 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQDet: Instance-wise Quality Distribution Sampling for Object Detection
Apr 14, 2021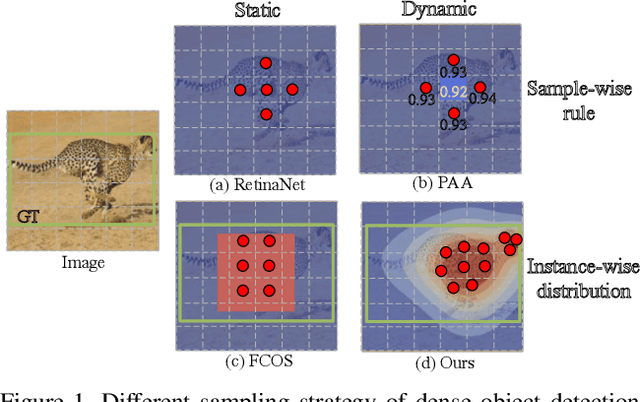
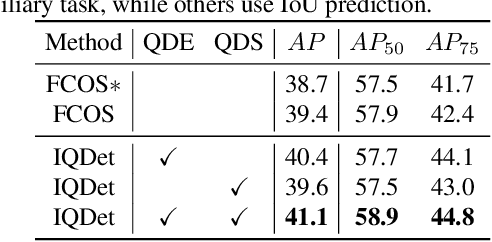
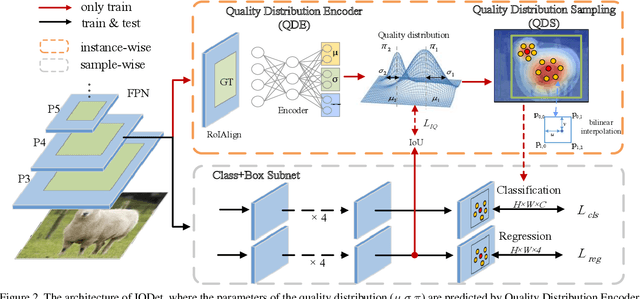
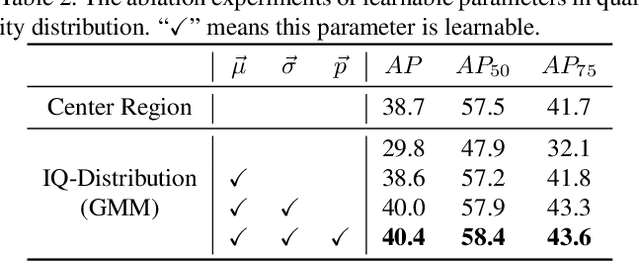
We propose a dense object detector with an instance-wise sampling strategy, named IQDet. Instead of using human prior sampling strategies, we first extract the regional feature of each ground-truth to estimate the instance-wise quality distribution. According to a mixture model in spatial dimensions, the distribution is more noise-robust and adapted to the semantic pattern of each instance. Based on the distribution, we propose a quality sampling strategy, which automatically selects training samples in a probabilistic manner and trains with more high-quality samples. Extensive experiments on MS COCO show that our method steadily improves baseline by nearly 2.4 AP without bells and whistles. Moreover, our best model achieves 51.6 AP, outperforming all existing state-of-the-art one-stage detectors and it is completely cost-free in inference time.
