 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomography Loss for Monocular 3D Object Detection
Apr 02, 2022
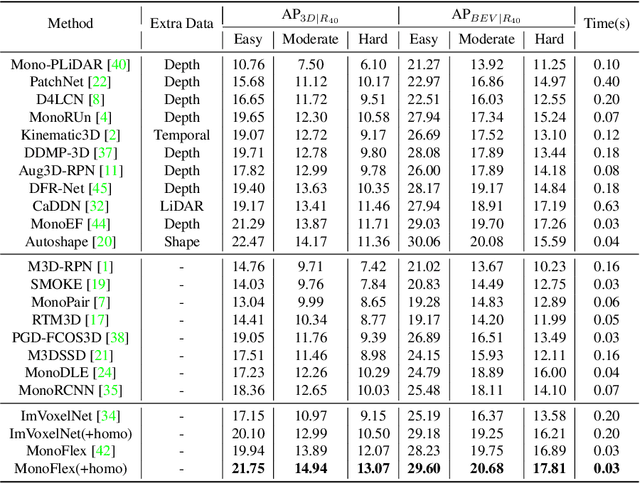
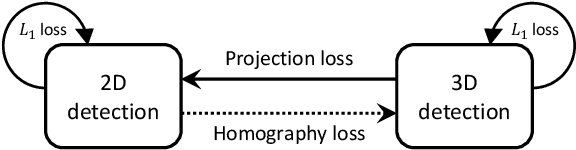
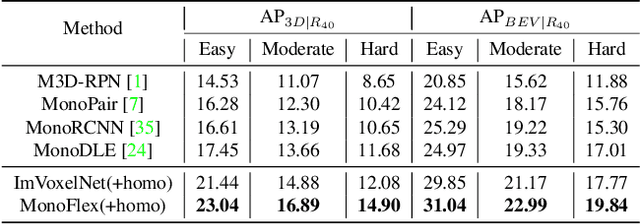
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.
Dynamic Supervisor for Cross-dataset Object Detection
Apr 01, 2022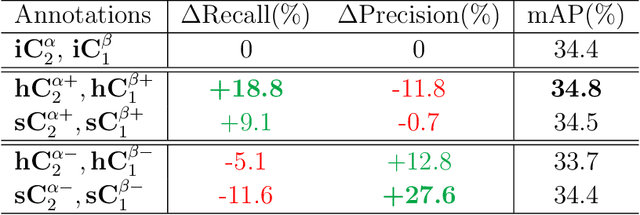
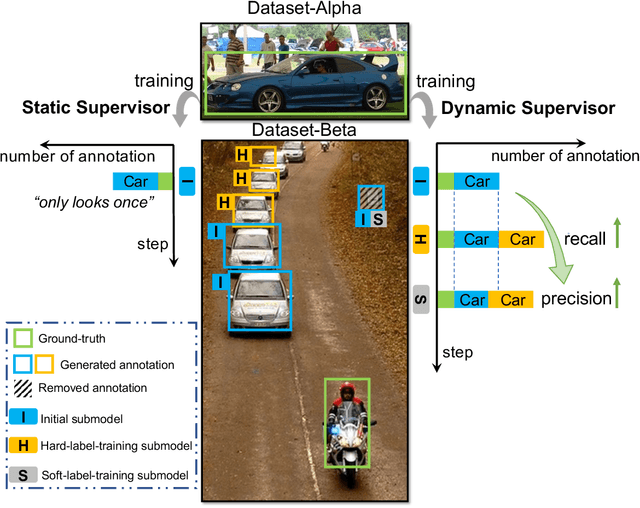

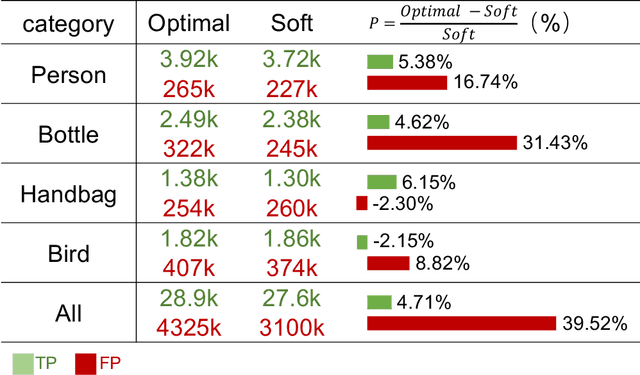
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.
