 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-layer Feature Pyramid Network for Salient Object Detection
Feb 25, 2020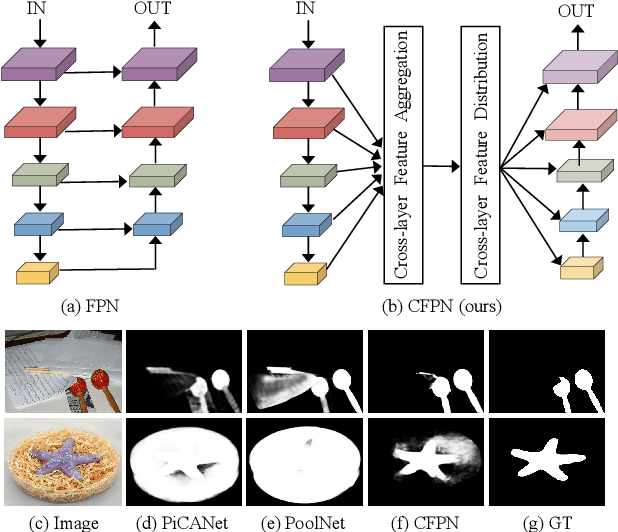
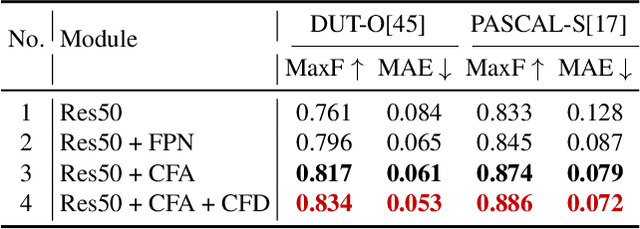
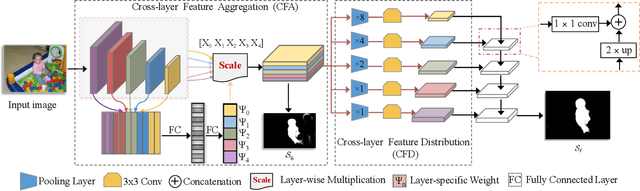
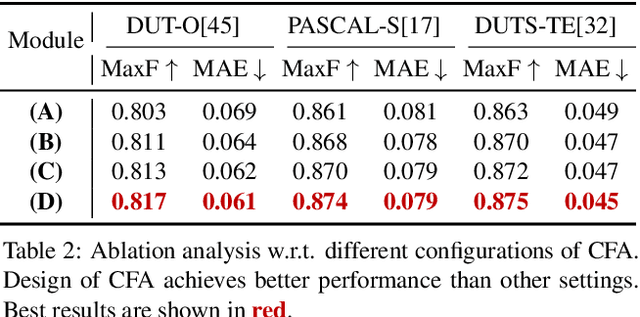
Feature pyramid network (FPN) based models, which fuse the semantics and salient details in a progressive manner, have been proven highly effective in salient object detection. However, it is observed that these models often generate saliency maps with incomplete object structures or unclear object boundaries, due to the \emph{indirect} information propagation among distant layers that makes such fusion structure less effective. In this work, we propose a novel Cross-layer Feature Pyramid Network (CFPN), in which direct cross-layer communication is enabled to improve the progressive fusion in salient object detection. Specifically, the proposed network first aggregates multi-scale features from different layers into feature maps that have access to both the high- and low-level information. Then, it distributes the aggregated features to all the involved layers to gain access to richer context. In this way, the distributed features per layer own both semantics and salient details from all other layers simultaneously, and suffer reduced loss of important information. Extensive experimental results over six widely used salient object detection benchmarks and with three popular backbones clearly demonstrate that CFPN can accurately locate fairly complete salient regions and effectively segment the object boundaries.
Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation
Feb 20, 2020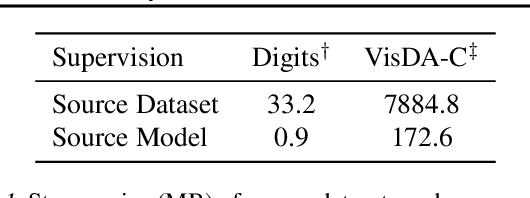
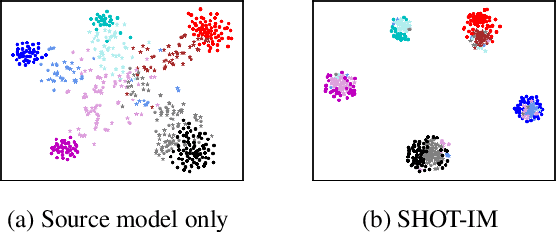
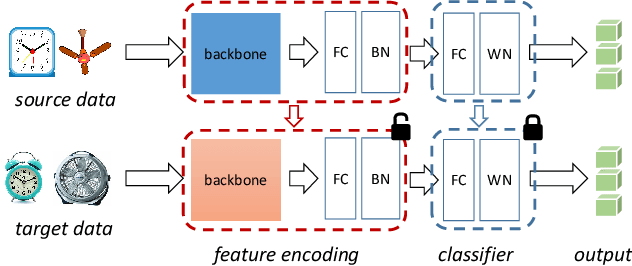
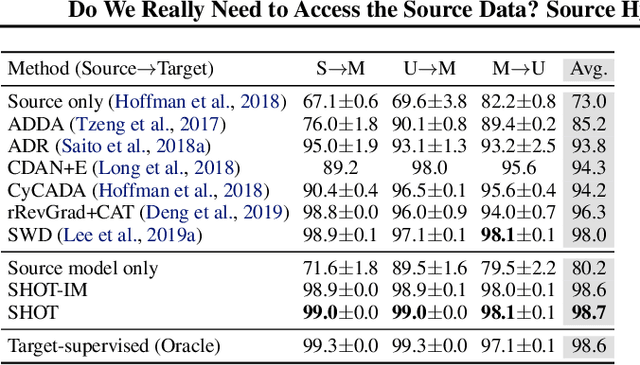
Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from a labeled source dataset to solve similar tasks in a new unlabeled domain. Prior UDA methods typically require to access the source data when learning to adapt the model, making them risky and inefficient for decentralized private data. In this work we tackle a novel setting where only a trained source model is available and investigate how we can effectively utilize such a model without source data to solve UDA problems. To this end, we propose a simple yet generic representation learning framework, named \emph{Source HypOthesis Transfer} (SHOT). Specifically, SHOT freezes the classifier module (hypothesis) of the source model and learns the target-specific feature extraction module by exploiting both information maximization and self-supervised pseudo-labeling to implicitly align representations from the target domains to the source hypothesis. In this way, the learned target model can directly predict the labels of target data. We further investigate several techniques to refine the network architecture to parameterize the source model for better transfer performance. To verify its versatility, we evaluate SHOT in a variety of adaptation cases including closed-set, partial-set, and open-set domain adaptation. Experiments indicate that SHOT yields state-of-the-art results among multiple domain adaptation benchmarks.
MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection
Feb 13, 2020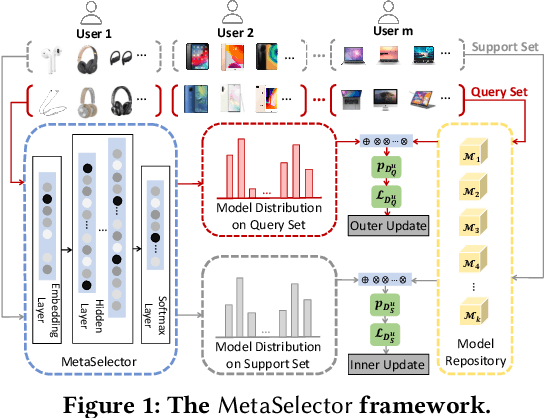
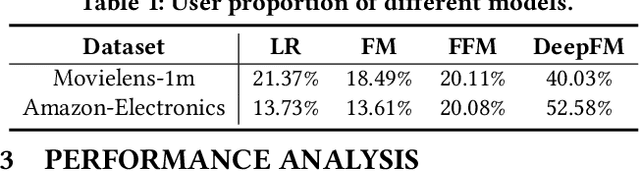
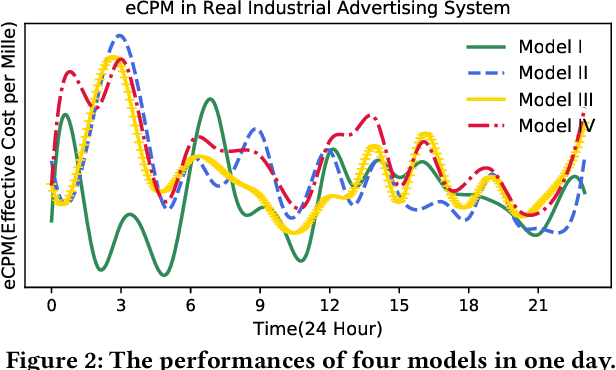
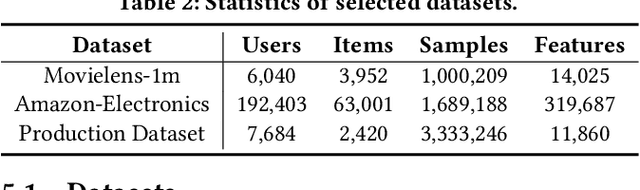
Recommender systems often face heterogeneous datasets containing highly personalized historical data of users, where no single model could give the best recommendation for every user. We observe this ubiquitous phenomenon on both public and private datasets and address the model selection problem in pursuit of optimizing the quality of recommendation for each user. We propose a meta-learning framework to facilitate user-level adaptive model selection in recommender systems. In this framework, a collection of recommenders is trained with data from all users, on top of which a model selector is trained via meta-learning to select the best single model for each user with the user-specific historical data. We conduct extensive experiments on two public datasets and a real-world production dataset, demonstrating that our proposed framework achieves improvements over single model baselines and sample-level model selector in terms of AUC and LogLoss. In particular, the improvements may lead to huge profit gain when deployed in online recommender systems.
ReClor: A Reading Comprehension Dataset Requiring Logical Reasoning
Feb 11, 2020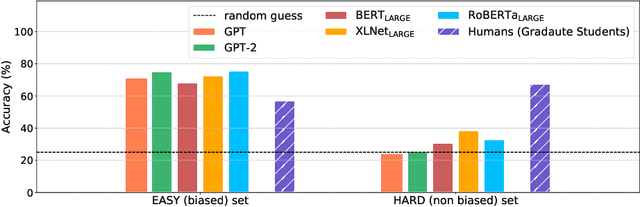

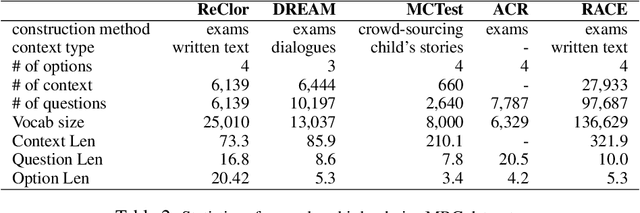

Recent powerful pre-trained language models have achieved remarkable performance on most of the popular datasets for reading comprehension. It is time to introduce more challenging datasets to push the development of this field towards more comprehensive reasoning of text. In this paper, we introduce a new Reading Comprehension dataset requiring logical reasoning (ReClor) extracted from standardized graduate admission examinations. As earlier studies suggest, human-annotated datasets usually contain biases, which are often exploited by models to achieve high accuracy without truly understanding the text. In order to comprehensively evaluate the logical reasoning ability of models on ReClor, we propose to identify biased data points and separate them into EASY set while the rest as HARD set. Empirical results show that state-of-the-art models have an outstanding ability to capture biases contained in the dataset with high accuracy on EASY set. However, they struggle on HARD set with poor performance near that of random guess, indicating more research is needed to essentially enhance the logical reasoning ability of current models.