Learning to Jointly Deblur, Demosaick and Denoise Raw Images
Apr 13, 2021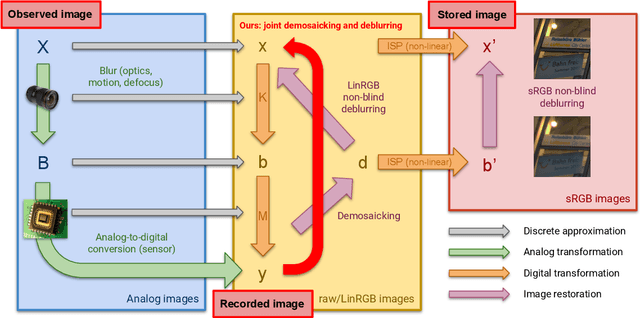
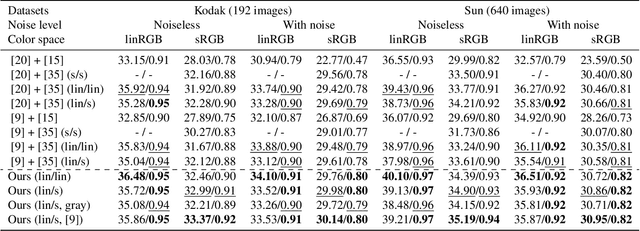
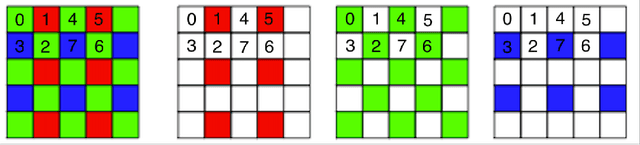
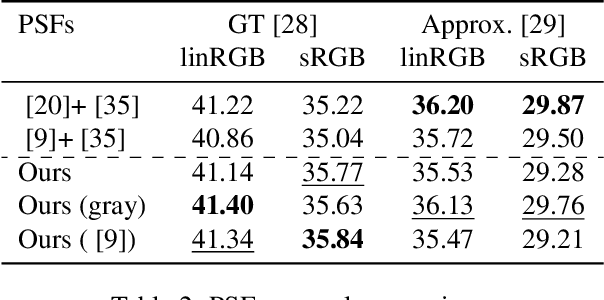
We address the problem of non-blind deblurring and demosaicking of noisy raw images. We adapt an existing learning-based approach to RGB image deblurring to handle raw images by introducing a new interpretable module that jointly demosaicks and deblurs them. We train this model on RGB images converted into raw ones following a realistic invertible camera pipeline. We demonstrate the effectiveness of this model over two-stage approaches stacking demosaicking and deblurring modules on quantitive benchmarks. We also apply our approach to remove a camera's inherent blur (its color-dependent point-spread function) from real images, in essence deblurring sharp images.
Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
Mar 30, 2021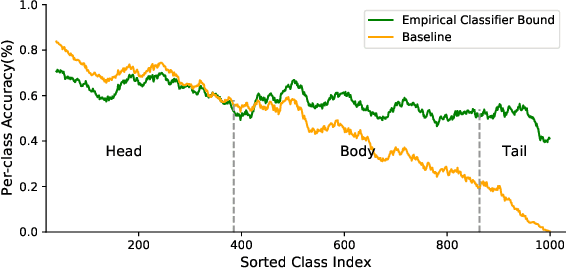
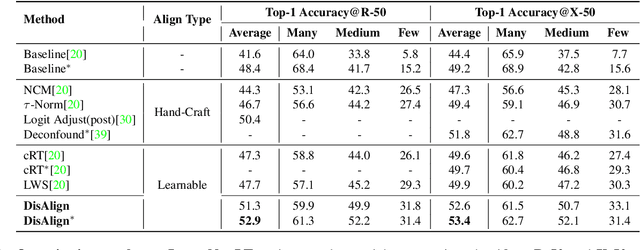
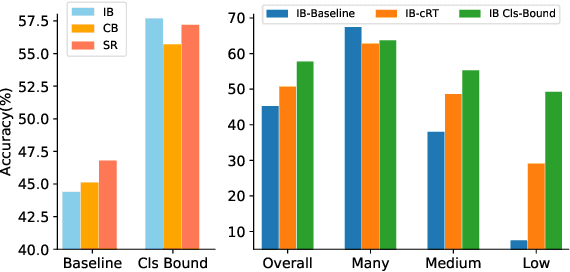
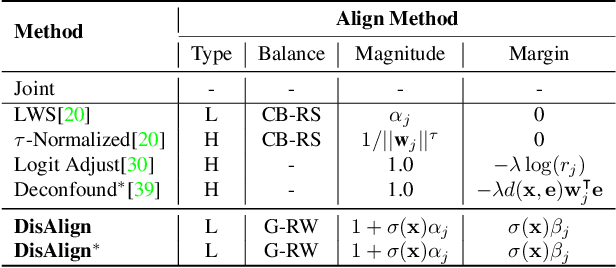
Despite the recent success of deep neural networks, it remains challenging to effectively model the long-tail class distribution in visual recognition tasks. To address this problem, we first investigate the performance bottleneck of the two-stage learning framework via ablative study. Motivated by our discovery, we propose a unified distribution alignment strategy for long-tail visual recognition. Specifically, we develop an adaptive calibration function that enables us to adjust the classification scores for each data point. We then introduce a generalized re-weight method in the two-stage learning to balance the class prior, which provides a flexible and