 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCC-Loc: A Unified Semantic Cascade Consensus Framework for UAV Thermal Geo-Localization
Apr 03, 2026Cross-modal Thermal Geo-localization (TG) provides a robust, all-weather solution for Unmanned Aerial Vehicles (UAVs) in Global Navigation Satellite System (GNSS)-denied environments. However, profound thermal-visible modality gaps introduce severe feature ambiguity, systematically corrupting conventional coarse-to-fine registration. To dismantle this bottleneck, we propose SCC-Loc, a unified Semantic-Cascade-Consensus localization framework. By sharing a single DINOv2 backbone across global retrieval and MINIMA$_{\text{RoMa}}$ matching, it minimizes memory footprint and achieves zero-shot, highly accurate absolute position estimation. Specifically, we tackle modality ambiguity by introducing three cohesive components. First, we design the Semantic-Guided Viewport Alignment (SGVA) module to adaptively optimize satellite crop regions, effectively correcting initial spatial deviations. Second, we develop the Cascaded Spatial-Adaptive Texture-Structure Filtering (C-SATSF) mechanism to explicitly enforce geometric consistency, thereby eradicating dense cross-modal outliers. Finally, we propose the Consensus-Driven Reliability-Aware Position Selection (CD-RAPS) strategy to derive the optimal solution through a synergy of physically constrained pose optimization. To address data scarcity, we construct Thermal-UAV, a comprehensive dataset providing 11,890 diverse thermal queries referenced against a large-scale satellite ortho-photo and corresponding spatially aligned Digital Surface Model (DSM). Extensive experiments demonstrate that SCC-Loc establishes a new state-of-the-art, suppressing the mean localization error to 9.37 m and providing a 7.6-fold accuracy improvement within a strict 5-m threshold over the strongest baseline. Code and dataset are available at https://github.com/FloralHercules/SCC-Loc.
Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation
Sep 21, 2023Unsupervised Video Object Segmentation (VOS) aims at identifying the contours of primary foreground objects in videos without any prior knowledge. However, previous methods do not fully use spatial-temporal context and fail to tackle this challenging task in real-time. This motivates us to develop an efficient Long-Short Temporal Attention network (termed LSTA) for unsupervised VOS task from a holistic view. Specifically, LSTA consists of two dominant modules, i.e., Long Temporal Memory and Short Temporal Attention. The former captures the long-term global pixel relations of the past frames and the current frame, which models constantly present objects by encoding appearance pattern. Meanwhile, the