 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Instance-level Image-to-Image Translation
May 05, 2019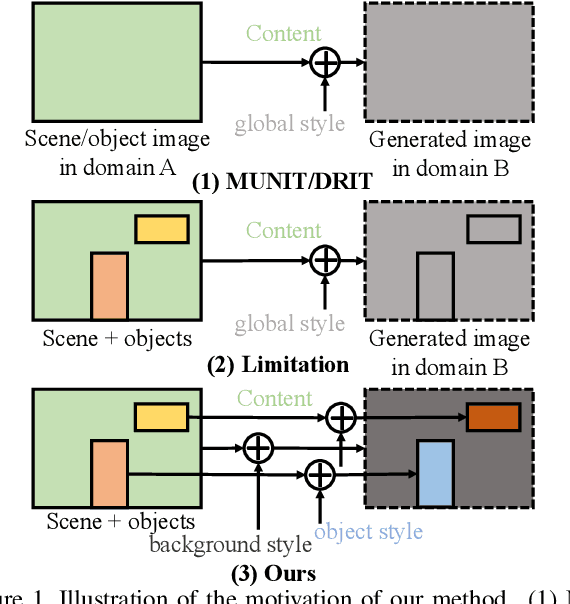
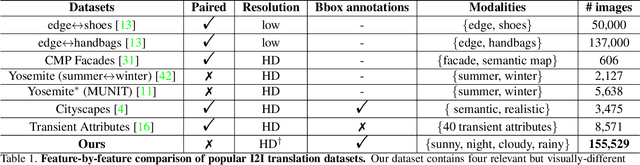
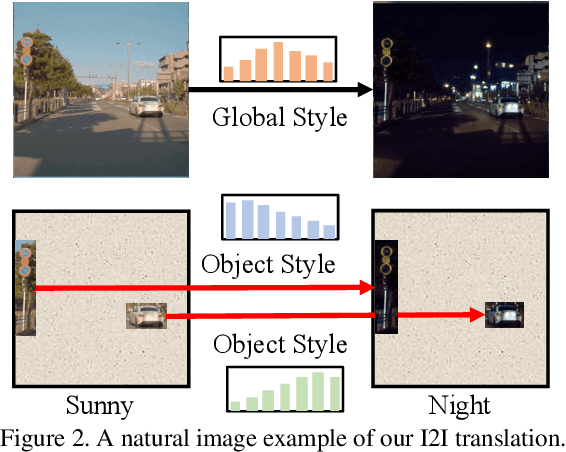
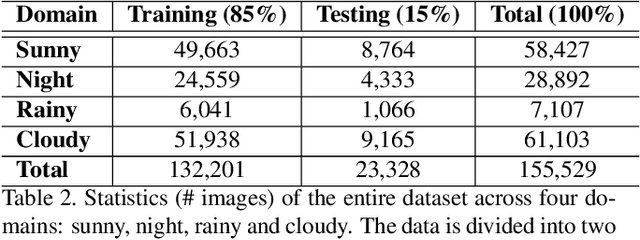
Unpaired Image-to-image Translation is a new rising and challenging vision problem that aims to learn a mapping between unaligned image pairs in diverse domains. Recent advances in this field like MUNIT and DRIT mainly focus on disentangling content and style/attribute from a given image first, then directly adopting the global style to guide the model to synthesize new domain images. However, this kind of approaches severely incurs contradiction if the target domain images are content-rich with multiple discrepant objects. In this paper, we present a simple yet effective instance-aware image-to-image translation approach (INIT), which employs the fine-grained local (instance) and global styles to the target image spatially. The proposed INIT exhibits three import advantages: (1) the instance-level objective loss can help learn a more accurate reconstruction and incorporate diverse attributes of objects; (2) the styles used for target domain of local/global areas are from corresponding spatial regions in source domain, which intuitively is a more reasonable mapping; (3) the joint training process can benefit both fine and coarse granularity and incorporates instance information to improve the quality of global translation. We also collect a large-scale benchmark for the new instance-level translation task. We observe that our synthetic images can even benefit real-world vision tasks like generic object detection.