unified solution to diverse scenarios in visual recognition tasks. We validate our method by extensive experiments on four tasks, including image classification, semantic segmentation, object detection, and instance segmentation. Our approach achieves the state-of-the-art results across all four recognition tasks with a simple and unified framework. The code and models will be made publicly available at: https://github.com/Megvii-BaseDetection/DisAlign
OTA: Optimal Transport Assignment for Object Detection
Mar 26, 2021
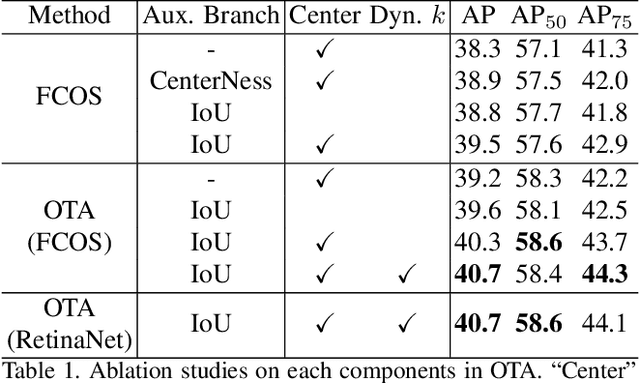
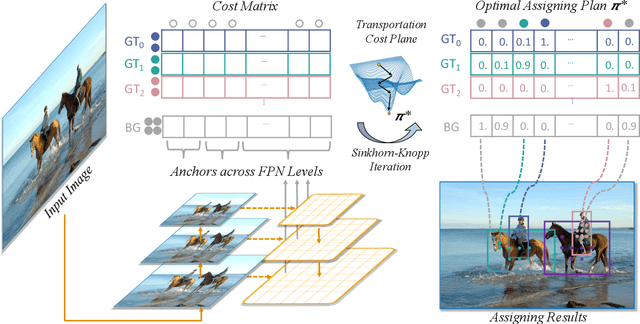
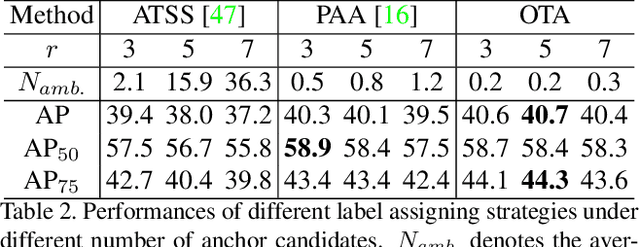
Recent advances in label assignment in object detection mainly seek to independently define positive/negative training samples for each ground-truth (gt) object. In this paper, we innovatively revisit the label assignment from a global perspective and propose to formulate the assigning procedure as an Optimal Transport (OT) problem -- a well-studied topic in Optimization Theory. Concretely, we define the unit transportation cost between each demander (anchor) and supplier (gt) pair as the weighted summation of their classification and regression losses. After formulation, finding the best assignment solution is converted to solve the optimal transport plan at minimal transportation costs, which can be solved via Sinkhorn-Knopp Iteration. On COCO, a single FCOS-ResNet-50 detector equipped with Optimal Transport Assignment (OTA) can reach 40.7% mAP under 1X scheduler, outperforming all other existing assigning methods. Extensive experiments conducted on COCO and CrowdHuman further validate the effectiveness of our proposed OTA, especially its superiority in crowd scenarios. The code is available at https://github.com/Megvii-BaseDetection/OTA.