latter reveals the short-term local pixel relations of one nearby frame and the current frame, which models moving objects by encoding motion pattern. To speedup the inference, the efficient projection and the locality-based sliding window are adopted to achieve nearly linear time complexity for the two light modules, respectively. Extensive empirical studies on several benchmarks have demonstrated promising performances of the proposed method with high efficiency.
Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation
May 28, 2018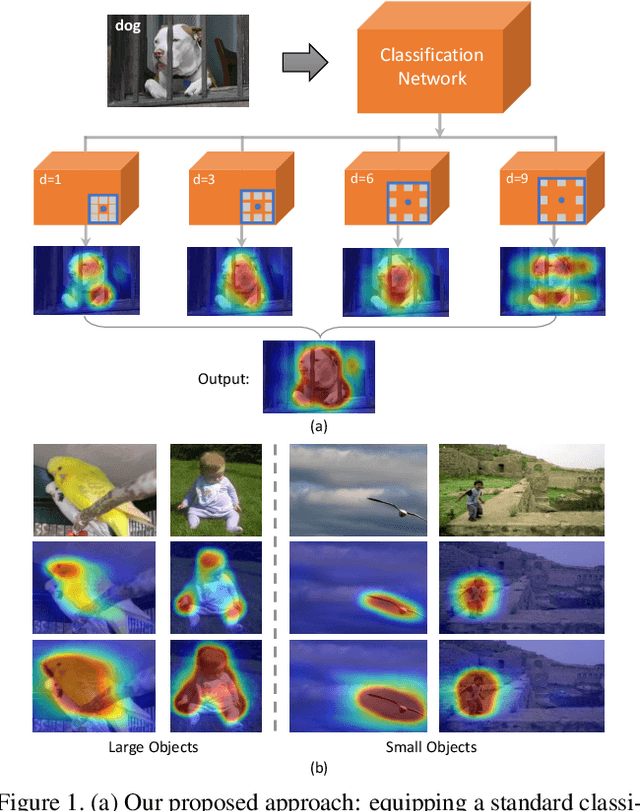
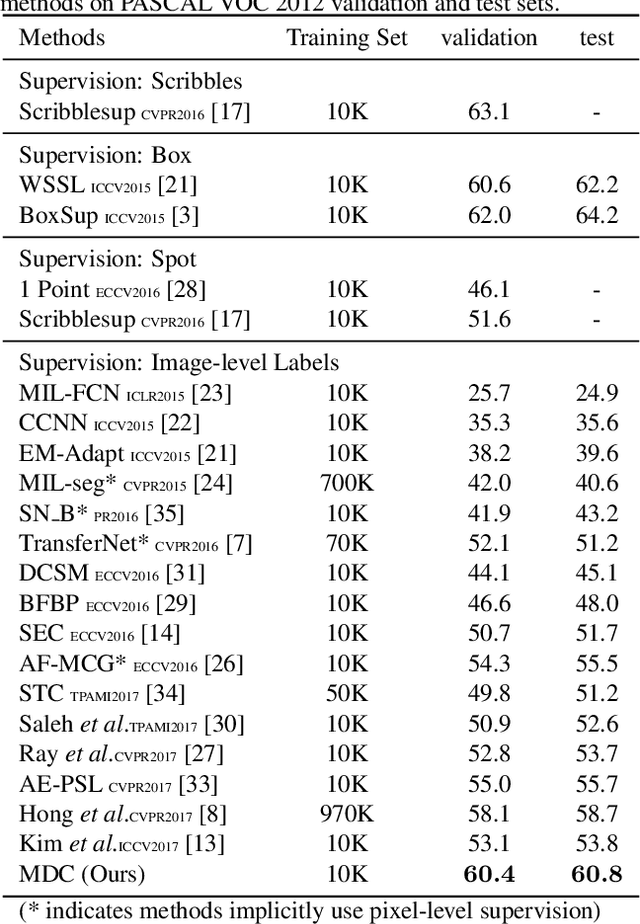


Despite the remarkable progress, weakly supervised segmentation approaches are still inferior to their fully supervised counterparts. We obverse the performance gap mainly comes from their limitation on learning to produce high-quality dense object localization maps from image-level supervision. To mitigate such a gap, we revisit the dilated convolution [1] and reveal how it can be utilized in a novel way to effectively overcome this critical limitation of weakly supervised segmentation approaches. Specifically, we find that varying dilation rates can effectively enlarge the receptive fields of convolutional kernels and more importantly transfer the surrounding discriminative information to non-discriminative object regions, promoting the emergence of these regions in the object localization maps. Then, we design a generic classification network equipped with convolutional blocks of different dilated rates. It can produce dense and reliable object localization maps and effectively benefit both weakly- and semi- supervised semantic segmentation. Despite the apparent simplicity, our proposed approach obtains superior performance over state-of-the-arts. In particular, it achieves 60.8% and 67.6% mIoU scores on Pascal VOC 2012 test set in weakly- (only image-level labels are available) and semi- (1,464 segmentation masks are available) supervised settings, which are the new state-of-the-arts.
Transferable Semi-supervised Semantic Segmentation
May 09, 2018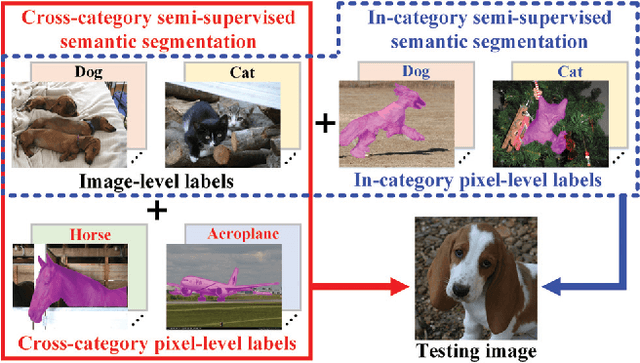
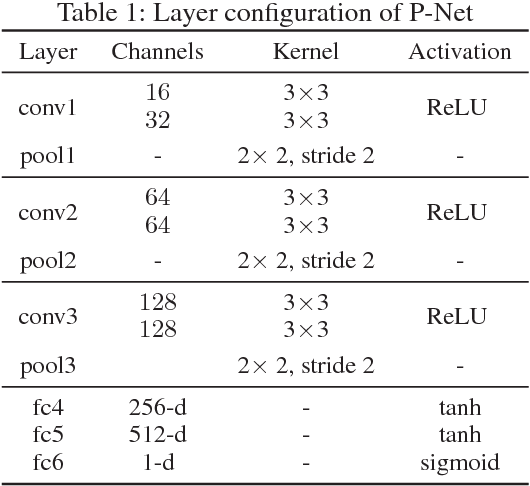
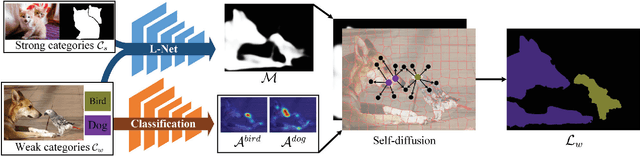
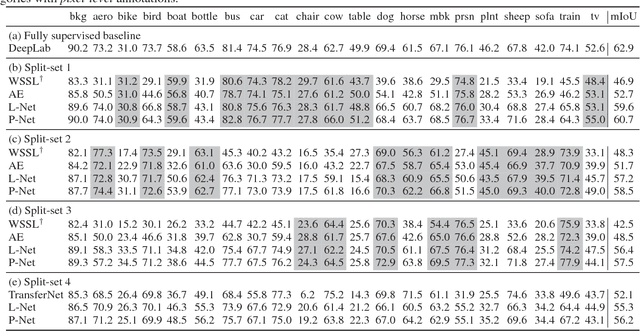
The performance of deep learning based semantic segmentation models heavily depends on sufficient data with careful annotations. However, even the largest public datasets only provide samples with pixel-level annotations for rather limited semantic categories. Such data scarcity critically limits scalability and applicability of semantic segmentation models in real applications. In this paper, we propose a novel transferable semi-supervised semantic segmentation model that