Switchable Whitening for Deep Representation Learning
Apr 22, 2019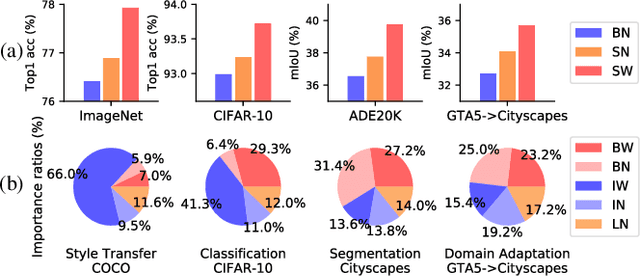

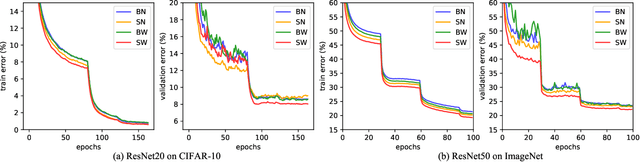
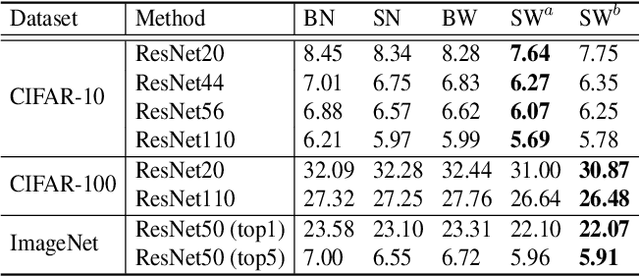
Normalization methods are essential components in convolutional neural networks (CNNs). They either standardize or whiten data using statistics estimated in predefined sets of pixels. Unlike existing works that design normalization techniques for specific tasks, we propose Switchable Whitening (SW), which provides a general form unifying different whitening methods as well as standardization methods. SW learns to switch among these operations in an end-to-end manner. It has several advantages. First, SW adaptively selects appropriate whitening or standardization statistics for different tasks (see Fig.1), making it well suited for a wide range of tasks without manual design. Second, by integrating benefits of different normalizers, SW shows consistent improvements over its counterparts in various challenging benchmarks. Third, SW serves as a useful tool for understanding the characteristics of whitening and standardization techniques. We show that SW outperforms other alternatives on image classification (CIFAR-10/100, ImageNet), semantic segmentation (ADE20K, Cityscapes), domain adaptation (GTA5, Cityscapes), and image style transfer (COCO). For example, without bells and whistles, we achieve state-of-the-art performance with 45.33% mIoU on the ADE20K dataset. Code and models will be released.
Libra R-CNN: Towards Balanced Learning for Object Detection
Apr 04, 2019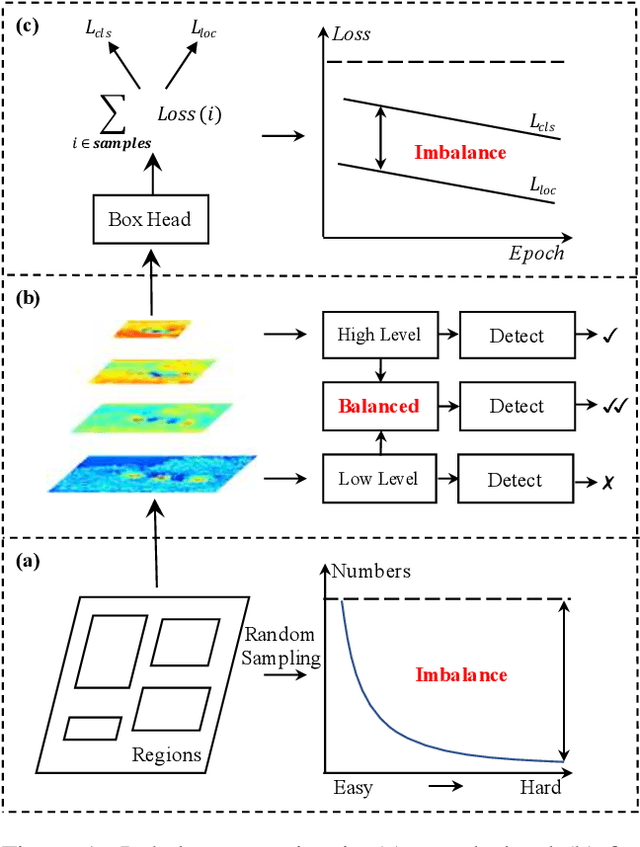
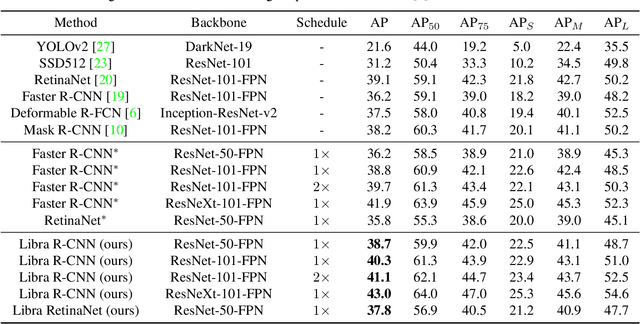
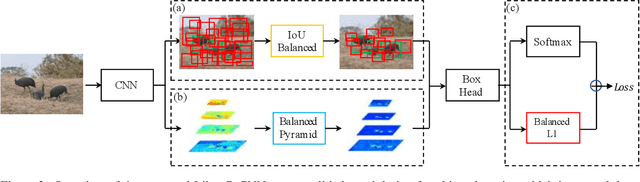