Continual Learning for CTR Prediction: A Hybrid Approach
Jan 18, 2022Click-through rate(CTR) prediction is a core task in cost-per-click(CPC) advertising systems and has been studied extensively by machine learning practitioners. While many existing methods have been successfully deployed in practice, most of them are built upon i.i.d.(independent and identically distributed) assumption, ignoring that the click data used for training and inference is collected through time and is intrinsically non-stationary and drifting. This mismatch will inevitably lead to sub-optimal performance. To address this problem, we formulate CTR prediction as a continual learning task and propose COLF, a hybrid COntinual Learning Framework for CTR prediction, which has a memory-based modular architecture that is designed to adapt, learn and give predictions continuously when faced with non-stationary drifting click data streams. Married with a memory population method that explicitly controls the discrepancy between memory and target data, COLF is able to gain positive knowledge from its historical experience and makes improved CTR predictions. Empirical evaluations on click log collected from a major shopping app in China demonstrate our method's superiority over existing methods. Additionally, we have deployed our method online and observed significant CTR and revenue improvement, which further demonstrates our method's efficacy.
Deconfounded Visual Grounding
Dec 31, 2021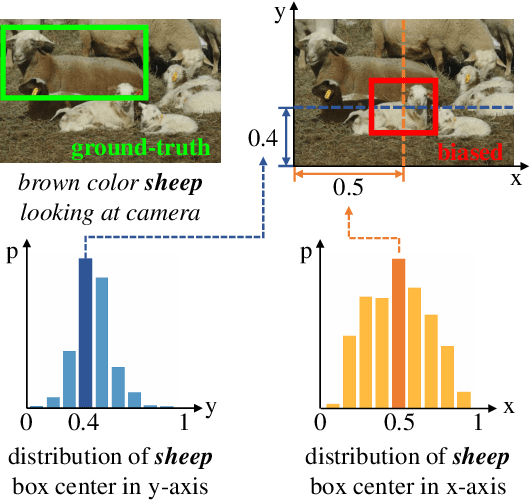
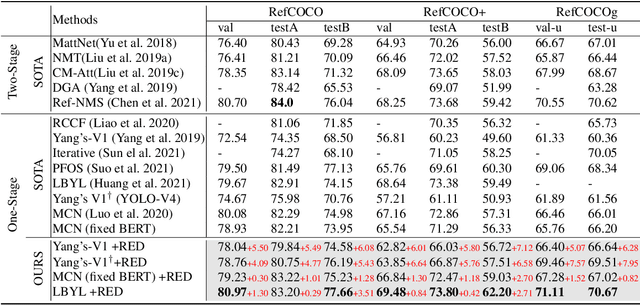
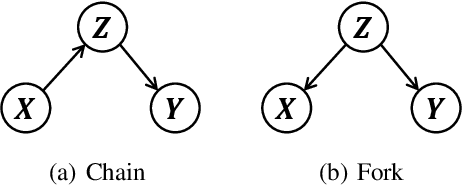
We focus on the confounding bias between language and location in the visual grounding pipeline, where we find that the bias is the major visual reasoning bottleneck. For example, the grounding process is usually a trivial language-location association without visual reasoning, e.g., grounding any language query containing sheep to the nearly central regions, due to that most queries about sheep have ground-truth locations at the image center. First, we frame the visual grounding pipeline into a causal graph, which shows the causalities among image, query, target location and underlying confounder. Through the causal graph, we know how to break the grounding bottleneck: deconfounded visual grounding. Second, to tackle the challenge that the confounder is unobserved in general, we propose a confounder-agnostic approach called: Referring Expression Deconfounder (RED), to remove the confounding bias. Third, we implement RED as a simple language attention, which can be applied in any grounding method. On popular benchmarks, RED improves various state-of-the-art grounding methods by a significant margin. Code will soon be available at: https://github.com/JianqiangH/Deconfounded_VG.