can transfer the learned segmentation knowledge from a few strong categories with pixel-level annotations to unseen weak categories with only image-level annotations, significantly broadening the applicable territory of deep segmentation models. In particular, the proposed model consists of two complementary and learnable components: a Label transfer Network (L-Net) and a Prediction transfer Network (P-Net). The L-Net learns to transfer the segmentation knowledge from strong categories to the images in the weak categories and produces coarse pixel-level semantic maps, by effectively exploiting the similar appearance shared across categories. Meanwhile, the P-Net tailors the transferred knowledge through a carefully designed adversarial learning strategy and produces refined segmentation results with better details. Integrating the L-Net and P-Net achieves 96.5% and 89.4% performance of the fully-supervised baseline using 50% and 0% categories with pixel-level annotations respectively on PASCAL VOC 2012. With such a novel transfer mechanism, our proposed model is easily generalizable to a variety of new categories, only requiring image-level annotations, and offers appealing scalability in real applications.
Predicting Scene Parsing and Motion Dynamics in the Future
Nov 09, 2017
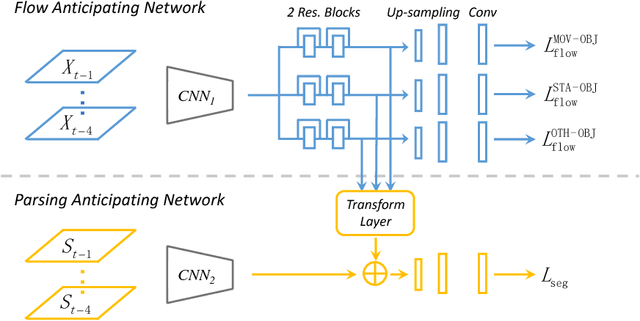
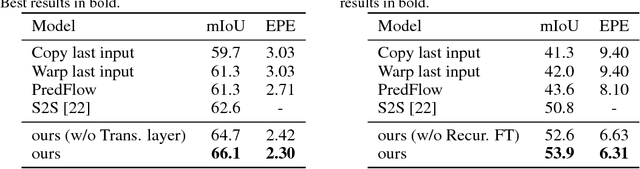

The ability of predicting the future is important for intelligent systems, e.g. autonomous vehicles and robots to plan early and make decisions accordingly. Future scene parsing and optical flow estimation are two key tasks that help agents better understand their environments as the former provides dense semantic information, i.e. what objects will be present and where they will appear, while the latter provides dense motion information, i.e. how the objects will move. In this paper, we propose a novel model to simultaneously predict scene parsing and optical flow in unobserved future video frames. To our best knowledge, this is the first attempt in jointly predicting scene parsing and motion dynamics. In particular, scene parsing enables structured motion prediction by decomposing optical flow into different groups while optical flow estimation brings reliable pixel-wise correspondence to scene parsing. By exploiting this mutually beneficial relationship, our model shows significantly better parsing and motion prediction results when compared to well-established baselines and individual prediction models on the large-scale Cityscapes dataset. In addition, we also demonstrate that our model can be used to predict the steering angle of the vehicles, which further verifies the ability of our model to learn latent representations of scene dynamics.