Training Networks in Null Space of Feature Covariance for Continual Learning
Mar 17, 2021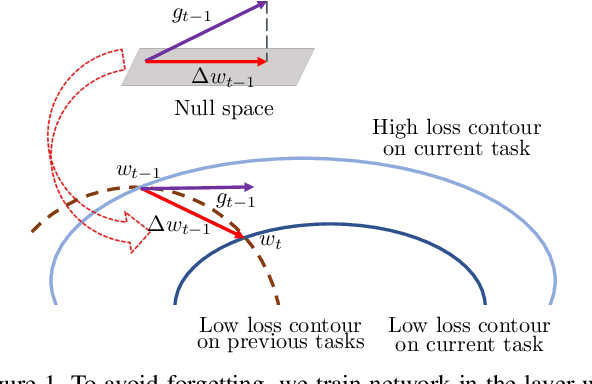
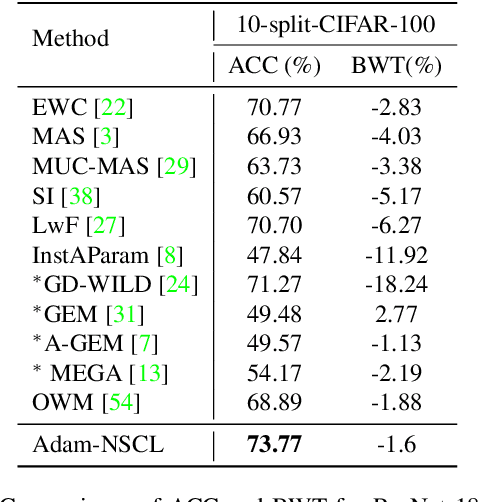
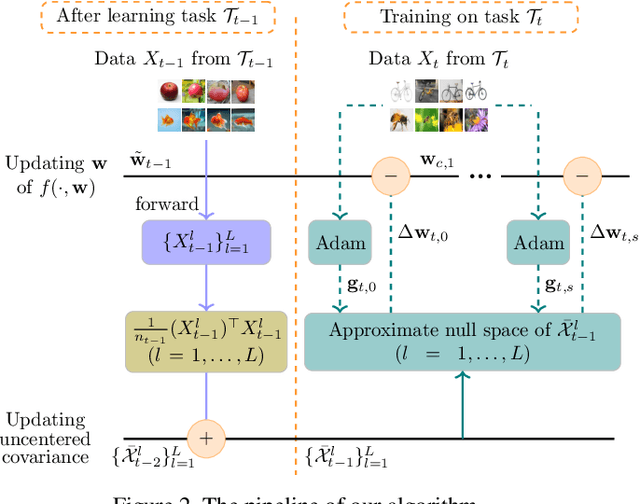
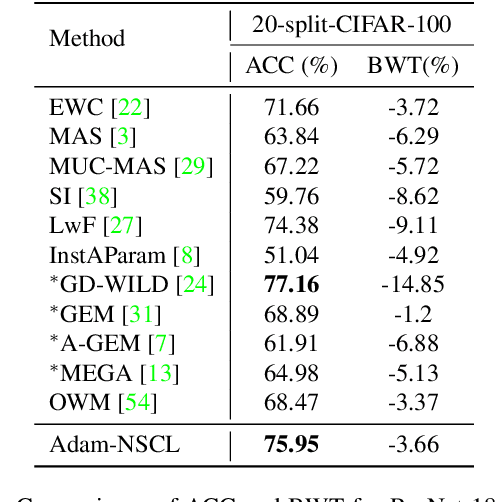
In the setting of continual learning, a network is trained on a sequence of tasks, and suffers from catastrophic forgetting. To balance plasticity and stability of network in continual learning, in this paper, we propose a novel network training algorithm called Adam-NSCL, which sequentially optimizes network parameters in the null space of previous tasks. We first propose two mathematical conditions respectively for achieving network stability and plasticity in continual learning. Based on them, the network training for sequential tasks can be simply achieved by projecting the candidate parameter update into the approximate null space of all previous tasks in the network training process, where the candidate parameter update can be generated by Adam. The approximate null space can be derived by applying singular value decomposition to the uncentered covariance matrix of all input features of previous tasks for each linear layer. For efficiency, the uncentered covariance matrix can be incrementally computed after learning each task. We also empirically verify the rationality of the approximate null space at each linear layer. We apply our approach to training networks for continual learning on benchmark datasets of CIFAR-100 and TinyImageNet, and the results suggest that the proposed approach outperforms or matches the state-ot-the-art continual learning approaches.
You Only Look One-level Feature
Mar 17, 2021
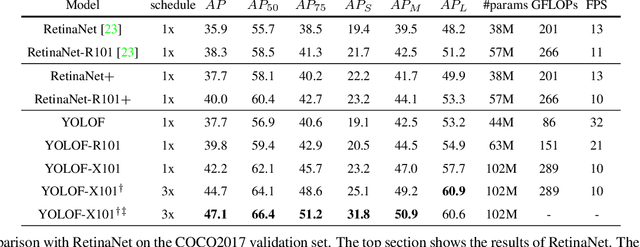

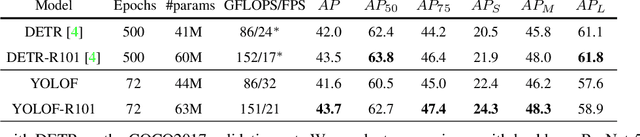
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being $2.5\times$ faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with $7\times$ less training epochs. With an image size of $608\times608$, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is $13\%$ faster than YOLOv4. Code is available at \url{https://github.com/megvii-model/YOLOF}.