AutoHEnsGNN: Winning Solution to AutoGraph Challenge for KDD Cup 2020
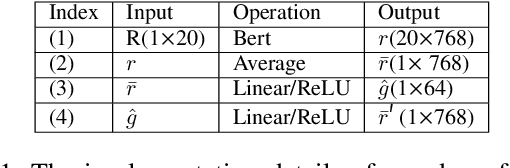
Nov 25, 2021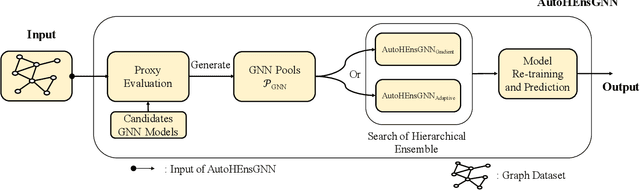
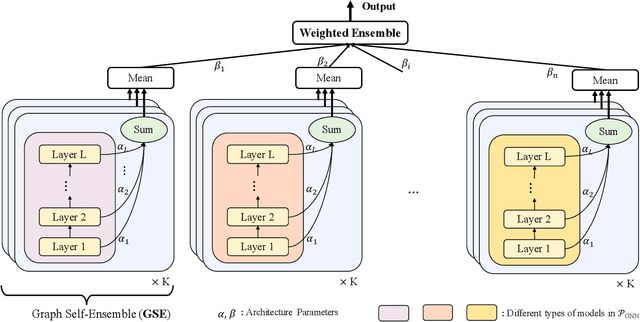
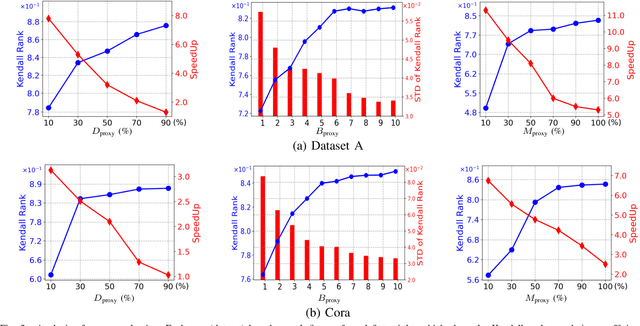
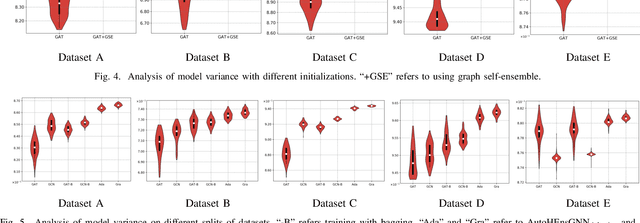
Graph Neural Networks (GNNs) have become increasingly popular and achieved impressive results in many graph-based applications. However, extensive manual work and domain knowledge are required to design effective architectures, and the results of GNN models have high variance with different training setups, which limits the application of existing GNN models. In this paper, we present AutoHEnsGNN, a framework to build effective and robust models for graph tasks without any human intervention. AutoHEnsGNN won first place in the AutoGraph Challenge for KDD Cup 2020, and achieved the best rank score of five real-life datasets in the final phase. Given a task, AutoHEnsGNN first applies a fast proxy evaluation to automatically select a pool of promising GNN models. Then it builds a hierarchical ensemble framework: 1) We propose graph self-ensemble (GSE), which can reduce the variance of weight initialization and efficiently exploit the information of local and global neighborhoods; 2) Based on GSE, a weighted ensemble of different types of GNN models is used to effectively learn more discriminative node representations. To efficiently search the architectures and ensemble weights, we propose AutoHEnsGNN$_{\text{Gradient}}$, which treats the architectures and ensemble weights as architecture parameters and uses gradient-based architecture search to obtain optimal configurations, and AutoHEnsGNN$_{\text{Adaptive}}$, which can adaptively adjust the ensemble weight based on the model accuracy. Extensive experiments on node classification, graph classification, edge prediction and KDD Cup challenge demonstrate the effectiveness and generality of AutoHEnsGNN
