 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDA3D: Semi-supervised Domain Adaptation for 3D Object Detection from Point Cloud
Dec 06, 2022



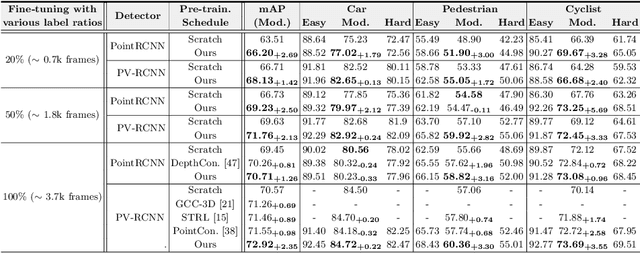
LiDAR-based 3D object detection is an indispensable task in advanced autonomous driving systems. Though impressive detection results have been achieved by superior 3D detectors, they suffer from significant performance degeneration when facing unseen domains, such as different LiDAR configurations, different cities, and weather conditions. The mainstream approaches tend to solve these challenges by leveraging unsupervised domain adaptation (UDA) techniques. However, these UDA solutions just yield unsatisfactory 3D detection results when there is a severe domain shift, e.g., from Waymo (64-beam) to nuScenes (32-beam). To address this, we present a novel Semi-Supervised Domain Adaptation method for 3D object detection (SSDA3D), where only a few labeled target data is available, yet can significantly improve the adaptation performance. In particular, our SSDA3D includes an Inter-domain Adaptation stage and an Intra-domain Generalization stage. In the first stage, an Inter-domain Point-CutMix module is presented to efficiently align the point cloud distribution across domains. The Point-CutMix generates mixed samples of an intermediate domain, thus encouraging to learn domain-invariant knowledge. Then, in the second stage, we further enhance the model for better generalization on the unlabeled target set. This is achieved by exploring Intra-domain Point-MixUp in semi-supervised learning, which essentially regularizes the pseudo label distribution. Experiments from Waymo to nuScenes show that, with only 10% labeled target data, our SSDA3D can surpass the fully-supervised oracle model with 100% target label. Our code is available at https://github.com/yinjunbo/SSDA3D.
Rethinking Clustering-Based Pseudo-Labeling for Unsupervised Meta-Learning
Sep 27, 2022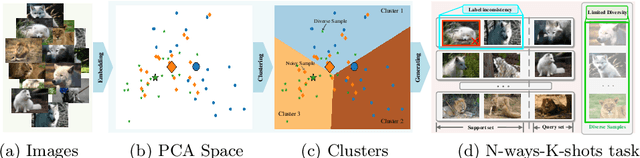
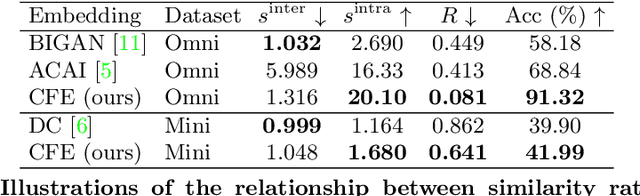

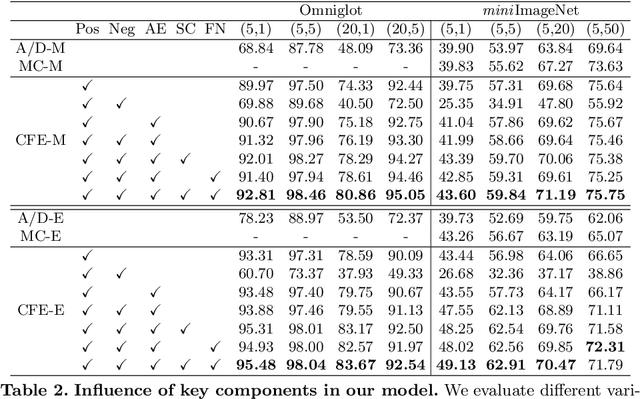
The pioneering method for unsupervised meta-learning, CACTUs, is a clustering-based approach with pseudo-labeling. This approach is model-agnostic and can be combined with supervised algorithms to learn from unlabeled data. However, it often suffers from label inconsistency or limited diversity, which leads to poor performance. In this work, we prove that the core reason for this is lack of a clustering-friendly property in the embedding space. We address this by minimizing the inter- to intra-class similarity ratio to provide clustering-friendly embedding features, and validate our approach through comprehensive experiments. Note that, despite only utilizing a simple clustering algorithm (k-means) in our embedding space to obtain the pseudo-labels, we achieve significant improvement. Moreover, we adopt a progressive evaluation mechanism to obtain more diverse samples in order to further alleviate the limited diversity problem. Finally, our approach is also model-agnostic and can easily be integrated into existing supervised methods. To demonstrate its generalization ability, we integrate it into two representative algorithms: MAML and EP. The results on three main few-shot benchmarks clearly show that the proposed method achieves significant improvement compared to state-of-the-art models. Notably, our approach also outperforms the corresponding supervised method in two tasks.