Compared with model architectures, the training process, which is also crucial to the success of detectors, has received relatively less attention in object detection. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple but effective framework towards balanced learning for object detection. It integrates three novel components: IoU-balanced sampling, balanced feature pyramid, and balanced L1 loss, respectively for reducing the imbalance at sample, feature, and objective level. Benefitted from the overall balanced design, Libra R-CNN significantly improves the detection performance. Without bells and whistles, it achieves 2.5 points and 2.0 points higher Average Precision (AP) than FPN Faster R-CNN and RetinaNet respectively on MSCOCO.
R$^2$-CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images
Mar 30, 2019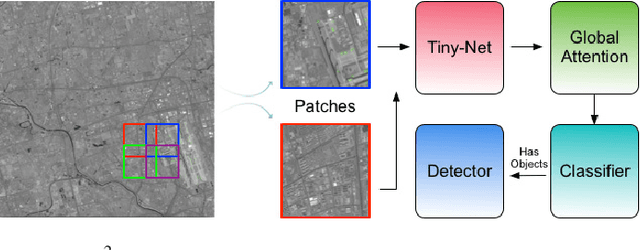
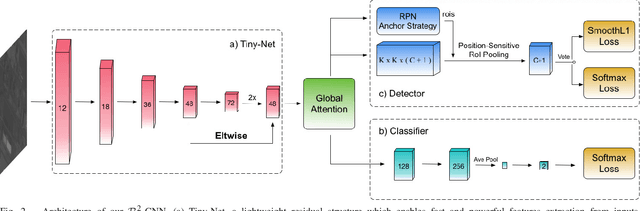
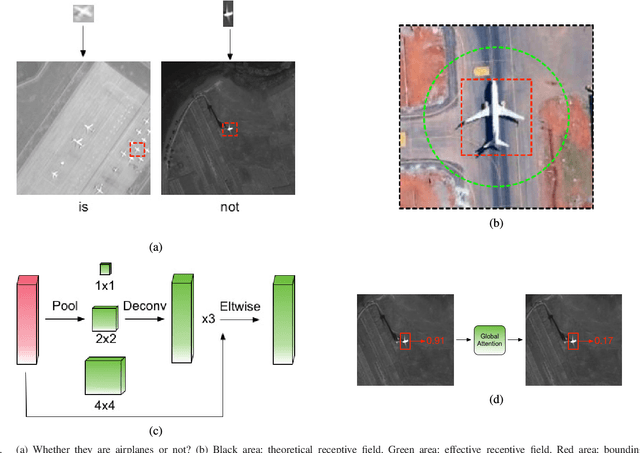
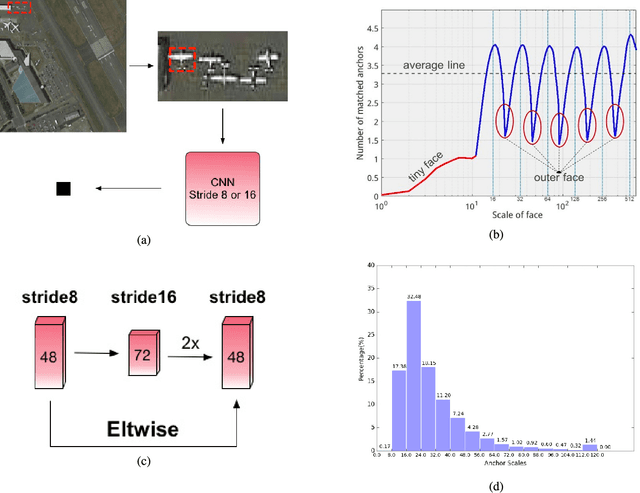
Recently, the convolutional neural network has brought impressive improvements for object detection. However, detecting tiny objects in large-scale remote sensing images still remains challenging. First, the extreme large input size makes the existing object detection solutions too slow for practical use. Second, the massive and complex backgrounds cause serious false alarms. Moreover, the ultratiny objects increase the difficulty of accurate detection. To tackle these problems, we propose a unified and self-reinforced network called remote sensing region-based convolutional neural network ($\mathcal{R}^2$-CNN), composing of backbone Tiny-Net, intermediate global attention block, and final classifier and detector. Tiny-Net is a lightweight residual structure, which enables fast and powerful features extraction from inputs. Global attention block is built upon Tiny-Net to inhibit false positives. Classifier is then used to predict the existence of targets