Meta Clustering Learning for Large-scale Unsupervised Person Re-identification
Nov 19, 2021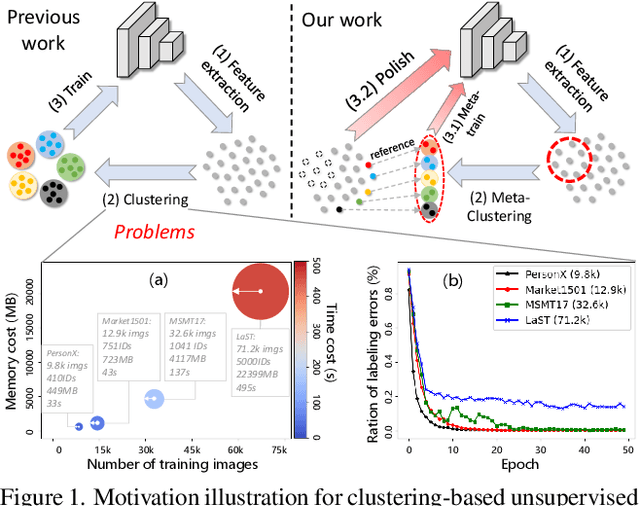
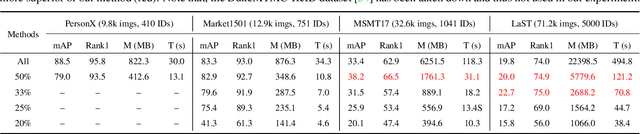
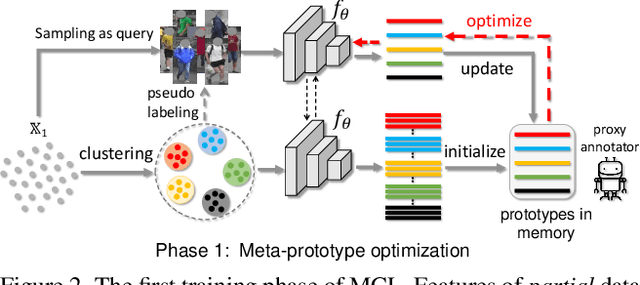
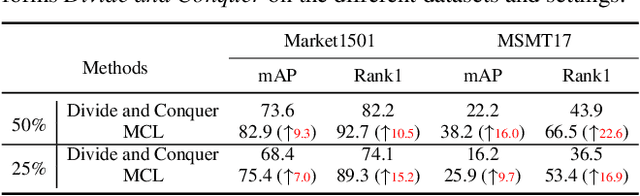
Unsupervised Person Re-identification (U-ReID) with pseudo labeling recently reaches a competitive performance compared to fully-supervised ReID methods based on modern clustering algorithms. However, such clustering-based scheme becomes computationally prohibitive for large-scale datasets. How to efficiently leverage endless unlabeled data with limited computing resources for better U-ReID is under-explored. In this paper, we make the first attempt to the large-scale U-ReID and propose a "small data for big task" paradigm dubbed Meta Clustering Learning (MCL). MCL only pseudo-labels a subset of the entire unlabeled data via clustering to save computing for the first-phase training. After that, the learned cluster centroids, termed as meta-prototypes in our MCL, are regarded as a proxy annotator to softly annotate the rest unlabeled data for further polishing the model. To alleviate the potential noisy labeling issue in the polishment phase, we enforce two well-designed loss constraints to promise intra-identity consistency and inter-identity strong correlation. For multiple widely-used U-ReID benchmarks, our method significantly saves computational cost while achieving a comparable or even better performance compared to prior works.
