 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness of Neural Ordinary Differential Equations
Oct 12, 2019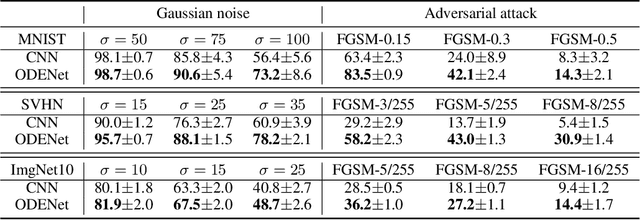
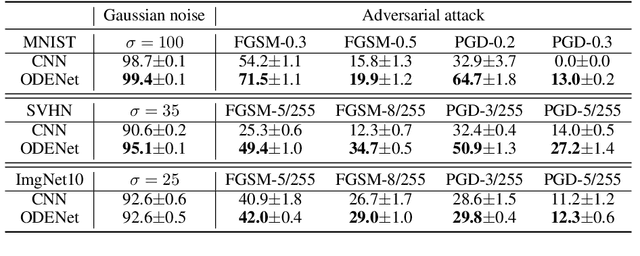
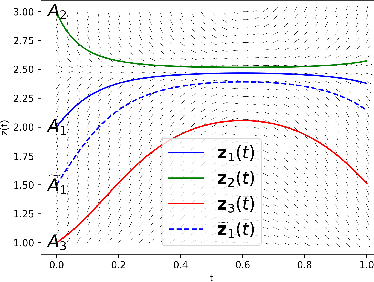
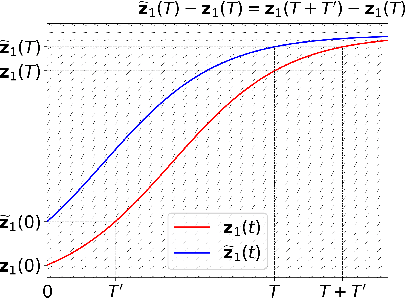
Neural ordinary differential equations (ODEs) have been attracting increasing attention in various research domains recently. There have been some works studying optimization issues and approximation capabilities of neural ODEs, but their robustness is still yet unclear. In this work, we fill this important gap by exploring robustness properties of neural ODEs both empirically and theoretically. We first present an empirical study on the robustness of the neural ODE-based networks (ODENets) by exposing them to inputs with various types of perturbations and subsequently investigating the changes of the corresponding outputs. In contrast to conventional convolutional neural networks (CNNs), we find that the ODENets are more robust against both random Gaussian perturbations and adversarial attack examples. We then provide an insightful understanding of this phenomenon by exploiting a certain desirable property of the flow of a continuous-time ODE, namely that integral curves are non-intersecting. Our work suggests that, due to their intrinsic robustness, it is promising to use neural ODEs as a basic block for building robust deep network models. To further enhance the robustness of vanilla neural ODEs, we propose the time-invariant steady neural ODE (TisODE), which regularizes the flow on perturbed data via the time-invariant property and the imposition of a steady-state constraint. We show that the TisODE method outperforms vanilla neural ODEs and also can work in conjunction with other state-of-the-art architectural methods to build more robust deep networks.