PPDM: Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection
Dec 30, 2019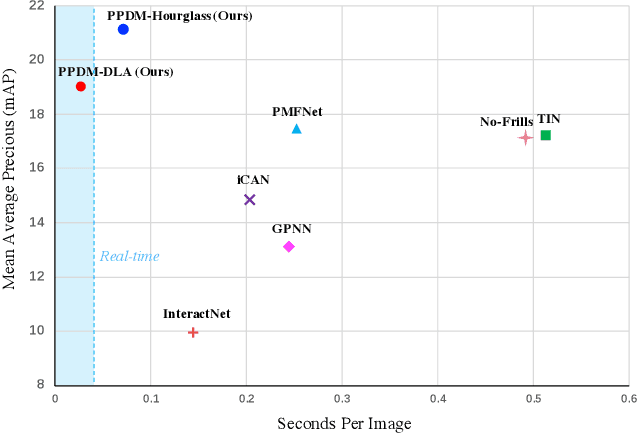
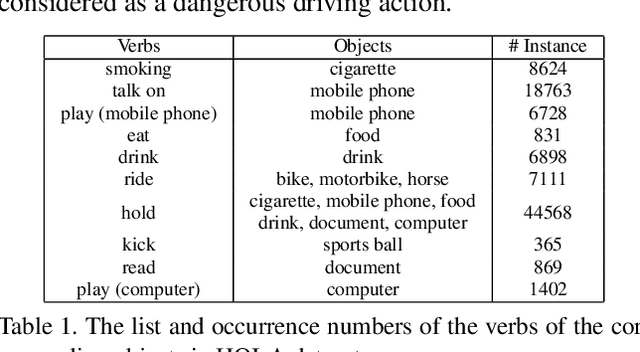
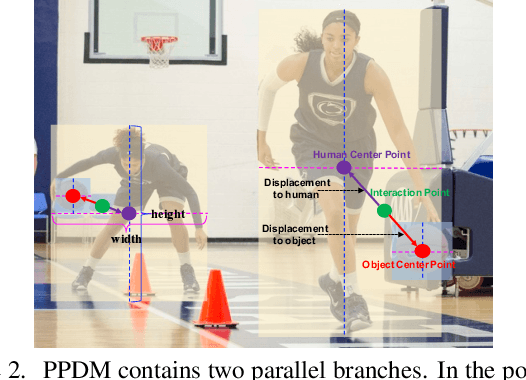
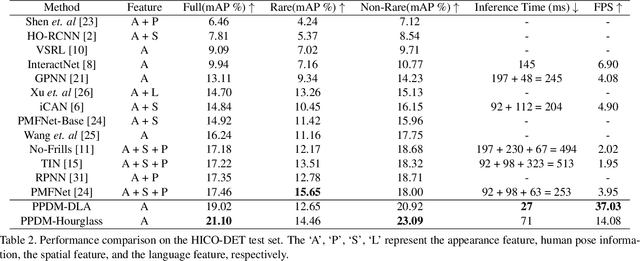
We propose a single-stage Human-Object Interaction (HOI) detection method that has outperformed all existing methods on HICO-DET dataset at 37 fps on a single Titan XP GPU. It is the first real-time HOI detection method. Conventional HOI detection methods are composed of two stages, i.e., human-object proposals generation, and proposals classification. Their effectiveness and efficiency are limited by the sequential and separate architecture. In this paper, we propose a Parallel Point Detection and Matching (PPDM) HOI detection framework. In PPDM, an HOI is defined as a point triplet < human point, interaction point, object point>. Human and object points are the center of the detection boxes, and the interaction point is the midpoint of the human and object points. PPDM contains two parallel branches, namely point detection branch and point matching branch. The point detection branch predicts three points. Simultaneously, the point matching branch predicts two displacements from the interaction point to its corresponding human and object points. The human point and the object point originated from the same interaction point are considered as matched pairs. In our novel parallel architecture, the interaction points implicitly provide context and regularization for human and object detection. The isolated detection boxes are unlikely to form meaning HOI triplets are suppressed, which increases the precision of HOI detection. Moreover, the matching between human and object detection boxes is only applied around limited numbers of filtered candidate interaction points, which saves much computational cost. Additionally, we build a new applicationoriented database named HOI-A, which severs as a good supplement to the existing datasets. The source code and the dataset will be made publicly available to facilitate the development of HOI detection.