Self-Supervised Learning Disentangled Group Representation as Feature
Oct 29, 2021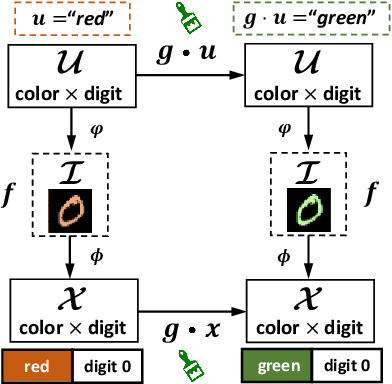
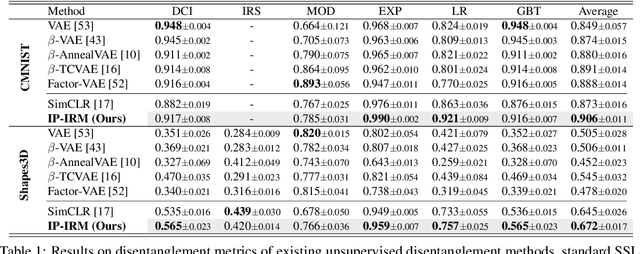
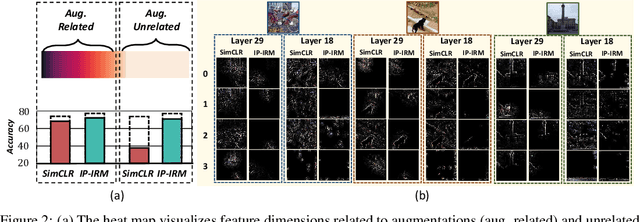
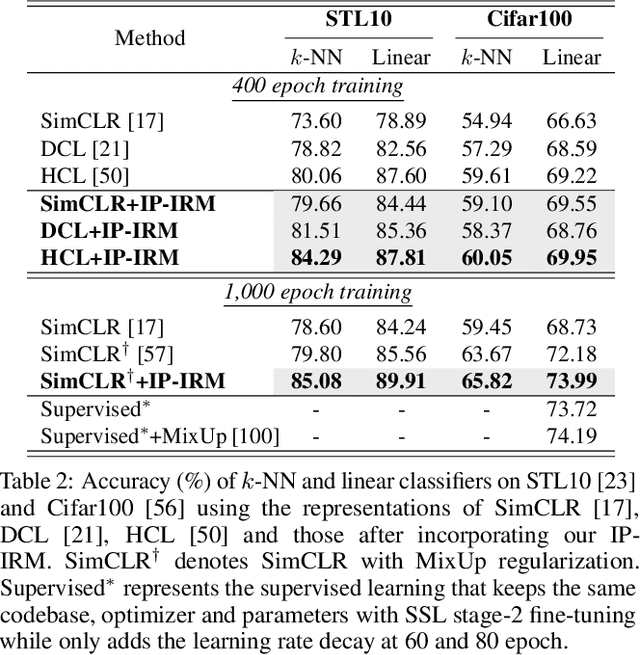
A good visual representation is an inference map from observations (images) to features (vectors) that faithfully reflects the hidden modularized generative factors (semantics). In this paper, we formulate the notion of "good" representation from a group-theoretic view using Higgins' definition of disentangled representation, and show that existing Self-Supervised Learning (SSL) only disentangles simple augmentation features such as rotation and colorization, thus unable to modularize the remaining semantics. To break the limitation, we propose an iterative SSL algorithm: Iterative Partition-based Invariant Risk Minimization (IP-IRM), which successfully grounds the abstract semantics and the group acting on them into concrete contrastive learning. At each iteration, IP-IRM first partitions the training samples into two subsets that correspond to an entangled group element. Then, it minimizes a subset-invariant contrastive loss, where the invariance guarantees to disentangle the group element. We prove that IP-IRM converges to a fully disentangled representation and show its effectiveness on various benchmarks. Codes are available at https://github.com/Wangt-CN/IP-IRM.