Self-explanatory Deep Salient Object Detection
Aug 18, 2017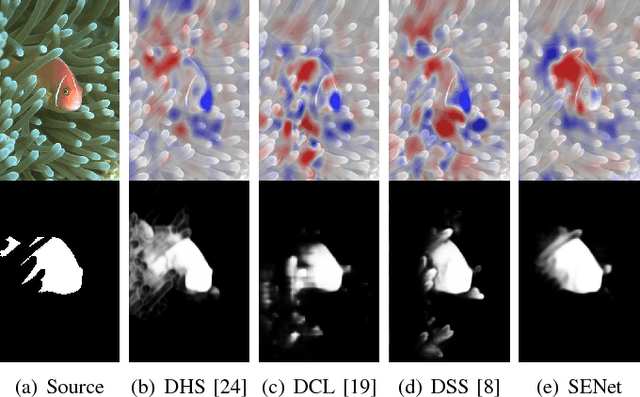

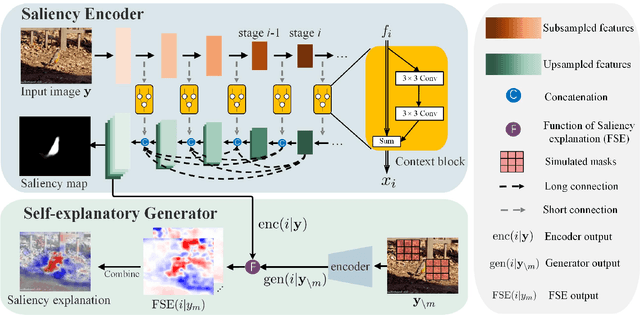

Salient object detection has seen remarkable progress driven by deep learning techniques. However, most of deep learning based salient object detection methods are black-box in nature and lacking in interpretability. This paper proposes the first self-explanatory saliency detection network that explicitly exploits low- and high-level features for salient object detection. We demonstrate that such supportive clues not only significantly enhances performance of salient object detection but also gives better justified detection results. More specifically, we develop a multi-stage saliency encoder to extract multi-scale features which contain both low- and high-level saliency context. Dense short- and long-range connections are introduced to reuse these features iteratively. Benefiting from the direct access to low- and high-level features, the proposed saliency encoder can not only model the object context but also preserve the boundary. Furthermore, a self-explanatory generator is proposed to interpret how the proposed saliency encoder or other deep saliency models making decisions. The generator simulates the absence of interesting features by preventing these features from contributing to the saliency classifier and estimates the corresponding saliency prediction without these features. A comparison function, saliency explanation, is defined to measure the prediction changes between deep saliency models and corresponding generator. Through visualizing the differences, we can interpret the capability of different deep neural networks based saliency detection models and demonstrate that our proposed model indeed uses more reasonable structure for salient object detection. Extensive experiments on five popular benchmark datasets and the visualized saliency explanation demonstrate that the proposed method provides new state-of-the-art.
Dual Path Networks
Aug 01, 2017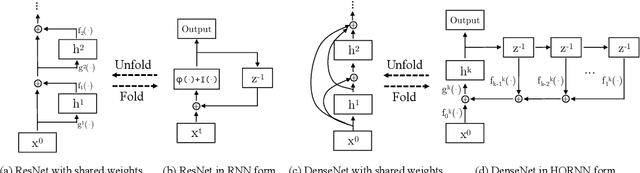
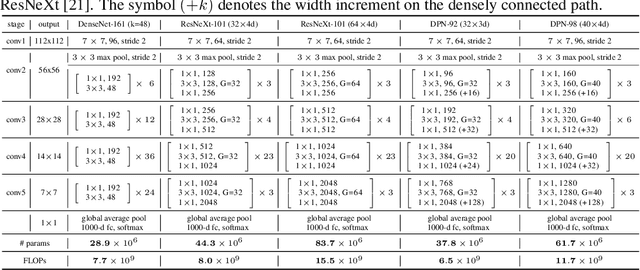
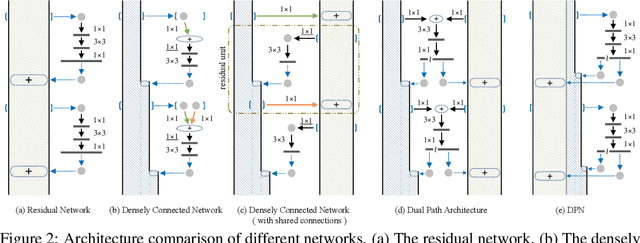
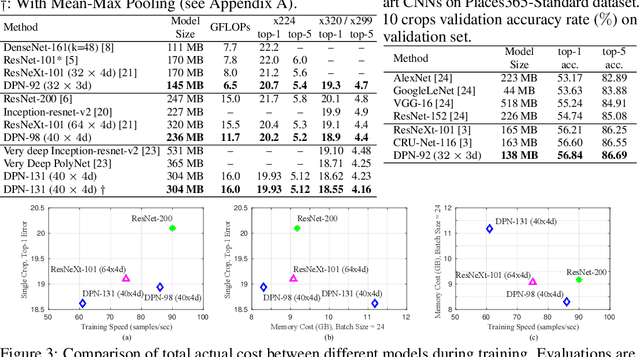