Graph Neural Network and Spatiotemporal Transformer Attention for 3D Video Object Detection from Point Clouds
Jul 26, 2022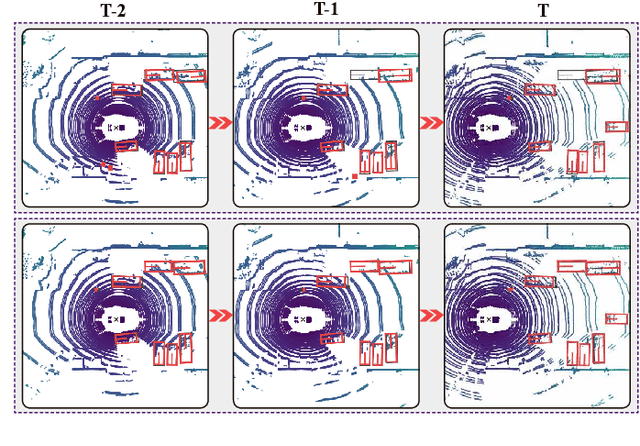
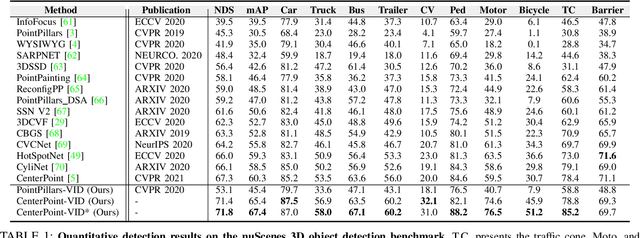
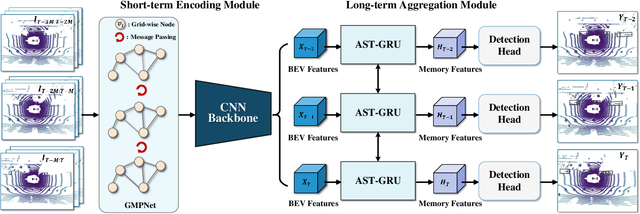

Previous works for LiDAR-based 3D object detection mainly focus on the single-frame paradigm. In this paper, we propose to detect 3D objects by exploiting temporal information in multiple frames, i.e., the point cloud videos. We empirically categorize the temporal information into short-term and long-term patterns. To encode the short-term data, we present a Grid Message Passing Network (GMPNet), which considers each grid (i.e., the grouped points) as a node and constructs a k-NN graph with the neighbor grids. To update features for a grid, GMPNet iteratively collects information from its neighbors, thus mining the motion cues in grids from nearby frames. To further aggregate the long-term frames, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU), which contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module. STA and TTA enhance the vanilla GRU to focus on small objects and better align the moving objects. Our overall framework supports both online and offline video object detection in point clouds. We implement our algorithm based on prevalent anchor-based and anchor-free detectors. The evaluation results on the challenging nuScenes benchmark show the superior performance of our method, achieving the 1st on the leaderboard without any bells and whistles, by the time the paper is submitted.