Density-Based Clustering with Kernel Diffusion
Oct 14, 2021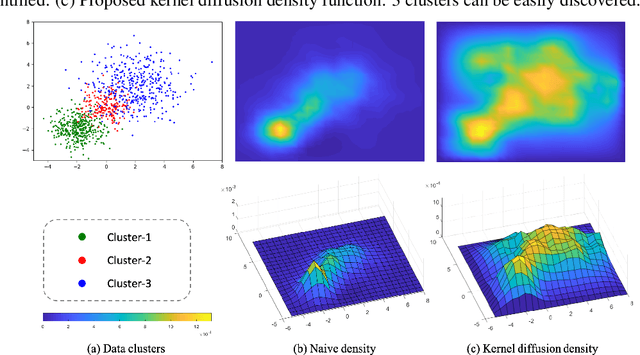
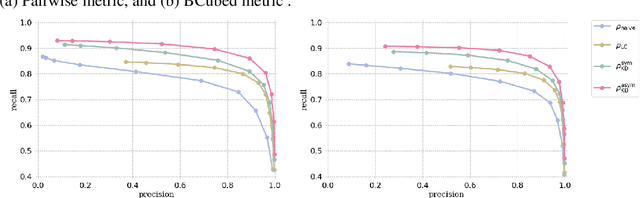
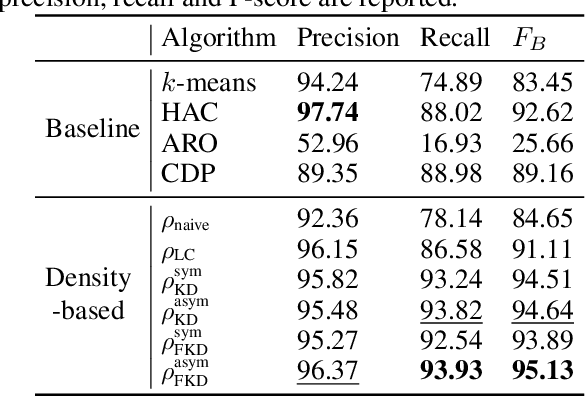
Finding a suitable density function is essential for density-based clustering algorithms such as DBSCAN and DPC. A naive density corresponding to the indicator function of a unit $d$-dimensional Euclidean ball is commonly used in these algorithms. Such density suffers from capturing local features in complex datasets. To tackle this issue, we propose a new kernel diffusion density function, which is adaptive to data of varying local distributional characteristics and smoothness. Furthermore, we develop a surrogate that can be efficiently computed in linear time and space and prove that it is asymptotically equivalent to the kernel diffusion density function. Extensive empirical experiments on benchmark and large-scale face image datasets show that the proposed approach not only achieves a significant improvement over classic density-based clustering algorithms but also outperforms the state-of-the-art face clustering methods by a large margin.
Networked Time Series Prediction with Incomplete Data
Oct 05, 2021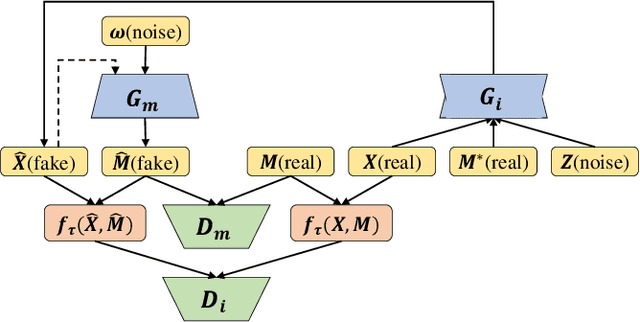
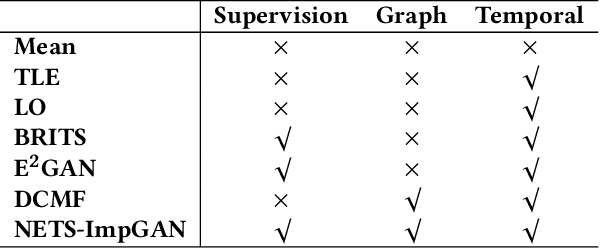
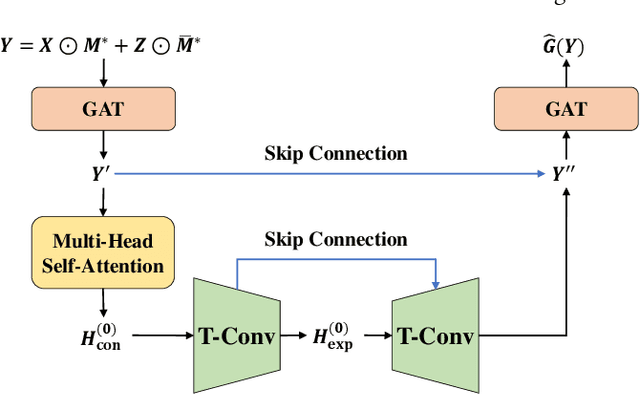
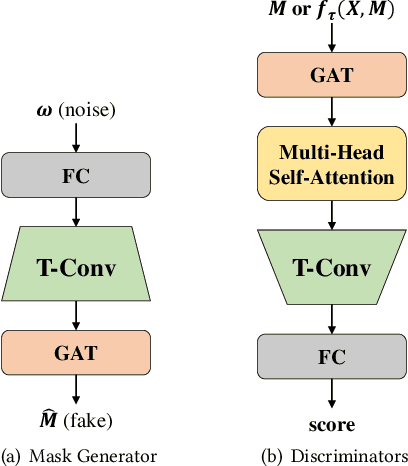