Adaptive ROI Generation for Video Object Segmentation Using Reinforcement Learning
Sep 27, 2019
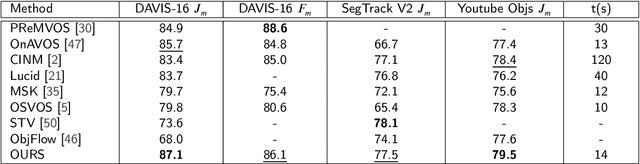
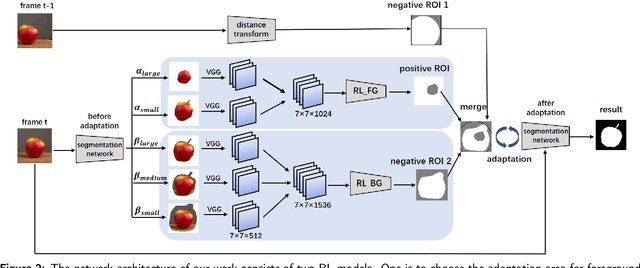
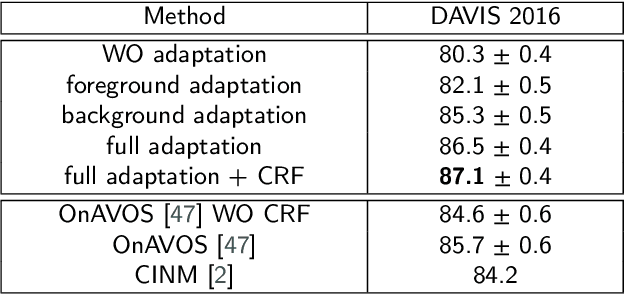
In this paper, we aim to tackle the task of semi-supervised video object segmentation across a sequence of frames where only the ground-truth segmentation of the first frame is provided. The challenges lie in how to online update the segmentation model initialized from the first frame adaptively and accurately, even in presence of multiple confusing instances or large object motion. The existing approaches rely on selecting the region of interest for model update, which however, is rough and inflexible, leading to performance degradation. To overcome this limitation, we propose a novel approach which utilizes reinforcement learning to select optimal adaptation areas for each frame, based on the historical segmentation information. The RL model learns to take optimal actions to adjust the region of interest inferred from the previous frame for online model updating. To speed up the model adaption, we further design a novel multi-branch tree based exploration method to fast select the best state action pairs. Our experiments show that our work improves the state-of-the-art of the mean region similarity on DAVIS 2016 dataset to 87.1%.
Revisit Knowledge Distillation: a Teacher-free Framework
Sep 25, 2019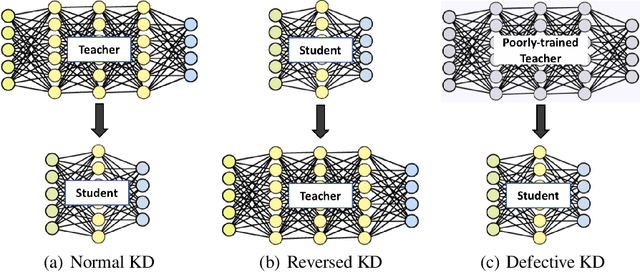

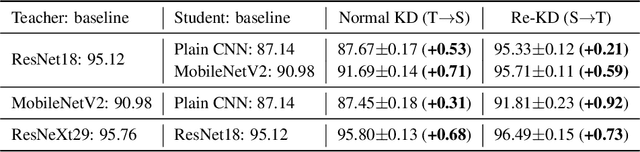
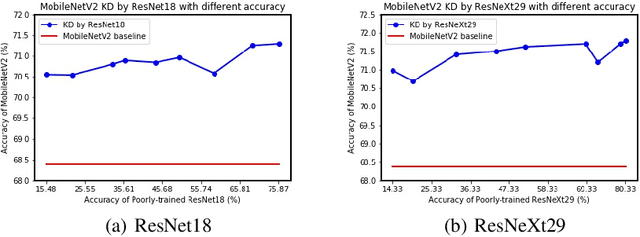
Knowledge Distillation (KD) aims to distill the knowledge of a cumbersome teacher model into a lightweight student model. Its success is generally attributed to the privileged information on similarities among categories provided by the teacher model, and in this sense, only strong teacher models are deployed to teach weaker students in practice. In this work, we challenge this common belief by following experimental observations: 1) beyond the acknowledgment that the teacher can improve the student, the student can also enhance the teacher significantly by reversing the KD procedure; 2) a poorly-trained teacher with much lower accuracy than the student can still improve the latter significantly. To explain