Semi-supervised 3D Object Detection with Proficient Teachers
Jul 26, 2022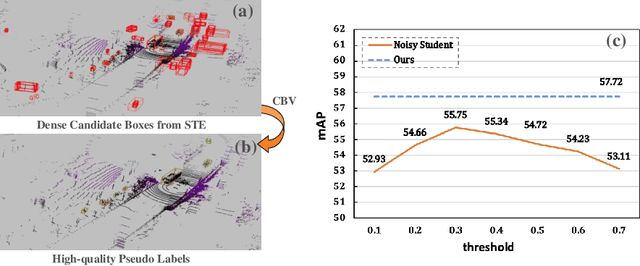

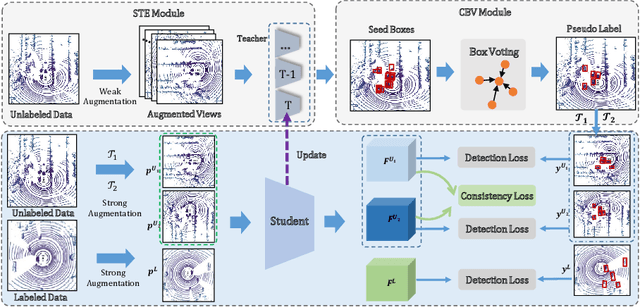

Dominated point cloud-based 3D object detectors in autonomous driving scenarios rely heavily on the huge amount of accurately labeled samples, however, 3D annotation in the point cloud is extremely tedious, expensive and time-consuming. To reduce the dependence on large supervision, semi-supervised learning (SSL) based approaches have been proposed. The Pseudo-Labeling methodology is commonly used for SSL frameworks, however, the low-quality predictions from the teacher model have seriously limited its performance. In this work, we propose a new Pseudo-Labeling framework for semi-supervised 3D object detection, by enhancing the teacher model to a proficient one with several necessary designs. First, to improve the recall of pseudo labels, a Spatialtemporal Ensemble (STE) module is proposed to generate sufficient seed boxes. Second, to improve the precision of recalled boxes, a Clusteringbased Box Voting (CBV) module is designed to get aggregated votes from the clustered seed boxes. This also eliminates the necessity of sophisticated thresholds to select pseudo labels. Furthermore, to reduce the negative influence of wrongly pseudo-labeled samples during the training, a soft supervision