RC-DARTS: Resource Constrained Differentiable Architecture Search
Dec 30, 2019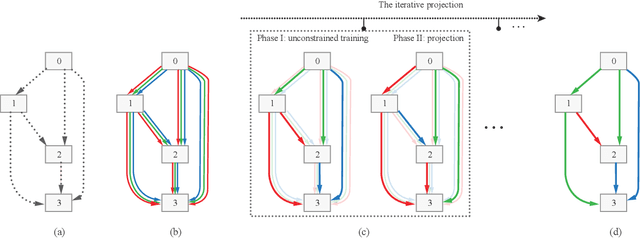
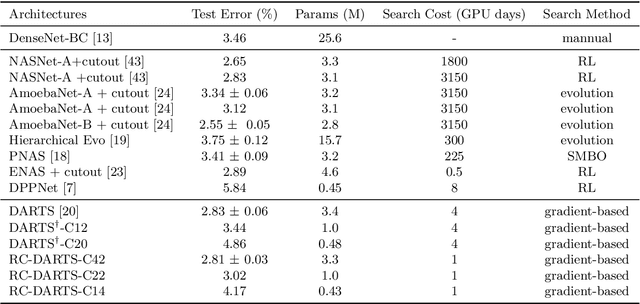
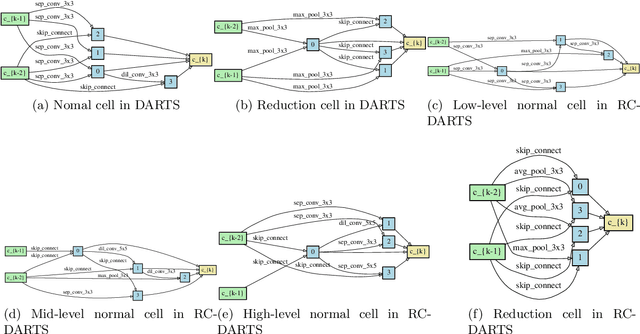
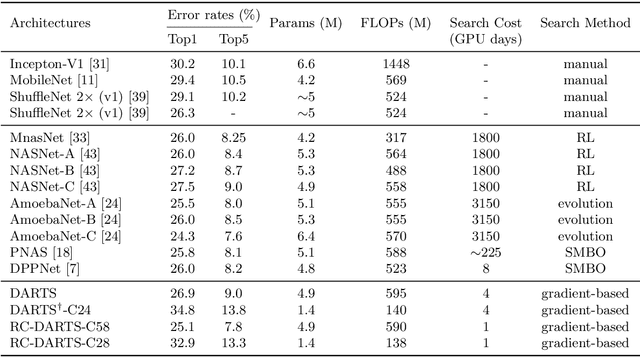
Recent advances show that Neural Architectural Search (NAS) method is able to find state-of-the-art image classification deep architectures. In this paper, we consider the one-shot NAS problem for resource constrained applications. This problem is of great interest because it is critical to choose different architectures according to task complexity when the resource is constrained. Previous techniques are either too slow for one-shot learning or does not take the resource constraint into consideration. In this paper, we propose the resource constrained differentiable architecture search (RC-DARTS) method to learn architectures that are significantly smaller and faster while achieving comparable accuracy. Specifically, we propose to formulate the RC-DARTS task as a constrained optimization problem by adding the resource constraint. An iterative projection method is proposed to solve the given constrained optimization problem. We also propose a multi-level search strategy to enable layers at different depths to adaptively learn different types of neural architectures. Through extensive experiments on the Cifar10 and ImageNet datasets, we show that the RC-DARTS method learns lightweight neural architectures which have smaller model size and lower computational complexity while achieving comparable or better performances than the state-of-the-art methods.