these observations, we provide a theoretical analysis of the relationships between KD and label smoothing regularization. We prove that 1) KD is a type of learned label smoothing regularization and 2) label smoothing regularization provides a virtual teacher model for KD. From these results, we argue that the success of KD is not fully due to the similarity information between categories, but also to the regularization of soft targets, which is equally or even more important. Based on these analyses, we further propose a novel Teacher-free Knowledge Distillation (Tf-KD) framework, where a student model learns from itself or manually-designed regularization distribution. The Tf-KD achieves comparable performance with normal KD from a superior teacher, which is well applied when teacher model is unavailable. Meanwhile, Tf-KD is generic and can be directly deployed for training deep neural networks. Without any extra computation cost, Tf-KD achieves up to 0.65\% improvement on ImageNet over well-established baseline models, which is superior to label smoothing regularization. The codes are in: \url{https://github.com/yuanli2333/Teacher-free-Knowledge-Distillation}
Hierarchic Neighbors Embedding
Sep 16, 2019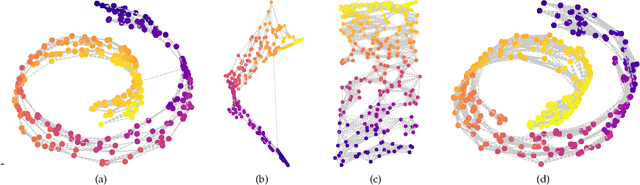
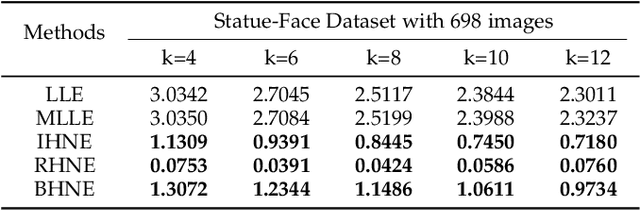
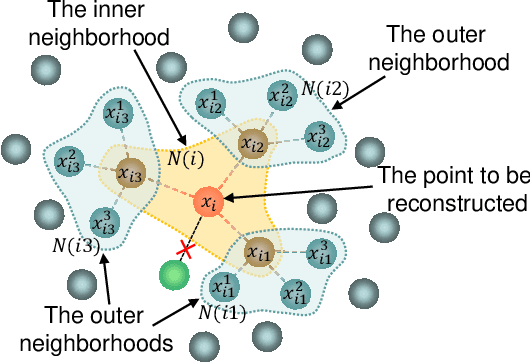
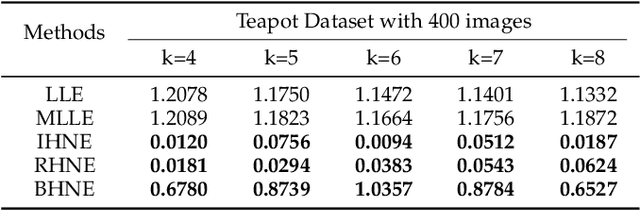
Manifold learning now plays a very important role in machine learning and many relevant applications. Although its superior performance in dealing with nonlinear data distribution, data sparsity is always a thorny knot. There are few researches to well handle it in manifold learning. In this paper, we propose Hierarchic Neighbors Embedding (HNE), which enhance local connection by the hierarchic combination of neighbors. After further analyzing topological connection and reconstruction performance, three different versions of HNE are given. The experimental results show that our methods work well on both synthetic data and high-dimensional real-world tasks. HNE develops the outstanding advantages in dealing with general data. Furthermore, comparing with other popular manifold learning methods, the performance on sparse samples and weak-connected manifolds is better for HNE.