in each patch, and detector is followed to locate them accurately if available. The classifier and detector are mutually reinforced with end-to-end training, which further speed up the process and avoid false alarms. Effectiveness of $\mathcal{R}^2$-CNN is validated on hundreds of GF-1 images and GF-2 images that are 18 000 $\times$ 18 192 pixels, 2.0-m resolution, and 27 620 $\times$ 29 200 pixels, 0.8-m resolution, respectively. Specifically, we can process a GF-1 image in 29.4 s on Titian X just with single thread. According to our knowledge, no previous solution can detect the tiny object on such huge remote sensing images gracefully. We believe that it is a significant step toward practical real-time remote sensing systems.
Hybrid Task Cascade for Instance Segmentation
Jan 22, 2019
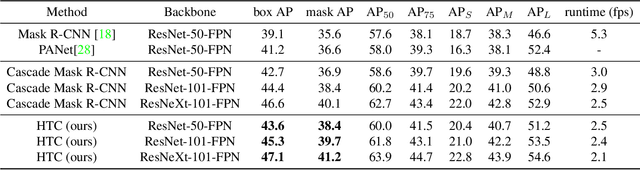
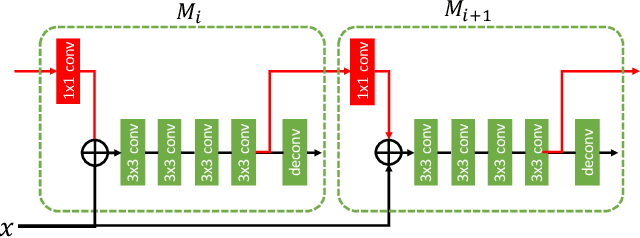

Cascade is a classic yet powerful architecture that has boosted performance on various tasks. However, how to introduce cascade to instance segmentation remains an open question. A simple combination of Cascade R-CNN and Mask R-CNN only brings limited gain. In exploring a more effective approach, we find that the key to a successful instance segmentation cascade is to fully leverage the reciprocal relationship between detection and segmentation. In this work, we propose a new framework, Hybrid Task Cascade (HTC), which differs in two important aspects: (1) instead of performing cascaded refinement on these two tasks separately, it interweaves them for a joint multi-stage processing; (2) it adopts a fully convolutional branch to provide spatial context, which can help distinguishing hard foreground from cluttered background. Overall, this framework can learn more discriminative features progressively while integrating complementary features