In this work, we present a simple, highly efficient and modularized Dual Path Network (DPN) for image classification which presents a new topology of connection paths internally. By revealing the equivalence of the state-of-the-art Residual Network (ResNet) and Densely Convolutional Network (DenseNet) within the HORNN framework, we find that ResNet enables feature re-usage while DenseNet enables new features exploration which are both important for learning good representations. To enjoy the benefits from both path topologies, our proposed Dual Path Network shares common features while maintaining the flexibility to explore new features through dual path architectures. Extensive experiments on three benchmark datasets, ImagNet-1k, Places365 and PASCAL VOC, clearly demonstrate superior performance of the proposed DPN over state-of-the-arts. In particular, on the ImagNet-1k dataset, a shallow DPN surpasses the best ResNeXt-101(64x4d) with 26% smaller model size, 25% less computational cost and 8% lower memory consumption, and a deeper DPN (DPN-131) further pushes the state-of-the-art single model performance with about 2 times faster training speed. Experiments on the Places365 large-scale scene dataset, PASCAL VOC detection dataset, and PASCAL VOC segmentation dataset also demonstrate its consistently better performance than DenseNet, ResNet and the latest ResNeXt model over various applications.
Video Scene Parsing with Predictive Feature Learning
Dec 13, 2016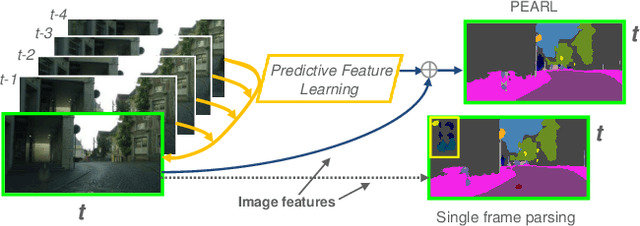
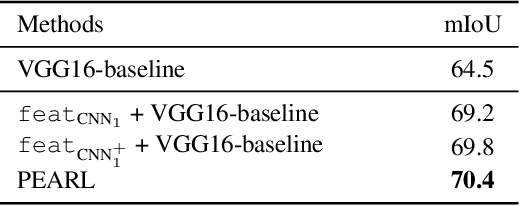

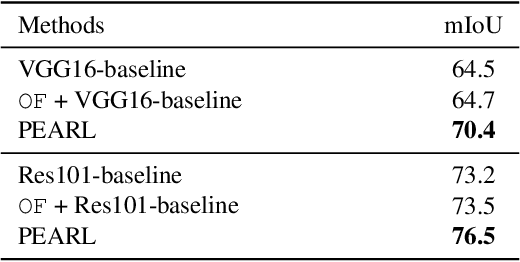
In this work, we address the challenging video scene parsing problem by developing effective representation learning methods given limited parsing annotations. In particular, we contribute two novel methods that constitute a unified parsing framework. (1) \textbf{Predictive feature learning}} from nearly unlimited unlabeled video data. Different from existing methods learning features from single frame parsing, we learn spatiotemporal discriminative features by enforcing a parsing network to predict future frames and their parsing maps (if available) given only historical frames. In this way, the network can effectively learn to capture video dynamics and temporal context, which are critical clues for video scene parsing, without requiring extra manual annotations. (2) \textbf{Prediction steering parsing}} architecture that effectively adapts the learned spatiotemporal features to scene parsing tasks and provides strong guidance for any off-the-shelf parsing model to achieve better video scene parsing performance. Extensive experiments over two challenging datasets, Cityscapes and Camvid, have demonstrated the effectiveness of our methods by showing significant improvement over well-established baselines.