signal is proposed by considering Box-wise Contrastive Learning (BCL). The effectiveness of our model is verified on both ONCE and Waymo datasets. For example, on ONCE, our approach significantly improves the baseline by 9.51 mAP. Moreover, with half annotations, our model outperforms the oracle model with full annotations on Waymo.
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
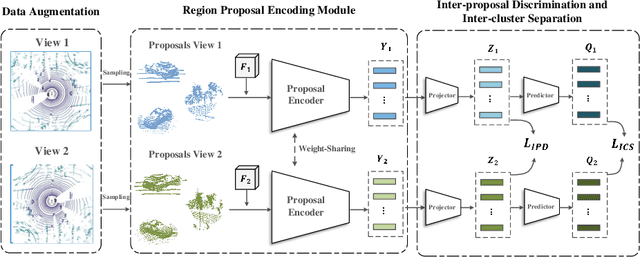
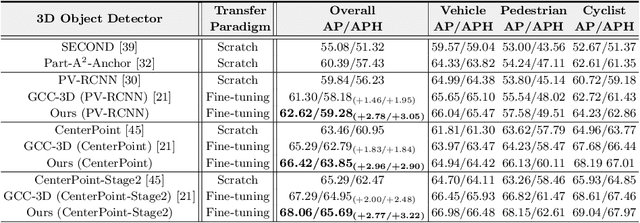
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).
Counterfactual Cycle-Consistent Learning for Instruction Following and Generation in Vision-Language Navigation
Mar 30, 2022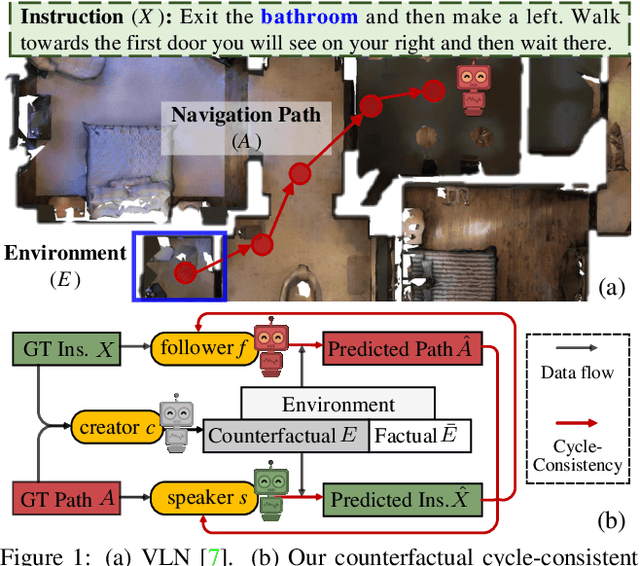
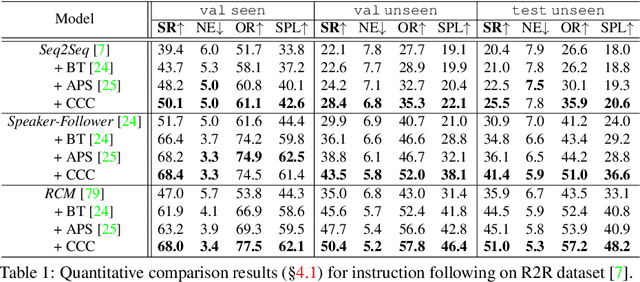

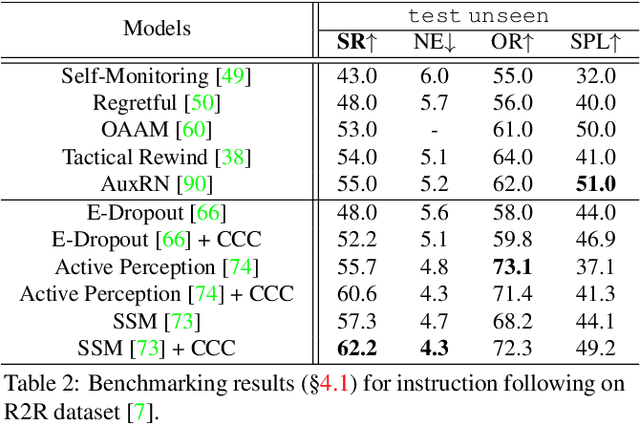
Since the rise of vision-language navigation (VLN), great progress has been made in instruction following -- building a follower to navigate environments under the guidance of instructions. However, far less attention has been paid to the inverse task: instruction generation -- learning a speaker~to generate grounded descriptions for navigation routes. Existing VLN methods train a speaker independently and often treat it as a data augmentation tool to strengthen the follower while ignoring rich cross-task relations. Here we describe an approach that learns the two tasks simultaneously