together in each stage. Without bells and whistles, a single HTC obtains 38.4% and 1.5% improvement over a strong Cascade Mask R-CNN baseline on MSCOCO dataset. More importantly, our overall system achieves 48.6 mask AP on the test-challenge dataset and 49.0 mask AP on test-dev, which are the state-of-the-art performance.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
Jan 11, 2019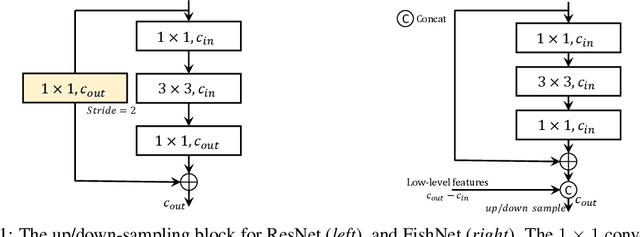
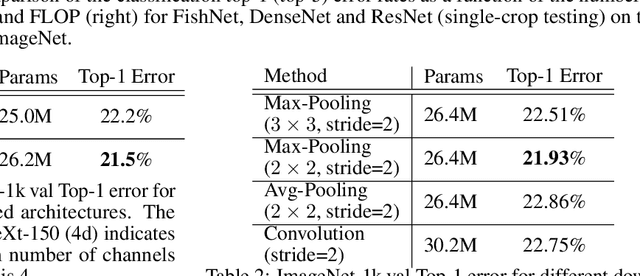
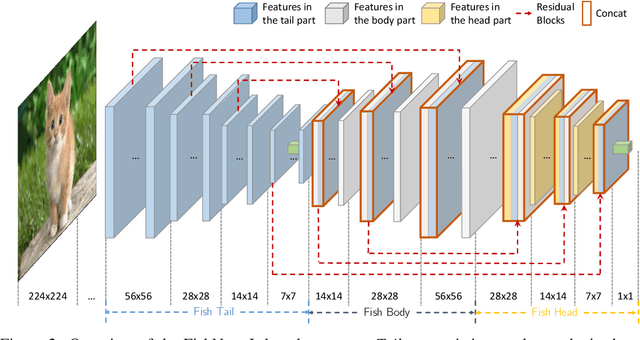
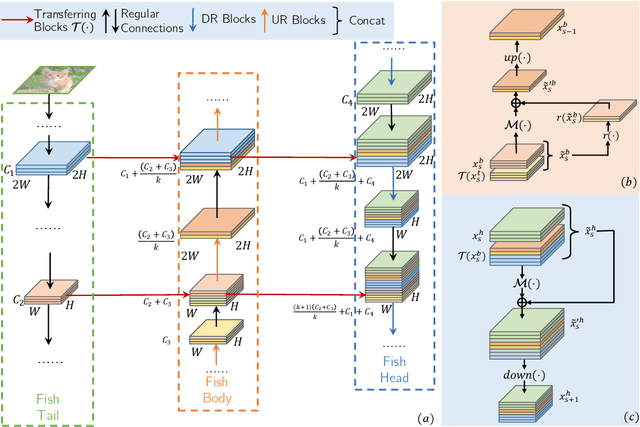
The basic principles in designing convolutional neural network (CNN) structures for predicting objects on different levels, e.g., image-level, region-level, and pixel-level are diverging. Generally, network structures designed specifically for image classification are directly used as default backbone structure for other tasks including detection and segmentation, but there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixel-level or region-level predicting tasks, which may require very deep features with high resolution. Towards this goal, we design a fish-like network, called FishNet. In FishNet, the information of all resolutions is preserved and refined for the final task. Besides, we observe that existing works still cannot \emph{directly} propagate the gradient information from deep layers to shallow layers. Our design can better handle this problem. Extensive experiments have been conducted to demonstrate the remarkable performance of the FishNet. In particular, on ImageNet-1k, the accuracy of FishNet is able to surpass the performance of DenseNet and ResNet with fewer parameters. FishNet was applied as one of the modules in the winning entry of the COCO Detection 2018 challenge. The code is available at https://github.com/kevin-ssy/FishNet.