PSGAN: Pose-Robust Spatial-Aware GAN for Customizable Makeup Transfer
Sep 16, 2019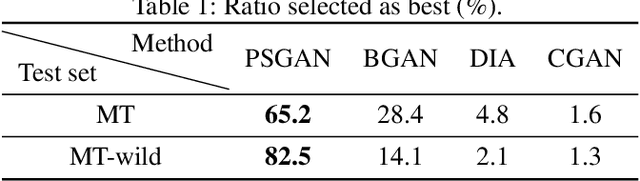
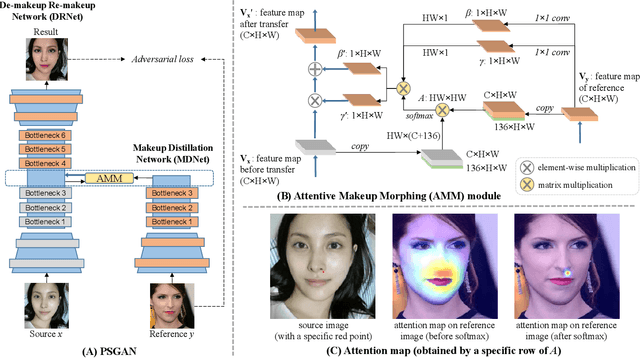


We propose a novel Pose-robust Spatial-aware GAN (PSGAN) for transferring the makeup style from a reference image to a source image. Previous GAN-based methods often fail in cases with variant poses and expressions. Also, they cannot adjust the shade of makeup or specify the part of transfer. To address these issues, the proposed PSGAN includes a Makeup Distillation Network to distill the makeup style of the reference image into two spatial-aware makeup matrices. Then an Attentive Makeup Morphing module is introduced to specify how a pixel in the source image is morphed from the reference image. The pixelwise correspondence is built upon both the relative position features and visual features. Based on the morphed makeup matrices, a De-makeup Re-makeup Network performs makeup transfer. By incorporating the above novelties, our PSGAN not only achieves state-of-the-art results on the existing datasets, but also is able to perform the customizable part-by-part, shade controllable and pose-robust makeup transfer.
Single-Stage Multi-Person Pose Machines
Aug 24, 2019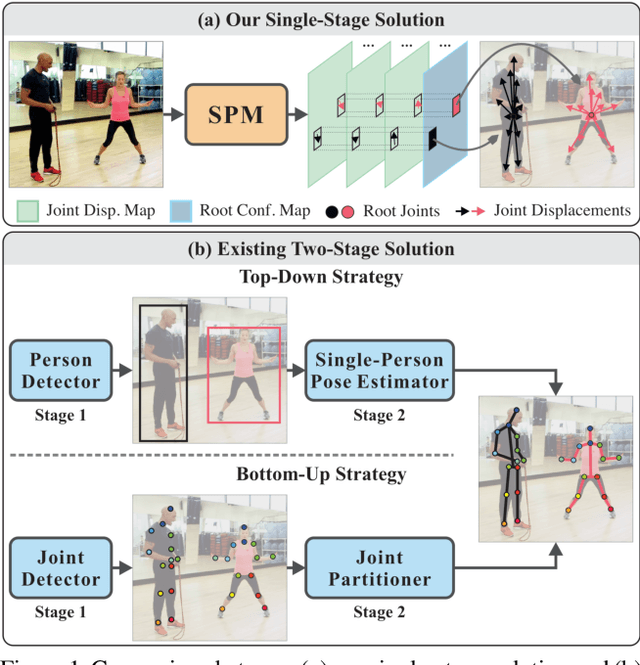
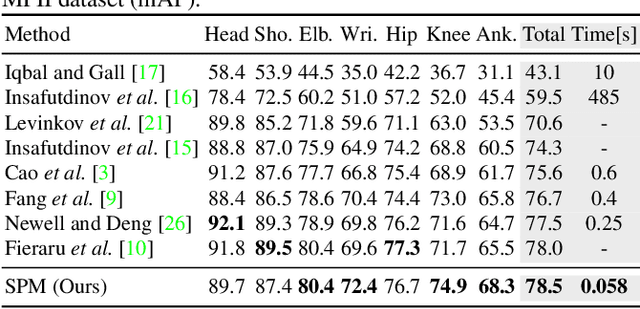
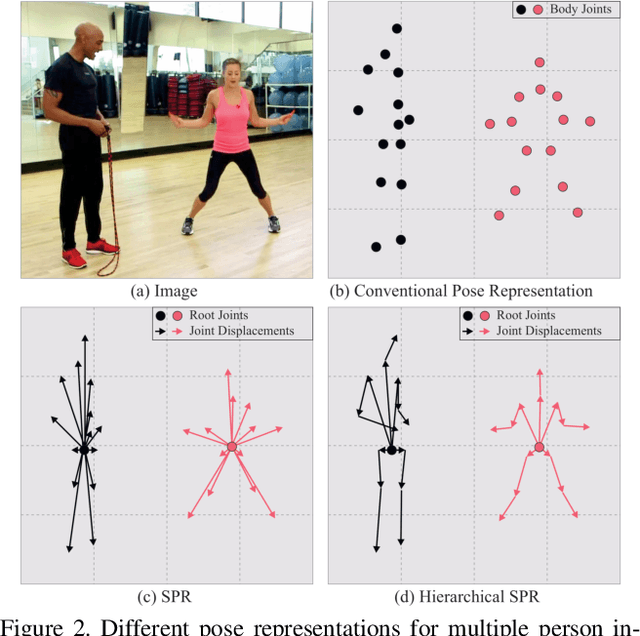

Multi-person pose estimation is a challenging problem. Existing methods are mostly two-stage based--one stage for proposal generation and the other for allocating poses to corresponding persons. However, such two-stage methods generally suffer low efficiency. In this work, we present the first single-stage model, Single-stage multi-person Pose Machine (SPM), to simplify the pipeline and lift the efficiency for multi-person pose estimation. To achieve this, we propose a novel Structured Pose Representation (SPR) that unifies person instance and body joint