 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Kernels in 3D CNNs
Jun 21, 2022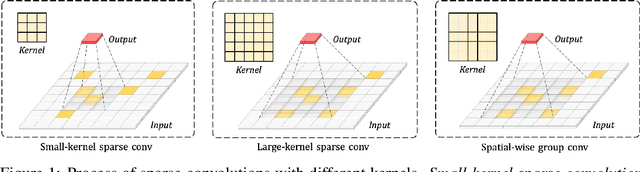
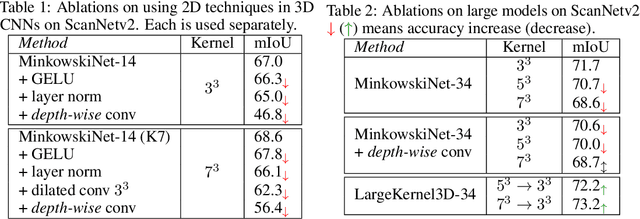

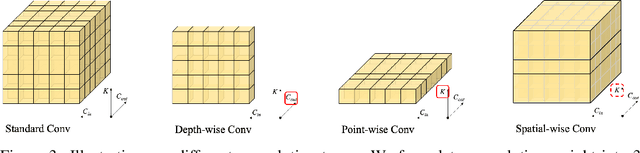
Recent advances in 2D CNNs and vision transformers (ViTs) reveal that large kernels are essential for enough receptive fields and high performance. Inspired by this literature, we examine the feasibility and challenges of 3D large-kernel designs. We demonstrate that applying large convolutional kernels in 3D CNNs has more difficulties in both performance and efficiency. Existing techniques that work well in 2D CNNs are ineffective in 3D networks, including the popular depth-wise convolutions. To overcome these obstacles, we present the spatial-wise group convolution and its large-kernel module (SW-LK block). It avoids the optimization and efficiency issues of naive 3D large kernels. Our large-kernel 3D CNN network, i.e., LargeKernel3D, yields non-trivial improvements on various 3D tasks, including semantic segmentation and object detection. Notably, it achieves 73.9% mIoU on the ScanNetv2 semantic segmentation and 72.8% NDS nuScenes object detection benchmarks, ranking 1st on the nuScenes LIDAR leaderboard. It is further boosted to 74.2% NDS with a simple multi-modal fusion. LargeKernel3D attains comparable or superior results than its CNN and transformer counterparts. For the first time, we show that large kernels are feasible and essential for 3D networks.
Duplex Conversation: Towards Human-like Interaction in Spoken Dialogue Systems
Jun 09, 2022

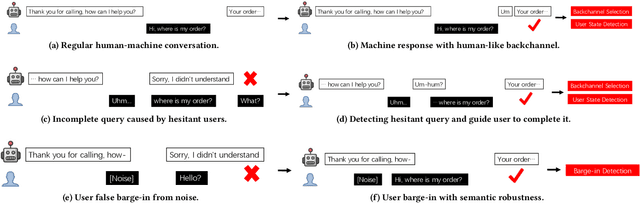
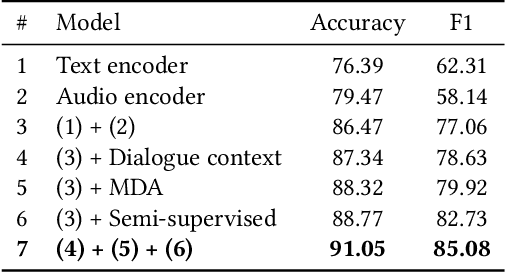
In this paper, we present Duplex Conversation, a multi-turn, multimodal spoken dialogue system that enables telephone-based agents to interact with customers like a human. We use the concept of full-duplex in telecommunication to demonstrate what a human-like interactive experience should be and how to achieve smooth turn-taking through three subtasks: user state detection, backchannel selection, and barge-in detection. Besides, we propose semi-supervised learning with multimodal data augmentation to leverage unlabeled data to increase model generalization. Experimental results on three sub-tasks show that the proposed method achieves consistent improvements compared with baselines. We deploy the Duplex Conversation to Alibaba intelligent customer service and share lessons learned in production. Online A/B experiments show that the proposed system can significantly reduce response latency by 50%.