End-to-End Human Object Interaction Detection with HOI Transformer
Mar 08, 2021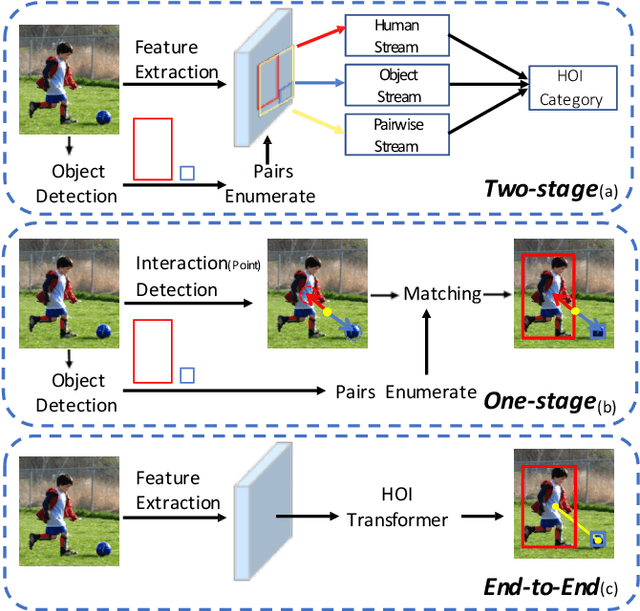
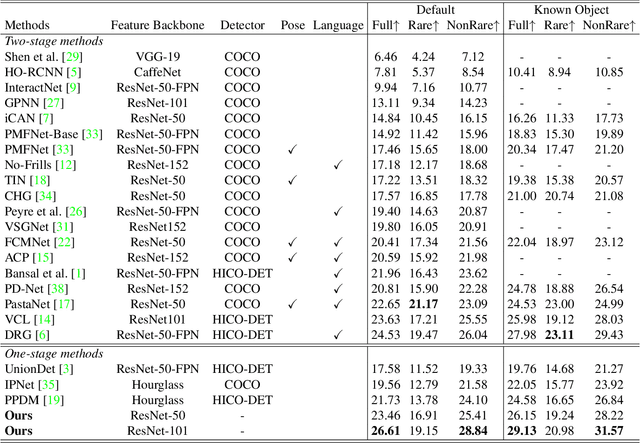
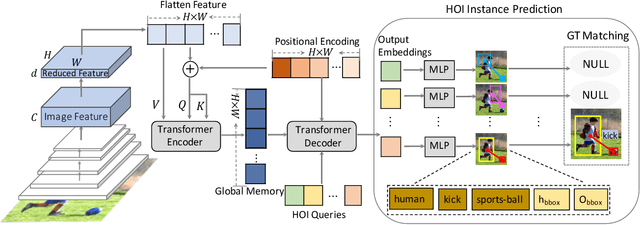

We propose HOI Transformer to tackle human object interaction (HOI) detection in an end-to-end manner. Current approaches either decouple HOI task into separated stages of object detection and interaction classification or introduce surrogate interaction problem. In contrast, our method, named HOI Transformer, streamlines the HOI pipeline by eliminating the need for many hand-designed components. HOI Transformer reasons about the relations of objects and humans from global image context and directly predicts HOI instances in parallel. A quintuple matching loss is introduced to force HOI predictions in a unified way. Our method is conceptually much simpler and demonstrates improved accuracy. Without bells and whistles, HOI Transformer achieves $26.61\% $ $ AP $ on HICO-DET and $52.9\%$ $AP_{role}$ on V-COCO, surpassing previous methods with the advantage of being much simpler. We hope our approach will serve as a simple and effective alternative for HOI tasks. Code is available at https://github.com/bbepoch/HoiTransformer .
