 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Rules Learn: A Self-Evolving Agent for Legal Case Retrieval
Jun 15, 2026Legal case retrieval remains challenging due to the complexity of legal language and the need for precise lexical alignment between queries and relevant cases. Although dense retrieval models have achieved notable progress, empirical studies show that BM25 continues to serve as a strong baseline in this domain. It motivates us to propose a self-evolving framework for rule-driven query rewriting that enhances BM25 without any parameter training. The framework equips an LLM-based agent with an automatic evaluation environment, enabling it to iteratively create rewriting rules, plan validation experiments over rule combinations, and eliminate ineffective rules based on historical feedbacks. We evaluate our method on the Chinese legal case retrieval benchmark LeCaRD-v2. Experimental results demonstrate that the proposed framework outperforms non-evolutionary baselines, including human-designed rules and greedy rule selection, particularly when powered by a highcapacity core LLM. We also conduct detailed analyses to investigate the mechanisms underlying self-evolution. Our findings reveal that LLM's capabilities to leverage previous experimental results and its intrinsic knowledge of rule elimination play critical roles in refining the rule set via self-evolution.
SalM$2$: An Extremely Lightweight Saliency Mamba Model for Real-Time Cognitive Awareness of Driver Attention
Feb 22, 2025



Driver attention recognition in driving scenarios is a popular direction in traffic scene perception technology. It aims to understand human driver attention to focus on specific targets/objects in the driving scene. However, traffic scenes contain not only a large amount of visual information but also semantic information related to driving tasks. Existing methods lack attention to the actual semantic information present in driving scenes. Additionally, the traffic scene is a complex and dynamic process that requires constant attention to objects related to the current driving task. Existing models, influenced by their foundational frameworks, tend to have large parameter counts and complex structures. Therefore, this paper proposes a real-time saliency Mamba network based on the latest Mamba framework. As shown in Figure 1, our model uses very few parameters (0.08M, only 0.09~11.16% of other models), while maintaining SOTA performance or achieving over 98% of the SOTA model's performance.
One-shot Video Imitation via Parameterized Symbolic Abstraction Graphs
Aug 22, 2024



Learning to manipulate dynamic and deformable objects from a single demonstration video holds great promise in terms of scalability. Previous approaches have predominantly focused on either replaying object relationships or actor trajectories. The former often struggles to generalize across diverse tasks, while the latter suffers from data inefficiency. Moreover, both methodologies encounter challenges in capturing invisible physical attributes, such as forces. In this paper, we propose to interpret video demonstrations through Parameterized Symbolic Abstraction Graphs (PSAG), where nodes represent objects and edges denote relationships between objects. We further ground geometric constraints through simulation to estimate non-geometric, visually imperceptible attributes. The augmented PSAG is then applied in real robot experiments. Our approach has been validated across a range of tasks, such as Cutting Avocado, Cutting Vegetable, Pouring Liquid, Rolling Dough, and Slicing Pizza. We demonstrate successful generalization to novel objects with distinct visual and physical properties.
HyperDID: Hyperspectral Intrinsic Image Decomposition with Deep Feature Embedding
Nov 25, 2023



The dissection of hyperspectral images into intrinsic components through hyperspectral intrinsic image decomposition (HIID) enhances the interpretability of hyperspectral data, providing a foundation for more accurate classification outcomes. However, the classification performance of HIID is constrained by the model's representational ability. To address this limitation, this study rethinks hyperspectral intrinsic image decomposition for classification tasks by introducing deep feature embedding. The proposed framework, HyperDID, incorporates the Environmental Feature Module (EFM) and Categorical Feature Module (CFM) to extract intrinsic features. Additionally, a Feature Discrimination Module (FDM) is introduced to separate environment-related and category-related features. Experimental results across three commonly used datasets validate the effectiveness of HyperDID in improving hyperspectral image classification performance. This novel approach holds promise for advancing the capabilities of hyperspectral image analysis by leveraging deep feature embedding principles. The implementation of the proposed method could be accessed soon at https://github.com/shendu-sw/HyperDID for the sake of reproducibility.
Deep Intrinsic Decomposition with Adversarial Learning for Hyperspectral Image Classification
Oct 28, 2023