position representations. Based on SPR, we develop the SPM model that can directly predict structured poses for multiple persons in a single stage, and thus offer a more compact pipeline and attractive efficiency advantage over two-stage methods. In particular, SPR introduces the root joints to indicate different person instances and human body joint positions are encoded into their displacements w.r.t. the roots. To better predict long-range displacements for some joints, SPR is further extended to hierarchical representations. Based on SPR, SPM can efficiently perform multi-person poses estimation by simultaneously predicting root joints (location of instances) and body joint displacements via CNNs. Moreover, to demonstrate the generality of SPM, we also apply it to multi-person 3D pose estimation. Comprehensive experiments on benchmarks MPII, extended PASCAL-Person-Part, MSCOCO and CMU Panoptic clearly demonstrate the state-of-the-art efficiency of SPM for multi-person 2D/3D pose estimation, together with outstanding accuracy.
Dynamic Kernel Distillation for Efficient Pose Estimation in Videos
Aug 24, 2019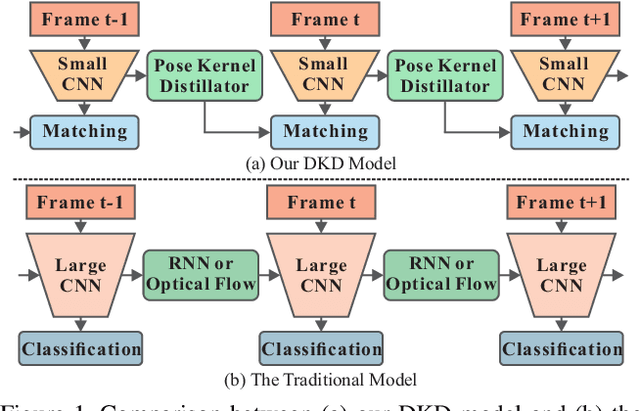
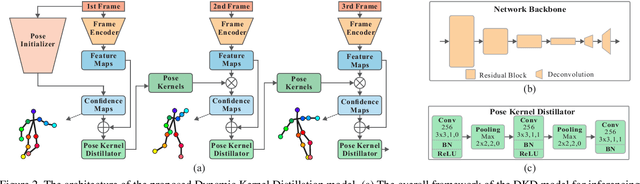
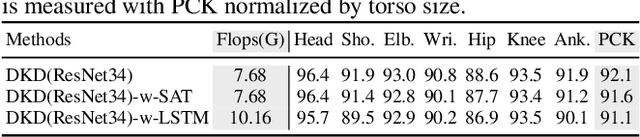
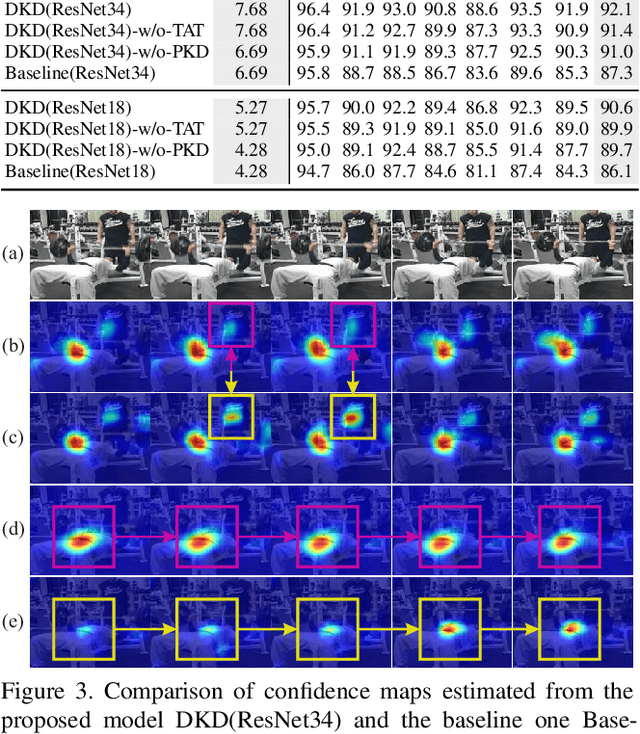
Existing video-based human pose estimation methods extensively apply large networks onto every frame in the video to localize body joints, which suffer high computational cost and hardly meet the low-latency requirement in realistic applications. To address this issue, we propose a novel Dynamic Kernel Distillation (DKD) model to facilitate small networks for estimating human poses in videos, thus significantly lifting the efficiency. In particular, DKD introduces a light-weight distillator to online distill pose kernels via leveraging temporal cues from the previous frame in a one-shot feed-forward manner. Then, DKD simplifies body