Improving Text-to-SQL with Schema Dependency Learning
Mar 07, 2021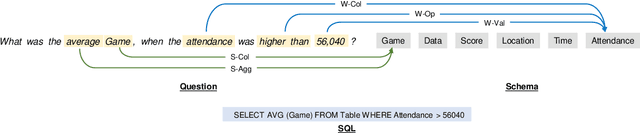
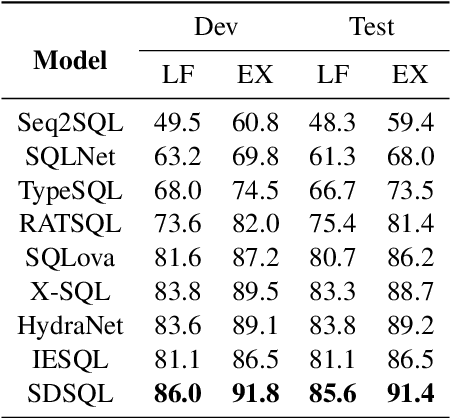
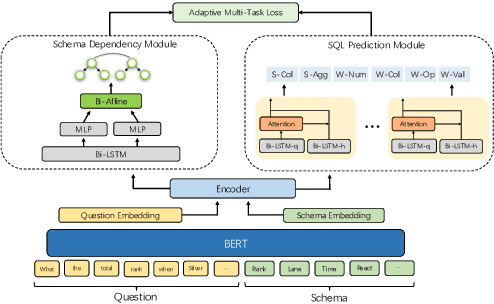
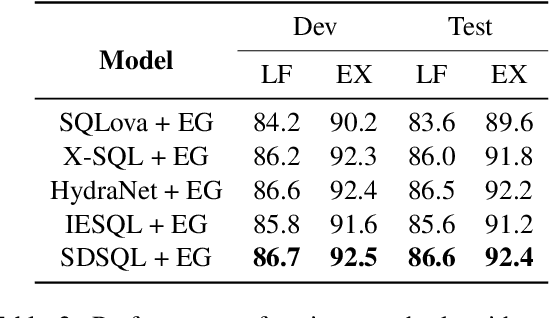
Text-to-SQL aims to map natural language questions to SQL queries. The sketch-based method combined with execution-guided (EG) decoding strategy has shown a strong performance on the WikiSQL benchmark. However, execution-guided decoding relies on database execution, which significantly slows down the inference process and is hence unsatisfactory for many real-world applications. In this paper, we present the Schema Dependency guided multi-task Text-to-SQL model (SDSQL) to guide the network to effectively capture the interactions between questions and schemas. The proposed model outperforms all existing methods in both the settings with or without EG. We show the schema dependency learning partially cover the benefit from EG and alleviates the need for it. SDSQL without EG significantly reduces time consumption during inference, sacrificing only a small amount of performance and provides more flexibility for downstream applications.
FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation
Mar 03, 2021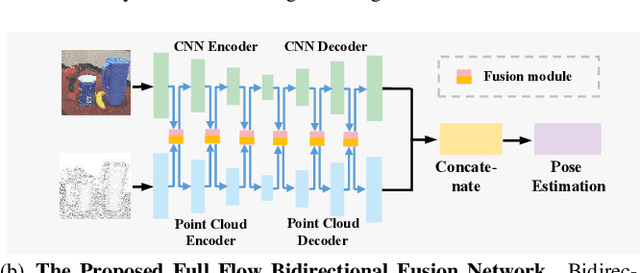
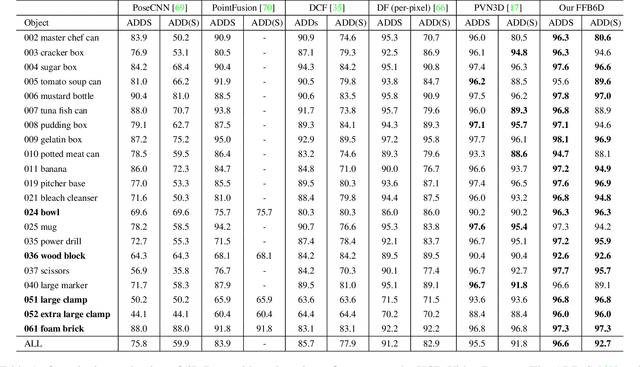
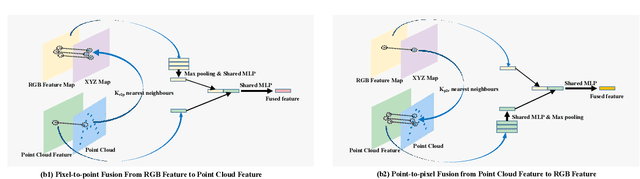

In this work, we present FFB6D, a Full Flow Bidirectional fusion network designed for 6D pose estimation from a single RGBD image. Our key insight is that appearance information in the RGB image and geometry information from the depth image are two complementary data sources, and it still remains unknown how to fully leverage them. Towards this end, we propose FFB6D, which learns to combine appearance and geometry information for representation learning as well as output representation selection. Specifically, at the representation learning stage, we build bidirectional fusion modules in the full flow of the two networks, where fusion is applied to each encoding and decoding layer. In this way, the two networks can leverage local and global complementary information from the other one to obtain better representations. Moreover, at the output representation stage, we designed a simple but effective 3D keypoints selection algorithm considering the texture and geometry information of objects, which simplifies keypoint localization for precise pose estimation. Experimental results show that our method outperforms the state-of-the-art by large margins on several benchmarks. Code and video are available at \url{https://github.com/ethnhe/FFB6D.git}.