Zoom in to where it matters: a hierarchical graph based model for mammogram analysis
Dec 16, 2019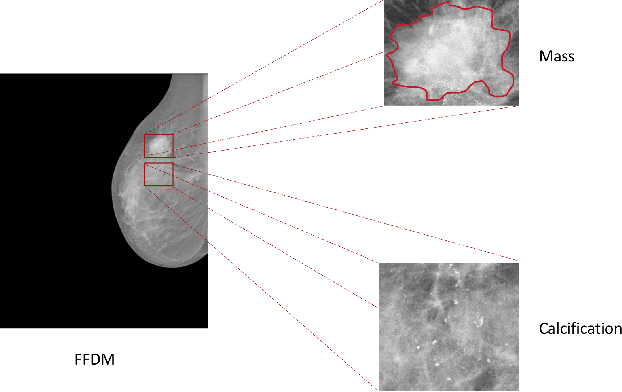
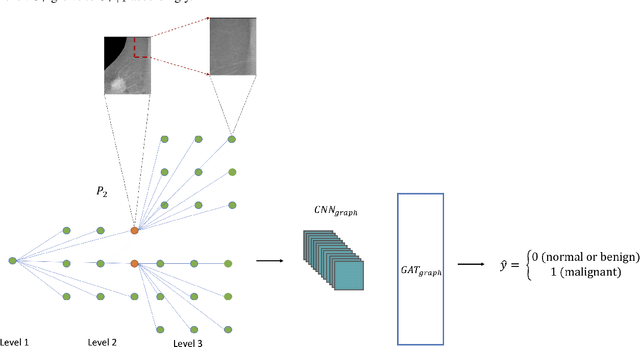
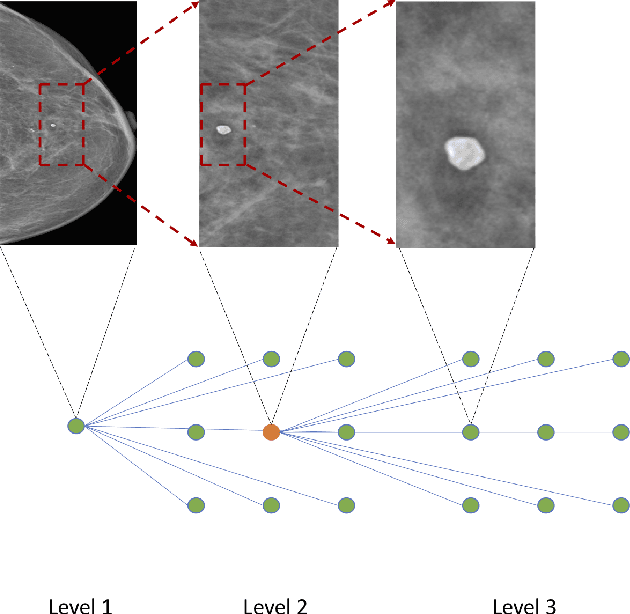
In clinical practice, human radiologists actually review medical images with high resolution monitors and zoom into region of interests (ROIs) for a close-up examination. Inspired by this observation, we propose a hierarchical graph neural network to detect abnormal lesions from medical images by automatically zooming into ROIs. We focus on mammogram analysis for breast cancer diagnosis for this study. Our proposed network consist of two graph attention networks performing two tasks: (1) node classification to predict whether to zoom into next level; (2) graph classification to classify whether a mammogram is normal/benign or malignant. The model is trained and evaluated on INbreast dataset and we obtain comparable AUC with state-of-the-art methods.