A networked time series (NETS) is a family of time series on a given graph, one for each node. It has found a wide range of applications from intelligent transportation, environment monitoring to mobile network management. An important task in such applications is to predict the future values of a NETS based on its historical values and the underlying graph. Most existing methods require complete data for training. However, in real-world scenarios, it is not uncommon to have missing data due to sensor malfunction, incomplete sensing coverage, etc. In this paper, we study the problem of NETS prediction with incomplete data. We propose NETS-ImpGAN, a novel deep learning framework that can be trained on incomplete data with missing values in both history and future. Furthermore, we propose novel Graph Temporal Attention Networks by incorporating the attention mechanism to capture both inter-time series correlations and temporal correlations. We conduct extensive experiments on three real-world datasets under different missing patterns and missing rates. The experimental results show that NETS-ImpGAN outperforms existing methods except when data exhibit very low variance, in which case NETS-ImpGAN still achieves competitive performance.
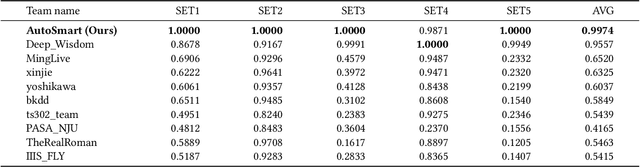
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021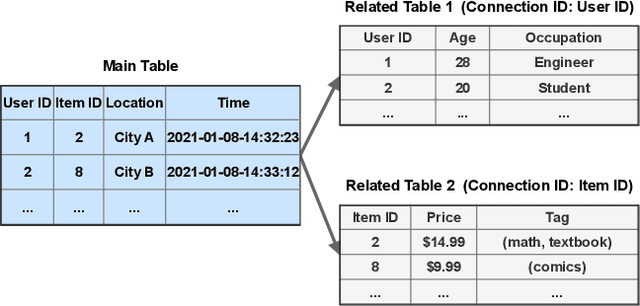

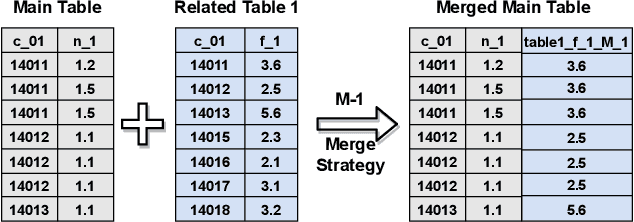
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.