Sequential Context Encoding for Duplicate Removal
Oct 20, 2018
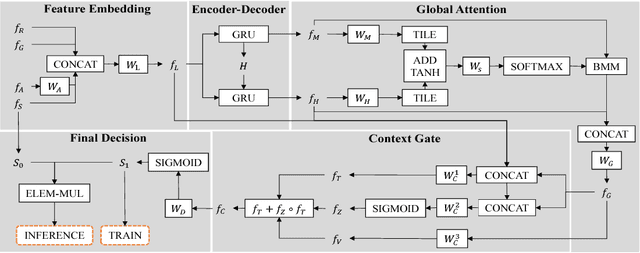

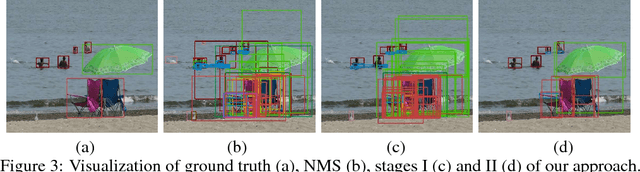
Duplicate removal is a critical step to accomplish a reasonable amount of predictions in prevalent proposal-based object detection frameworks. Albeit simple and effective, most previous algorithms utilize a greedy process without making sufficient use of properties of input data. In this work, we design a new two-stage framework to effectively select the appropriate proposal candidate for each object. The first stage suppresses most of easy negative object proposals, while the second stage selects true positives in the reduced proposal set. These two stages share the same network structure, \ie, an encoder and a decoder formed as recurrent neural networks (RNN) with global attention and context gate. The encoder scans proposal candidates in a sequential manner to capture the global context information, which is then fed to the decoder to extract optimal proposals. In our extensive experiments, the proposed method outperforms other alternatives by a large margin.
Towards Understanding Acceleration Tradeoff between Momentum and Asynchrony in Nonconvex Stochastic Optimization
Oct 01, 2018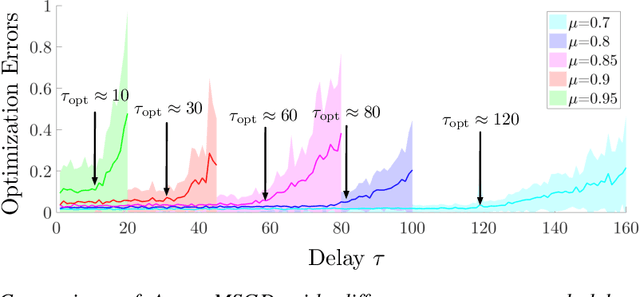
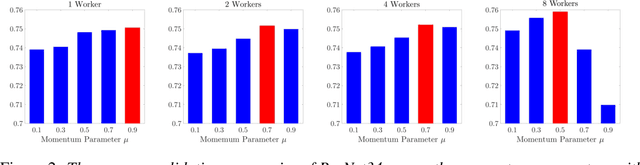
Asynchronous momentum stochastic gradient descent algorithms (Async-MSGD) is one of the most popular algorithms in distributed machine learning. However, its convergence properties for these complicated nonconvex problems is still largely unknown, because of the current technical limit. Therefore, in this paper, we propose to analyze the algorithm through a simpler but nontrivial nonconvex problem - streaming PCA, which helps us to understand Aync-MSGD better even for more general problems. Specifically, we establish the asymptotic rate of convergence of Async-MSGD for streaming PCA by diffusion approximation. Our results indicate a fundamental tradeoff between asynchrony and momentum: To ensure convergence and acceleration through asynchrony, we have to reduce the momentum (compared with Sync-MSGD). To the best of our knowledge, this is the first theoretical attempt on understanding Async-MSGD for distributed nonconvex stochastic optimization. Numerical experiments on both streaming PCA and training deep neural networks are provided to support our findings for Async-MSGD.