joint localization into a matching procedure between the pose kernels and the current frame, which can be efficiently computed via simple convolution. In this way, DKD fast transfers pose knowledge from one frame to provide compact guidance for body joint localization in the following frame, which enables utilization of small networks in video-based pose estimation. To facilitate the training process, DKD exploits a temporally adversarial training strategy that introduces a temporal discriminator to help generate temporally coherent pose kernels and pose estimation results within a long range. Experiments on Penn Action and Sub-JHMDB benchmarks demonstrate outperforming efficiency of DKD, specifically, 10x flops reduction and 2x speedup over previous best model, and its state-of-the-art accuracy.
PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
Aug 18, 2019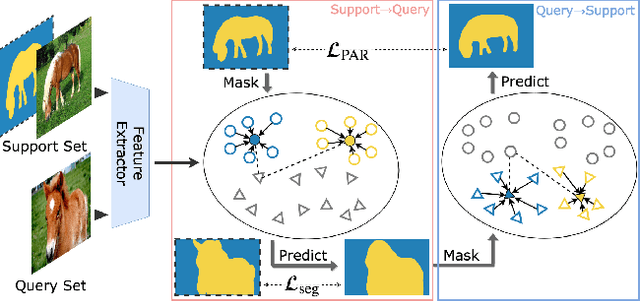
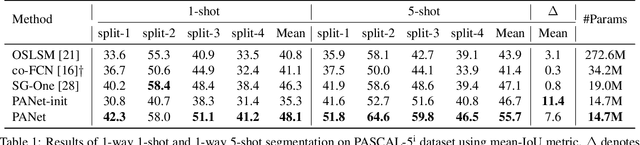
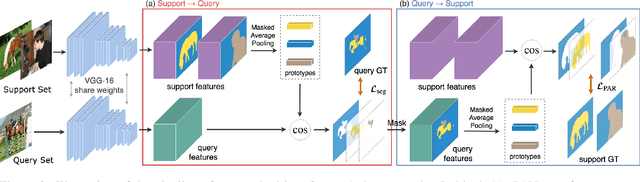
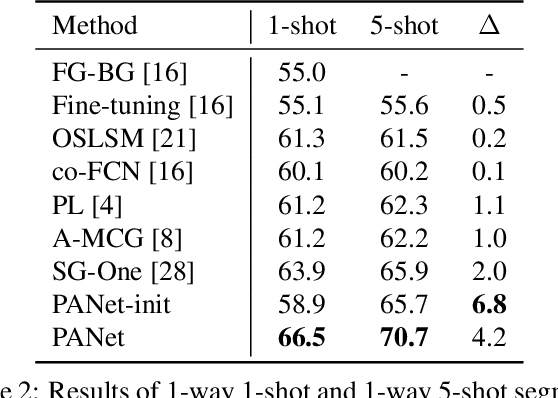
Despite the great progress made by deep CNNs in image semantic segmentation, they typically require a large number of densely-annotated images for training and are difficult to generalize to unseen object categories. Few-shot segmentation has thus been developed to learn to perform segmentation from only a few annotated examples. In this paper, we tackle the challenging few-shot segmentation problem from a metric learning perspective and present PANet, a novel prototype alignment network to better utilize the information of the support set. Our PANet learns class-specific prototype representations from a few support images within an embedding space and then performs segmentation over the query images through matching each pixel to the learned prototypes. With non-parametric metric learning, PANet offers high-quality prototypes that are representative for each semantic class and