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
Jun 02, 2022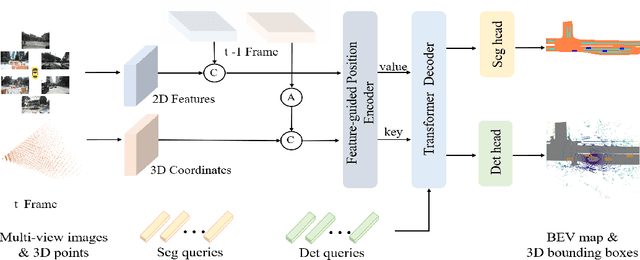
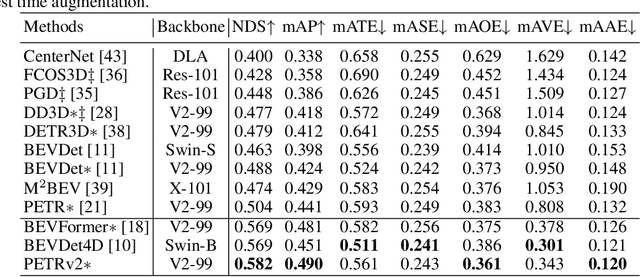
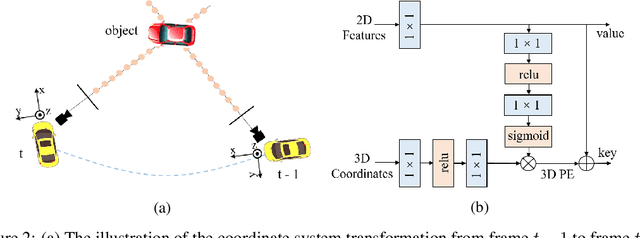
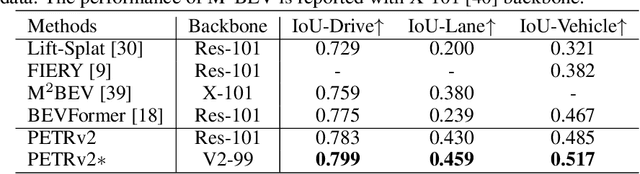
In this paper, we propose PETRv2, a unified framework for 3D perception from multi-view images. Based on PETR, PETRv2 explores the effectiveness of temporal modeling, which utilizes the temporal information of previous frames to boost 3D object detection. More specifically, we extend the 3D position embedding (3D PE) in PETR for temporal modeling. The 3D PE achieves the temporal alignment on object position of different frames. A feature-guided position encoder is further introduced to improve the data adaptability of 3D PE. To support for high-quality BEV segmentation, PETRv2 provides a simply yet effective solution by adding a set of segmentation queries. Each segmentation query is responsible for segmenting one specific patch of BEV map. PETRv2 achieves state-of-the-art performance on 3D object detection and BEV segmentation. Detailed robustness analysis is also conducted on PETR framework. We hope PETRv2 can serve as a unified framework for 3D perception.
Unifying Voxel-based Representation with Transformer for 3D Object Detection
Jun 01, 2022
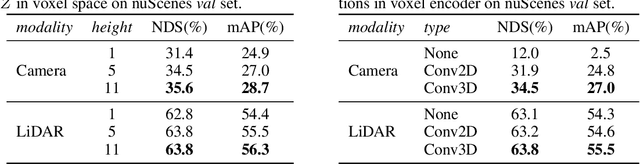
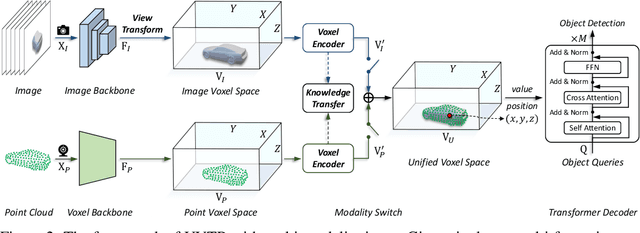
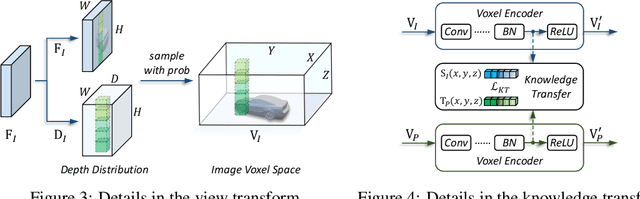
In this work, we present a unified framework for multi-modality 3D object detection, named UVTR. The proposed method aims to unify multi-modality representations in the voxel space for accurate and robust single- or cross-modality 3D detection. To this end, the modality-specific space is first designed to represent different inputs in the voxel feature space. Different from previous work, our approach preserves the voxel space without height compression to alleviate semantic ambiguity and enable spatial interactions. Benefit from the unified manner, cross-modality interaction is then proposed to make full use of inherent properties from different sensors, including knowledge transfer and modality fusion. In this way, geometry-aware expressions in point clouds and context-rich features in images are well utilized for better performance and robustness. The transformer decoder is applied to efficiently sample features from the unified space with learnable positions, which facilitates object-level interactions. In general, UVTR presents an early attempt to represent different modalities in a unified framework. It surpasses previous work in single- and multi-modality entries and achieves leading performance in the nuScenes test set with 69.7%, 55.1%, and 71.1% NDS for LiDAR, camera, and multi-modality inputs, respectively. Code is made available at https://github.com/dvlab-research/UVTR.