Using Long Short-Term Memory and Internet of Things for localized surface temperature forecasting in an urban environment
Feb 04, 2021
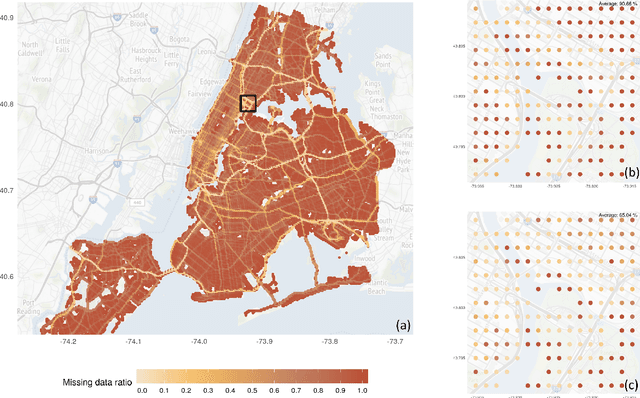
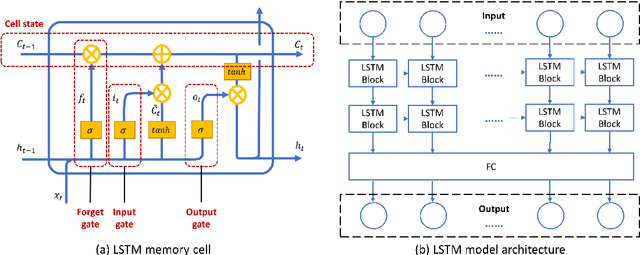
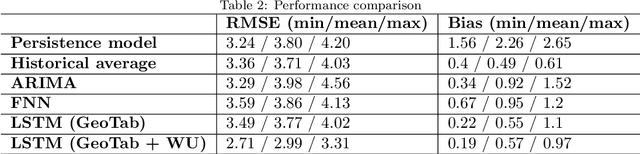
The rising temperature is one of the key indicators of a warming climate, and it can cause extensive stress to biological systems as well as built structures. Due to the heat island effect, it is most severe in urban environments compared to other landscapes due to the decrease in vegetation associated with a dense human-built environment. It is essential to adequately monitor the local temperature dynamics to mitigate risks associated with increasing temperatures, which can include short term strategy to protect people and animals, to long term strategy to how to build a new structure and cope with extreme events. Observed temperature is also a very important input for atmospheric models, and accurate data can lead to better future forecasts. Ambient temperature collected at ground level can have a higher variability when compared to regional weather forecasts, which fail to capture the local dynamics. There remains a clear need for an accurate air temperature prediction at the sub-urban scale at high temporal and spatial resolution. This research proposed a framework based on Long Short-Term Memory (LSTM) deep learning network to generate day-ahead hourly temperature forecast with high spatial resolution. A case study is shown which uses historical in-situ observations and Internet of Things (IoT) observations for New York City, USA. By leveraging the historical air temperature data from in-situ observations, the LSTM model can be exposed to more historical patterns that might not be present in the IoT observations. Meanwhile, by using IoT observations, the spatial resolution of air temperature predictions is significantly improved.