Convolutional neural networks (CNNs) have been demonstrated their powerful ability to extract discriminative features for hyperspectral image classification. However, general deep learning methods for CNNs ignore the influence of complex environmental factor which enlarges the intra-class variance and decreases the inter-class variance. This multiplies the difficulty to extract discriminative features. To overcome this problem, this work develops a novel deep intrinsic decomposition with adversarial learning, namely AdverDecom, for hyperspectral image classification to mitigate the negative impact of environmental factors on classification performance. First, we develop a generative network for hyperspectral image (HyperNet) to extract the environmental-related feature and category-related feature from the image. Then, a discriminative network is constructed to distinguish different environmental categories. Finally, a environmental and category joint learning loss is developed for adversarial learning to make the deep model learn discriminative features. Experiments are conducted over three commonly used real-world datasets and the comparison results show the superiority of the proposed method. The implementation of the proposed method and other compared methods could be accessed at https://github.com/shendu-sw/Adversarial Learning Intrinsic Decomposition for the sake of reproducibility.
MultiScale Spectral-Spatial Convolutional Transformer for Hyperspectral Image Classification
Oct 28, 2023Due to the powerful ability in capturing the global information, Transformer has become an alternative architecture of CNNs for hyperspectral image classification. However, general Transformer mainly considers the global spectral information while ignores the multiscale spatial information of the hyperspectral image. In this paper, we propose a multiscale spectral-spatial convolutional Transformer (MultiscaleFormer) for hyperspectral image classification. First, the developed method utilizes multiscale spatial patches as tokens to formulate the spatial Transformer and generates multiscale spatial representation of each band in each pixel. Second, the spatial representation of all the bands in a given pixel are utilized as tokens to formulate the spectral Transformer and generate the multiscale spectral-spatial representation of each pixel. Besides, a modified spectral-spatial CAF module is constructed in the MultiFormer to fuse cross-layer spectral and spatial information. Therefore, the proposed MultiFormer can capture the multiscale spectral-spatial information and provide better performance than most of other architectures for hyperspectral image classification. Experiments are conducted over commonly used real-world datasets and the comparison results show the superiority of the proposed method.
Embodied View-Contrastive 3D Feature Learning
Jul 10, 2019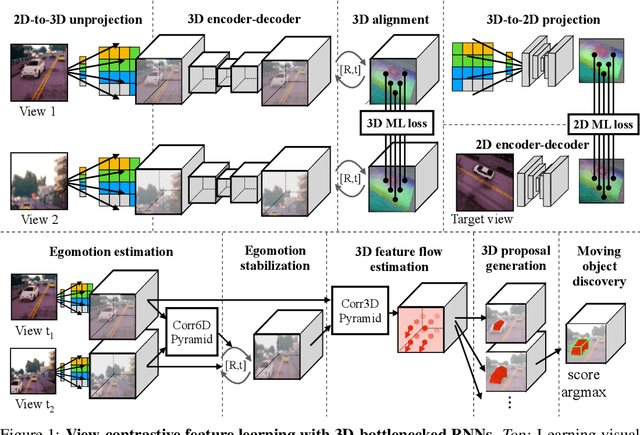
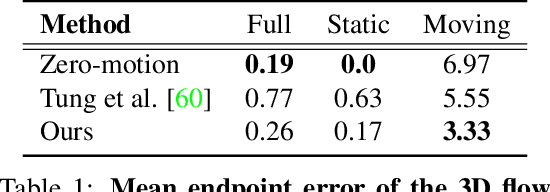