Efficient Differentiable Neural Architecture Search with Meta Kernels
Dec 10, 2019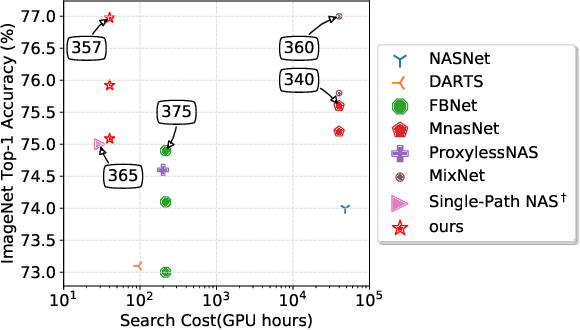
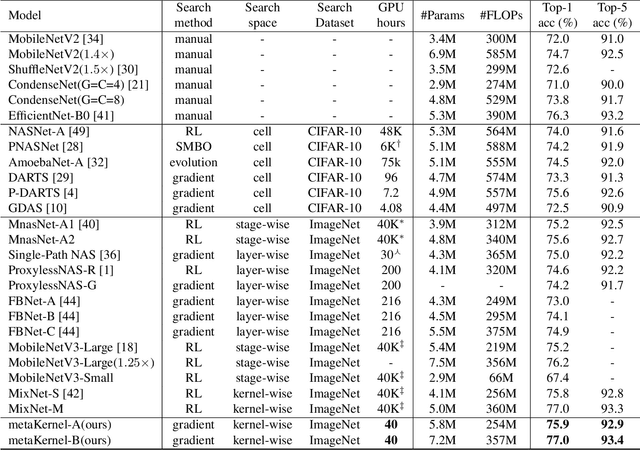
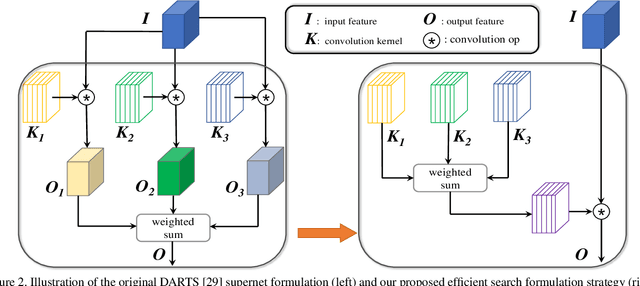

The searching procedure of neural architecture search (NAS) is notoriously time consuming and cost prohibitive.To make the search space continuous, most existing gradient-based NAS methods relax the categorical choice of a particular operation to a softmax over all possible operations and calculate the weighted sum of multiple features, resulting in a large memory requirement and a huge computation burden. In this work, we propose an efficient and novel search strategy with meta kernels. We directly encode the supernet from the perspective on convolution kernels and "shrink" multiple convolution kernel candidates into a single one before these candidates operate on the input feature. In this way, only a single feature is generated between two intermediate nodes. The memory for storing intermediate features and the resource budget for conducting convolution operations are both reduced remarkably. Despite high efficiency, our search strategy can search in a more fine-grained way than existing works and increases the capacity for representing possible networks. We demonstrate the effectiveness of our search strategy by conducting extensive experiments. Specifically, our method achieves 77.0% top-1 accuracy on ImageNet benchmark dataset with merely 357M FLOPs, outperforming both EfficientNet and MobileNetV3 under the same FLOPs constraints. Compared to models discovered by the start-of-the-art NAS method, our method achieves the same (sometimes even better) performance, while faster by three orders of magnitude.