meanwhile discriminative for different classes. Moreover, PANet introduces a prototype alignment regularization between support and query. With this, PANet fully exploits knowledge from the support and provides better generalization on few-shot segmentation. Significantly, our model achieves the mIoU score of 48.1% and 55.7% on PASCAL-5i for 1-shot and 5-shot settings respectively, surpassing the state-of-the-art method by 1.8% and 8.6%.
Central Similarity Hashing via Hadamard matrix
Aug 01, 2019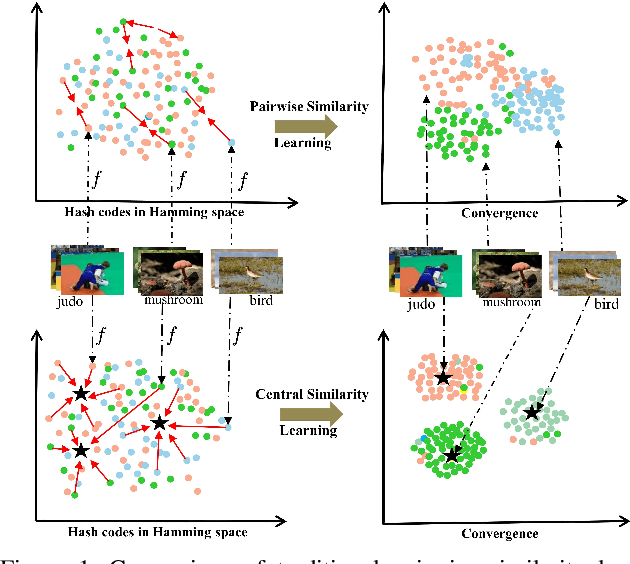
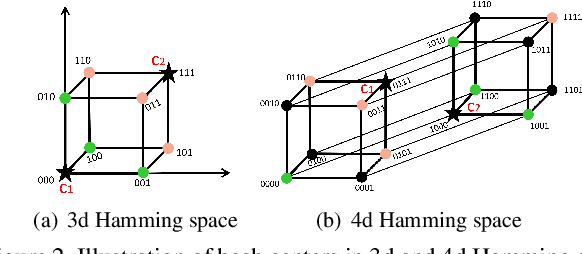
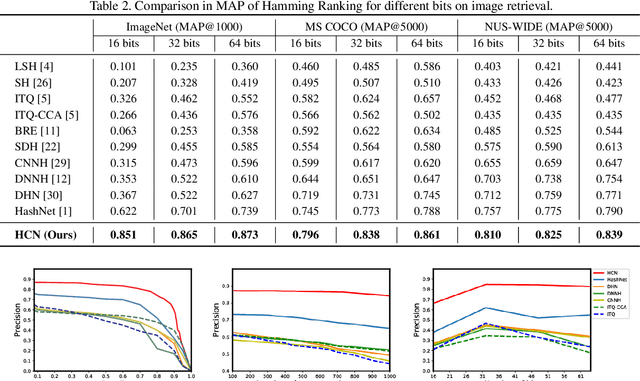
Hashing has been widely used for efficient large-scale multimedia data retrieval. Most existing methods learn hashing functions from data pairwise similarity to generate binary hash codes. However, in practice we find only learning from the local relationships of pairwise similarity cannot capture the global distribution of large-scale data, which would degrade the discriminability of the generated hash codes and harm the retrieval performance. To overcome this limitation, we propose a new global similarity metric, termed as \emph{central similarity}, to learn better hashing functions. The target of central similarity learning is to encourage hash codes for similar data pairs to be close to a common center and those for dissimilar pairs to converge to different centers in the Hamming space, which substantially improves retrieval accuracy. In order to principally formulate the central similarity learning, we define a new concept, \emph{hash center}, to be a set of points scattered in the Hamming space with a sufficient distance between each other, and propose to use Hadamard matrix to construct high-quality hash centers efficiently. Based on these definitions and designs, we devise a new hash center network (HCN) that learns hashing functions by optimizing the central similarity w.r.t.