measure and rank localization difficulty of an image containing the target object, and accordingly learn the detector progressively by feeding examples with increasing difficulty. In this way, the model can be well prepared by training on easy examples for learning from more difficult ones and thus gain a stronger detection ability more efficiently. Furthermore, we introduce a novel masking regularization strategy over the high level convolutional feature maps to avoid overfitting initial samples. These two modules formulate a zigzag learning process, where progressive learning endeavors to discover reliable object instances, and masking regularization increases the difficulty of finding object instances properly. We achieve 47.6% mAP on PASCAL VOC 2007, surpassing the state-of-the-arts by a large margin.
Adversarial Complementary Learning for Weakly Supervised Object Localization
Apr 19, 2018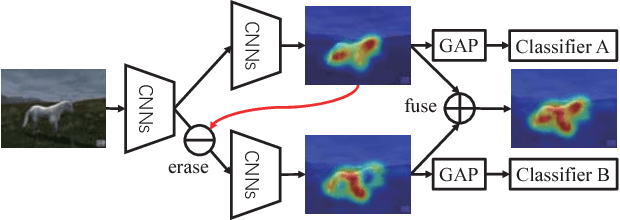
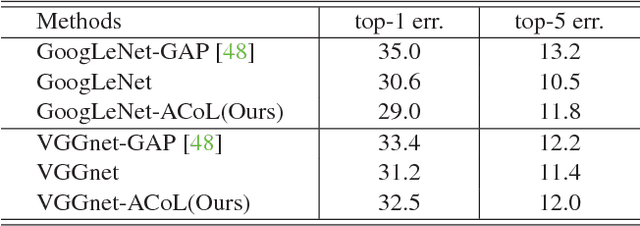

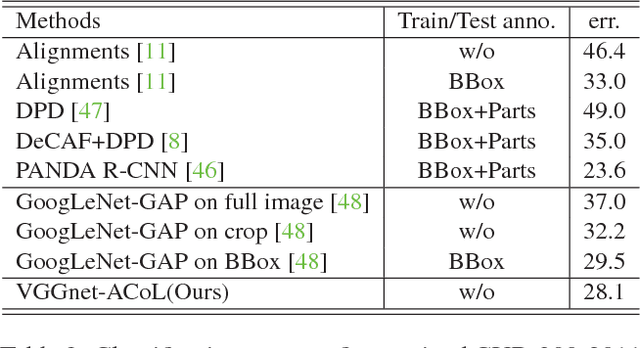
In this work, we propose Adversarial Complementary Learning (ACoL) to automatically localize integral objects of semantic interest with weak supervision. We first mathematically prove that class localization maps can be obtained by directly selecting the class-specific feature maps of the last convolutional layer, which paves a simple way to identify object regions. We then present a simple network architecture including two parallel-classifiers for object localization. Specifically, we leverage one classification branch to dynamically localize some discriminative object regions during the forward pass. Although it is usually responsive to sparse parts of the target objects, this classifier can drive the counterpart classifier to discover new and complementary object regions by erasing its discovered regions from the feature maps. With such an adversarial learning, the two parallel-classifiers are forced to leverage complementary object regions for classification and can finally generate integral object localization together. The merits of ACoL are mainly two-fold: 1) it can be trained in an end-to-end manner; 2) dynamically erasing enables the counterpart classifier to discover complementary object regions more effectively. We demonstrate the superiority of our ACoL approach in a variety of experiments. In particular, the Top-1 localization error rate on the ILSVRC dataset is 45.14%, which is the new state-of-the-art.
Tensor Robust Principal Component Analysis with A New Tensor Nuclear Norm
Apr 10, 2018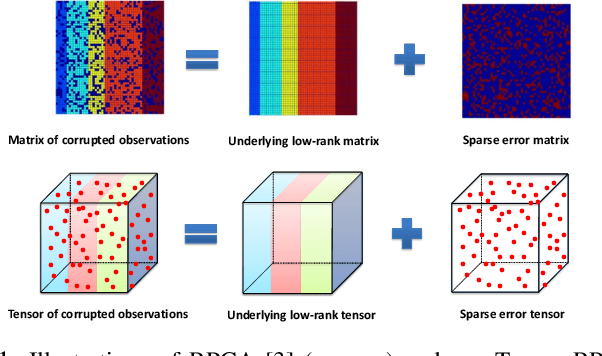

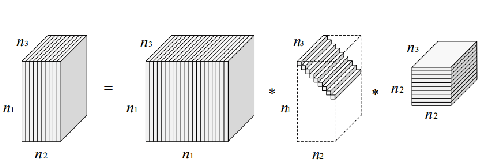

In this paper, we consider the Tensor Robust Principal Component Analysis (TRPCA) problem, which aims to exactly recover the low-rank and sparse components from their sum. Our model is based on the recently proposed tensor-tensor product (or t-product) [13]. Induced by the t-product, we first rigorously deduce the tensor spectral norm, tensor nuclear norm, and tensor average rank, and show that the tensor nuclear norm is the convex envelope of the tensor average rank within the unit ball of the tensor spectral norm. These definitions, their relationships and properties are consistent with matrix cases. Equipped with the new tensor nuclear norm, we then solve the TRPCA problem by solving a convex program and provide the theoretical guarantee for the exact recovery. Our TRPCA model and recovery guarantee include matrix RPCA as a special case. Numerical experiments verify our results, and the applications to image recovery and background modeling problems demonstrate the effectiveness of our method.