Classification Calibration for Long-tail Instance Segmentation
Nov 02, 2019

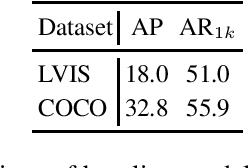

Remarkable progress has been made in object instance detection and segmentation in recent years. However, existing state-of-the-art methods are mostly evaluated with fairly balanced and class-limited benchmarks, such as Microsoft COCO dataset [8]. In this report, we investigate the performance drop phenomenon of state-of-the-art two-stage instance segmentation models when processing extreme long-tail training data based on the LVIS [5] dataset, and find a major cause is the inaccurate classification of object proposals. Based on this observation, we propose to calibrate the prediction of classification head to improve recognition performance for the tail classes. Without much additional cost and modification of the detection model architecture, our calibration method improves the performance of the baseline by a large margin on the tail classes. Codes will be available. Importantly, after the submission, we find significant improvement can be further achieved by modifying the calibration head, which we will update later.
Decoupling Representation and Classifier for Long-Tailed Recognition
Oct 21, 2019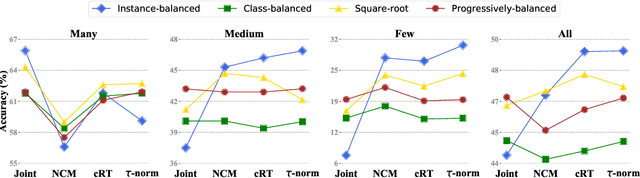
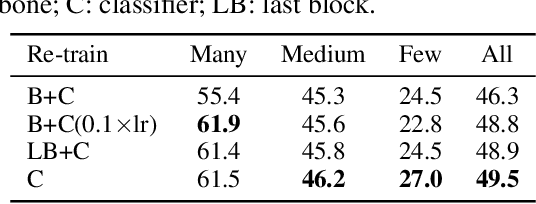
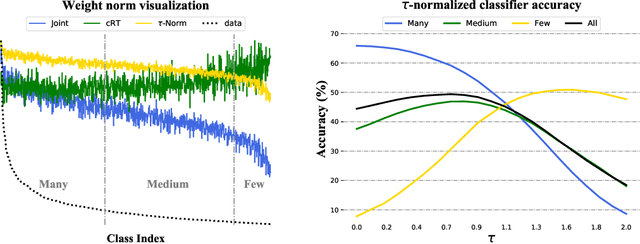
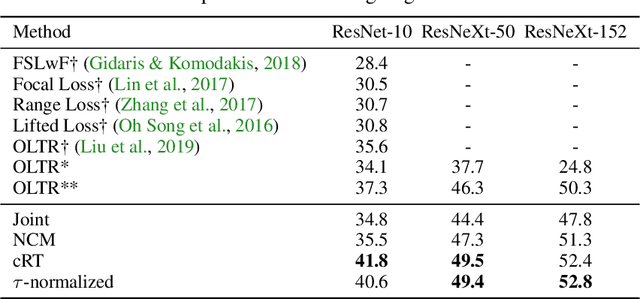
The long-tail distribution of the visual world poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balancing strategies, e.g., by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classifiers. In this work, we decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition. The findings are surprising: (1) data imbalance might not be an issue in learning high-quality representations; (2) with representations learned with the simplest instance-balanced (natural) sampling, it is also possible to achieve strong long-tailed recognition ability at little cost by adjusting only the classifier. We conduct extensive experiments and set new state-of-the-art performance on common long-tailed benchmarks like ImageNet-LT, Places-LT and iNaturalist, showing that it is possible to outperform carefully designed losses, sampling strategies, even complex modules with memory, by using a straightforward approach that decouples representation and classification.