Voxel Field Fusion for 3D Object Detection
May 31, 2022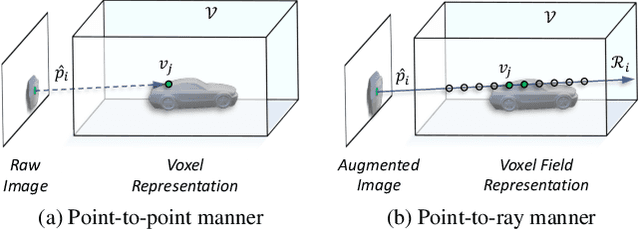

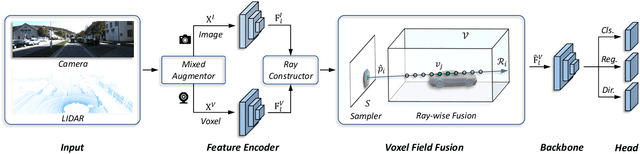
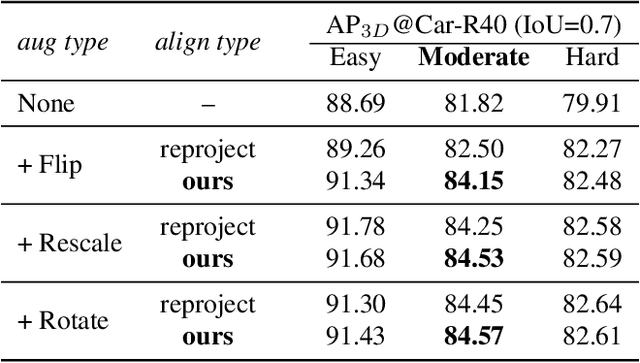
In this work, we present a conceptually simple yet effective framework for cross-modality 3D object detection, named voxel field fusion. The proposed approach aims to maintain cross-modality consistency by representing and fusing augmented image features as a ray in the voxel field. To this end, the learnable sampler is first designed to sample vital features from the image plane that are projected to the voxel grid in a point-to-ray manner, which maintains the consistency in feature representation with spatial context. In addition, ray-wise fusion is conducted to fuse features with the supplemental context in the constructed voxel field. We further develop mixed augmentor to align feature-variant transformations, which bridges the modality gap in data augmentation. The proposed framework is demonstrated to achieve consistent gains in various benchmarks and outperforms previous fusion-based methods on KITTI and nuScenes datasets. Code is made available at https://github.com/dvlab-research/VFF.
VoGE: A Differentiable Volume Renderer using Gaussian Ellipsoids for Analysis-by-Synthesis
May 30, 2022

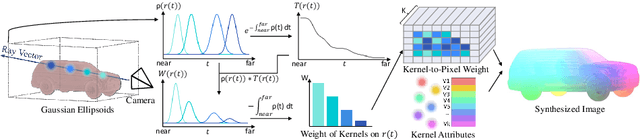
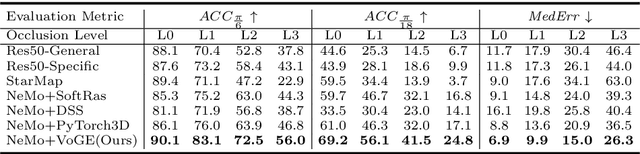
Differentiable rendering allows the application of computer graphics on vision tasks, e.g. object pose and shape fitting, via analysis-by-synthesis, where gradients at occluded regions are important when inverting the rendering process. To obtain those gradients, state-of-the-art (SoTA) differentiable renderers use rasterization to collect a set of nearest components for each pixel and aggregate them based on the viewing distance. In this paper, we propose VoGE, which uses ray tracing to capture nearest components with their volume density distributions on the rays and aggregates via integral of the volume densities based on Gaussian ellipsoids, which brings more efficient and stable gradients. To efficiently render via VoGE, we propose an approximate close-form solution for the volume density aggregation and a coarse-to-fine rendering strategy. Finally, we provide a CUDA implementation of VoGE, which gives a competitive rendering speed in comparison to PyTorch3D. Quantitative and qualitative experiment results show VoGE outperforms SoTA counterparts when applied to various vision tasks,e.g., object pose estimation, shape/texture fitting, and occlusion reasoning. The VoGE library and demos are available at https://github.com/Angtian/VoGE.