and exploits their intrinsic correlations to boost the training of each: the follower judges whether the speaker-created instruction explains the original navigation route correctly, and vice versa. Without the need of aligned instruction-path pairs, such cycle-consistent learning scheme is complementary to task-specific training targets defined on labeled data, and can also be applied over unlabeled paths (sampled without paired instructions). Another agent, called~creator is added to generate counterfactual environments. It greatly changes current scenes yet leaves novel items -- which are vital for the execution of original instructions -- unchanged. Thus more informative training scenes are synthesized and the three agents compose a powerful VLN learning system. Extensive experiments on a standard benchmark show that our approach improves the performance of various follower models and produces accurate navigation instructions.
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022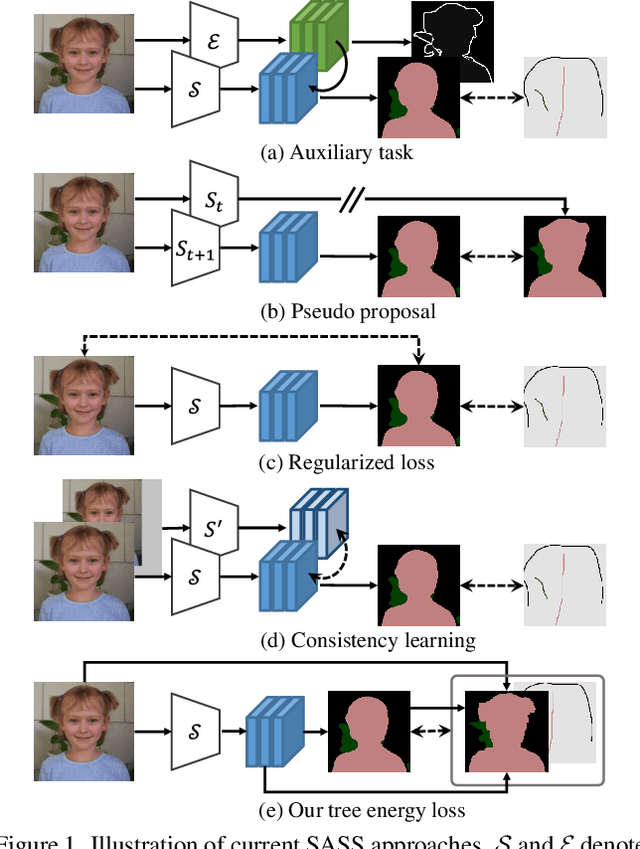
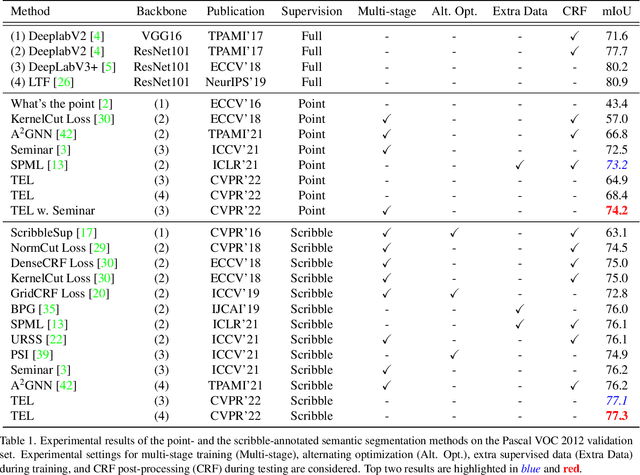

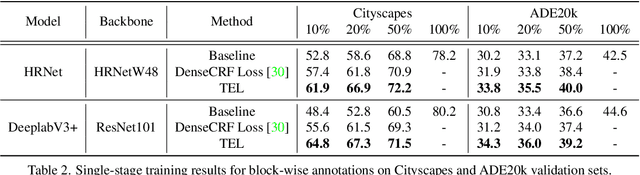
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022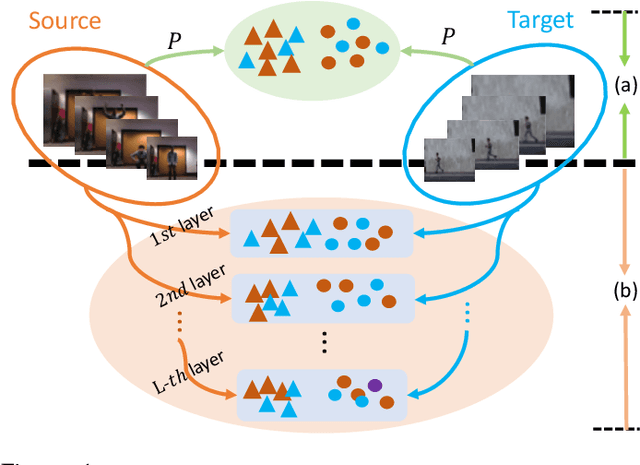

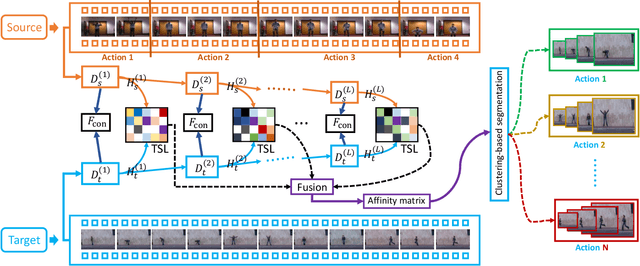
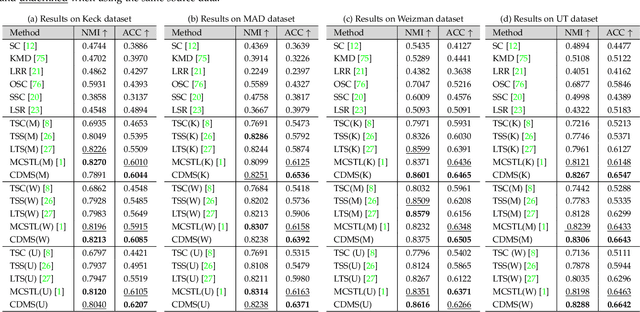
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.
Bilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Dec 14, 2021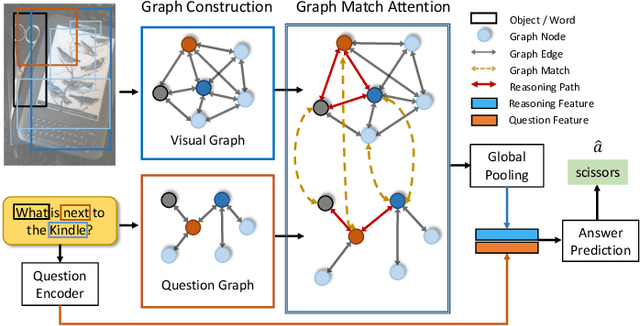
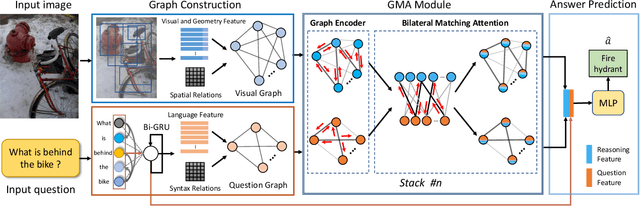
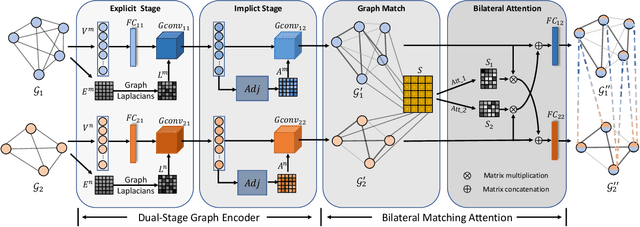
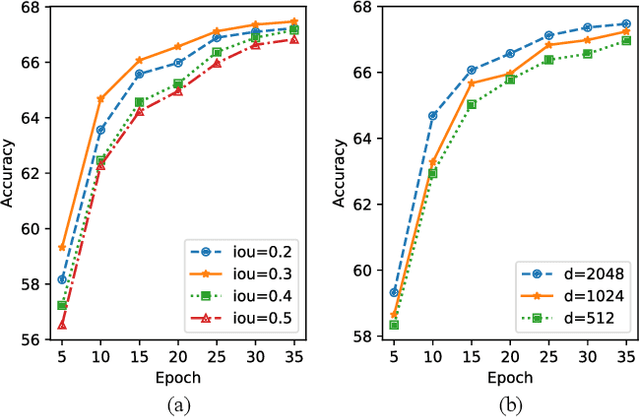
Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.
Full-Duplex Strategy for Video Object Segmentation
Sep 03, 2021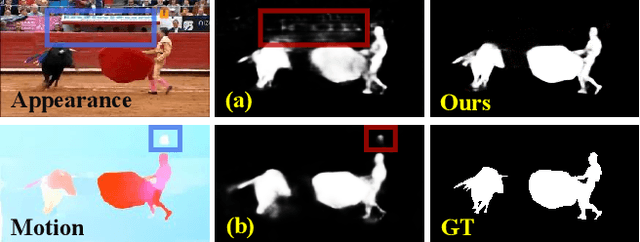

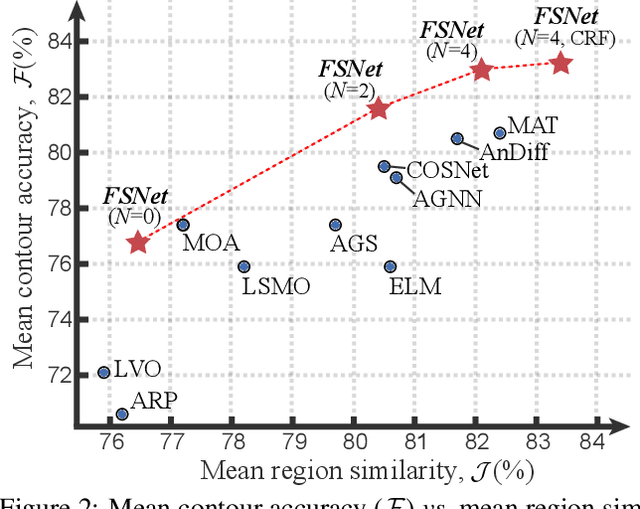
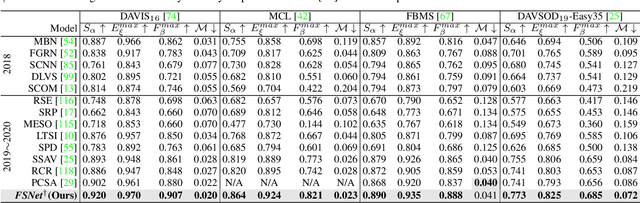
Previous video object segmentation approaches mainly focus on using simplex solutions between appearance and motion, limiting feature collaboration efficiency among and across these two cues. In this work, we study a novel and efficient full-duplex strategy network (FSNet) to address this issue, by considering a better mutual restraint scheme between motion and appearance in exploiting the cross-modal features from the fusion and decoding stage. Specifically, we introduce the relational cross-attention module (RCAM) to achieve bidirectional message propagation across embedding sub-spaces. To improve the model's robustness and update the inconsistent features from the spatial-temporal embeddings, we adopt the bidirectional purification module (BPM) after the RCAM. Extensive experiments on five popular benchmarks show that our FSNet is robust to various challenging scenarios (e.g., motion blur, occlusion) and achieves favourable performance against existing cutting-edges both in the video object segmentation and video salient object detection tasks. The project is publicly available at: https://dpfan.net/FSNet.