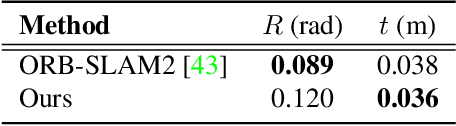
Humans can effortlessly imagine the occluded side of objects in a photograph. We do not simply see the photograph as a flat 2D surface, we perceive the 3D visual world captured in it, by using our imagination to inpaint the information lost during camera projection. We propose neural architectures that similarly learn to approximately imagine abstractions of the 3D world depicted in 2D images. We show that this capability suffices to localize moving objects in 3D, without using any human annotations. Our models are recurrent neural networks that consume RGB or RGB-D videos, and learn to predict novel views of the scene from queried camera viewpoints. They are equipped with a 3D representation bottleneck that learns an egomotion-stabilized and geometrically consistent deep feature map of the 3D world scene. They estimate camera motion from frame to frame, and cancel it from the extracted 2D features before fusing them in the latent 3D map. We handle multimodality and stochasticity in prediction using ranking-based contrastive losses, and show that they can scale to photorealistic imagery, in contrast to regression or VAE alternatives. Our model proposes 3D boxes for moving objects by estimating a 3D motion flow field between its temporally consecutive 3D imaginations, and thresholding motion magnitude: camera motion has been cancelled in the latent 3D space, and thus any non-zero motion is an indication of an independently moving object. Our work underlines the importance of 3D representations and egomotion stabilization for visual recognition, and proposes a viable computational model for learning 3D visual feature representations and 3D object bounding boxes supervised by moving and watching objects move.
Revisiting Flow Information for Traffic Prediction
Jun 03, 2019
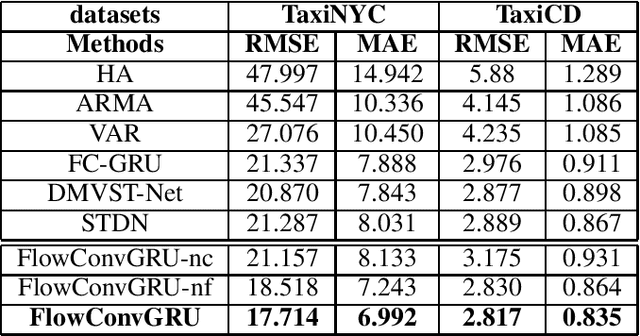
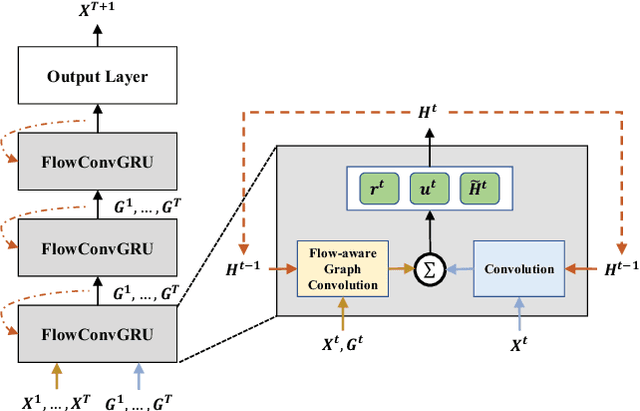
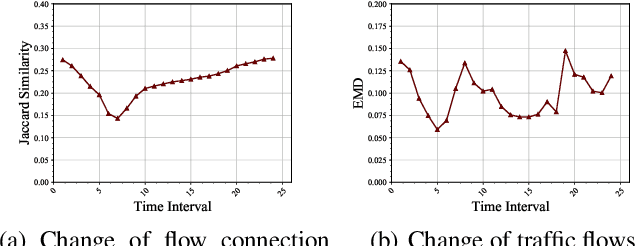
Traffic prediction is a fundamental task in many real applications, which aims to predict the future traffic volume in any region of a city. In essence, traffic volume in a region is the aggregation of traffic flows from/to the region. However, existing traffic prediction methods focus on modeling complex spatiotemporal traffic correlations and seldomly study the influence of the original traffic flows among regions. In this paper, we revisit the traffic flow information and exploit the direct flow correlations among regions towards more accurate traffic prediction. We introduce a novel flow-aware graph convolution to model dynamic flow correlations among regions. We further introduce an integrated Gated Recurrent Unit network to incorporate flow correlations with spatiotemporal modeling. The experimental results on real-world traffic datasets validate the effectiveness of the proposed method, especially on the traffic conditions with a great change on flows.
Closed-Chain Manipulation of Large Objects by Multi-Arm Robotic Systems
Jun 21, 2017
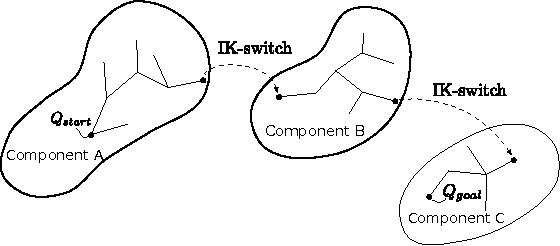
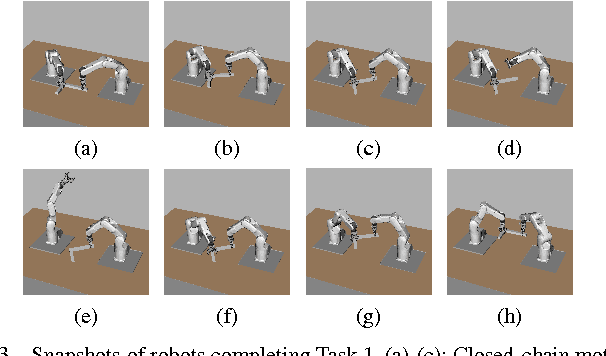

Closed kinematic chains are created whenever multiple robot arms concurrently manipulate a single object. The closed-chain constraint, when coupled with robot joint limits, dramatically changes the connectivity of the configuration space. We propose a regrasping move, termed "IK-switch", which allows efficiently bridging components of the configuration space that are otherwise mutually disconnected. This move, combined with several other developments, such as a method to stabilize the manipulated object using the environment, a new tree structure, and a compliant control scheme, enables us to address complex closed-chain manipulation tasks, such as flipping a chair frame, which is otherwise impossible to realize using existing multi-arm planning methods.