Path Aggregation Network for Instance Segmentation
Sep 18, 2018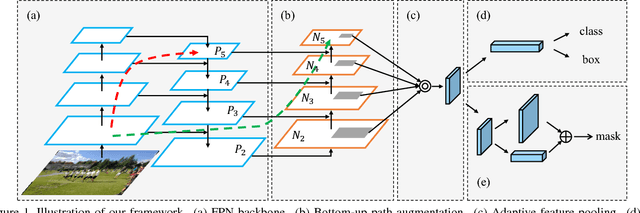

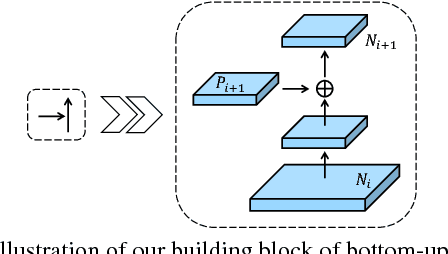
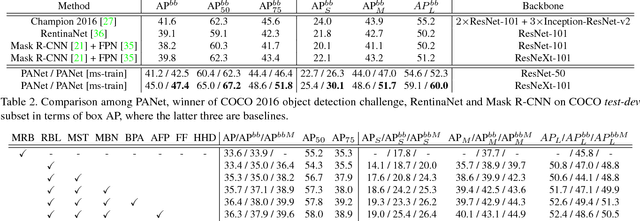
The way that information propagates in neural networks is of great importance. In this paper, we propose Path Aggregation Network (PANet) aiming at boosting information flow in proposal-based instance segmentation framework. Specifically, we enhance the entire feature hierarchy with accurate localization signals in lower layers by bottom-up path augmentation, which shortens the information path between lower layers and topmost feature. We present adaptive feature pooling, which links feature grid and all feature levels to make useful information in each feature level propagate directly to following proposal subnetworks. A complementary branch capturing different views for each proposal is created to further improve mask prediction. These improvements are simple to implement, with subtle extra computational overhead. Our PANet reaches the 1st place in the COCO 2017 Challenge Instance Segmentation task and the 2nd place in Object Detection task without large-batch training. It is also state-of-the-art on MVD and Cityscapes. Code is available at https://github.com/ShuLiu1993/PANet
Penalizing Top Performers: Conservative Loss for Semantic Segmentation Adaptation
Sep 04, 2018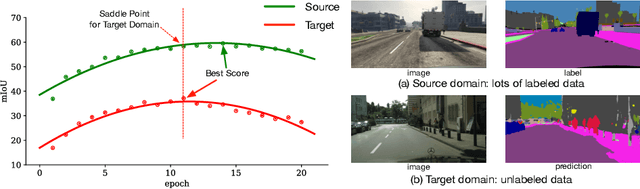
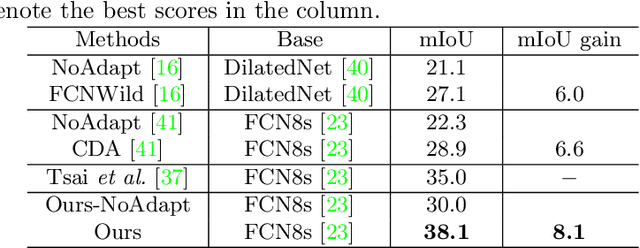
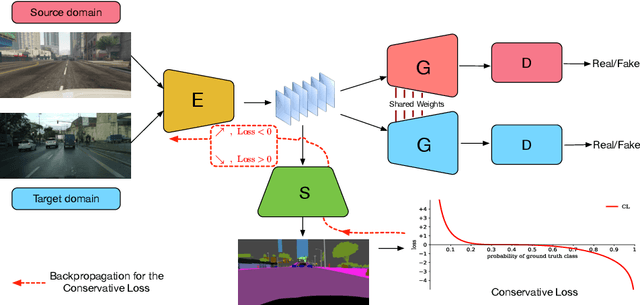
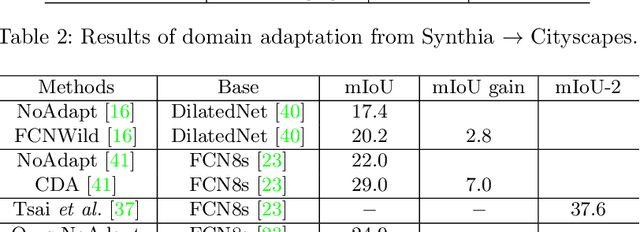
Due to the expensive and time-consuming annotations (e.g., segmentation) for real-world images, recent works in computer vision resort to synthetic data. However, the performance on the real image often drops significantly because of the domain shift between the synthetic data and the real images. In this setting, domain adaptation brings an appealing option. The effective approaches of domain adaptation shape the representations that (1) are discriminative for the main task and (2) have good generalization capability for domain shift. To this end, we propose a novel loss function, i.e., Conservative Loss, which penalizes the extreme good and bad cases while encouraging the moderate examples. More specifically, it enables the network to learn features that are discriminative by gradient descent and are invariant to the change of domains via gradient ascend method. Extensive experiments on synthetic to real segmentation adaptation show our proposed method achieves state of the art results. Ablation studies give more insights into properties of the Conservative Loss. Exploratory experiments and discussion demonstrate that our Conservative Loss has good flexibility rather than restricting an exact form.