\ these hash centers. The central similarity learning and HCN are generic and can be applied for both image and video hashing. Extensive experiments for both image and video retrieval demonstrate HCN can generate cohesive hash codes for similar data pairs and dispersed hash codes for dissimilar pairs, and achieve noticeable boost in retrieval performance, i.e. 4\%-13\% in MAP over latest state-of-the-arts. The codes are in: \url{https://github.com/yuanli2333/Hadamard-Matrix-for-hashing}
Deep Model Compression via Filter Auto-sampling
Jul 12, 2019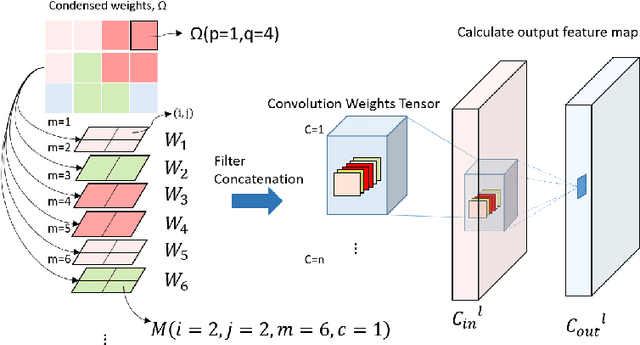

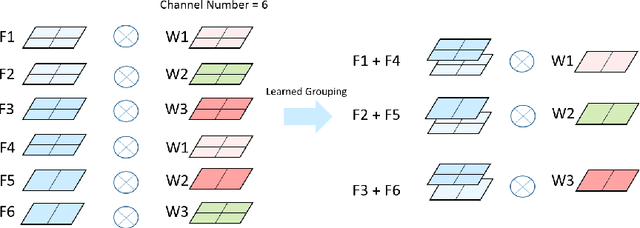
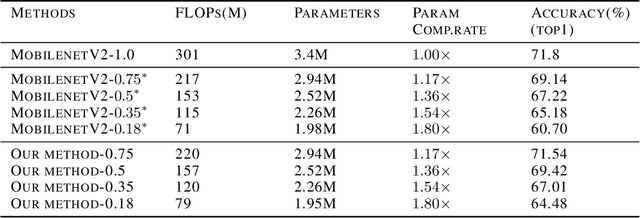
The recent WSNet [1] is a new model compression method through sampling filterweights from a compact set and has demonstrated to be effective for 1D convolutionneural networks (CNNs). However, the weights sampling strategy of WSNet ishandcrafted and fixed which may severely limit the expression ability of the resultedCNNs and weaken its compression ability. In this work, we present a novel auto-sampling method that is applicable to both 1D and 2D CNNs with significantperformance improvement over WSNet. Specifically, our proposed auto-samplingmethod learns the sampling rules end-to-end instead of being independent of thenetwork architecture design. With such differentiable weight sampling rule learning,the sampling stride and channel selection from the compact set are optimized toachieve better trade-off between model compression rate and performance. Wedemonstrate that at the same compression ratio, our method outperforms WSNetby6.5% on 1D convolution. Moreover, on ImageNet, our method outperformsMobileNetV2 full model by1.47%in classification accuracy with25%FLOPsreduction. With the same backbone architecture as baseline models, our methodeven outperforms some neural architecture search (NAS) based methods such asAMC [2] and MNasNet [3].