A Closer Look at Self-supervised Lightweight Vision Transformers
May 28, 2022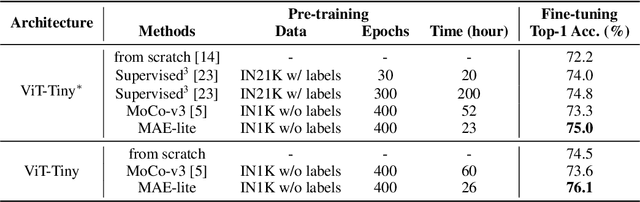
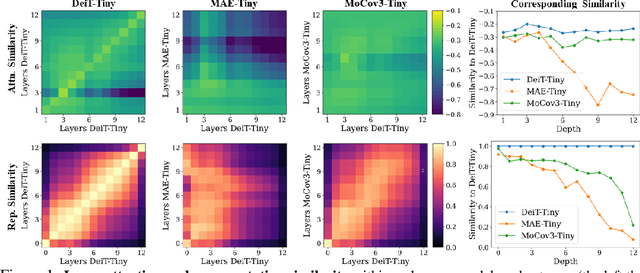
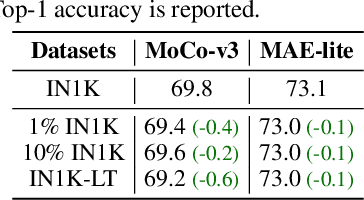
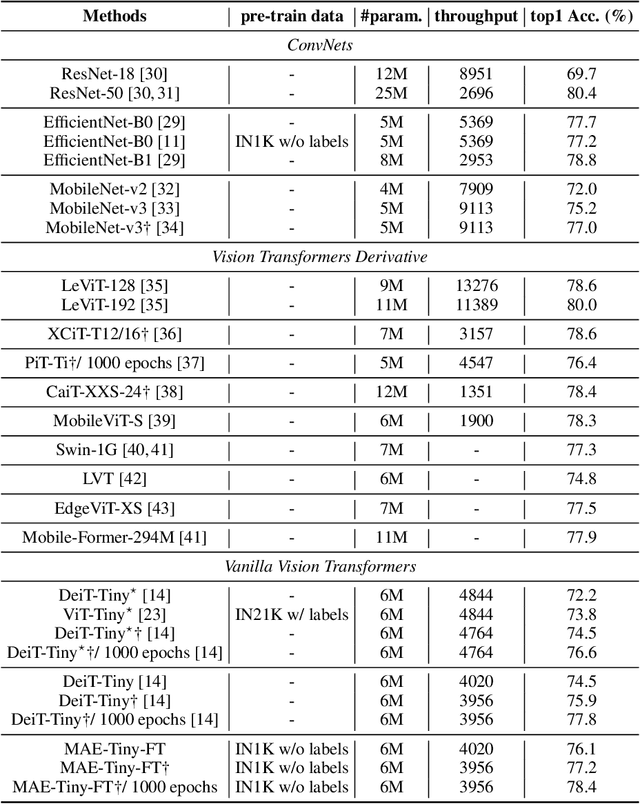
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022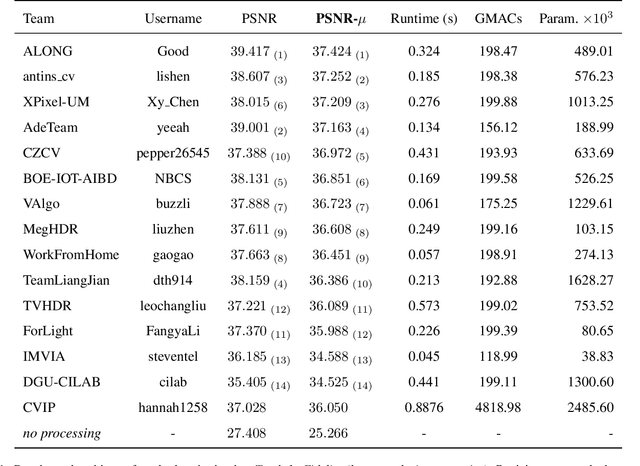
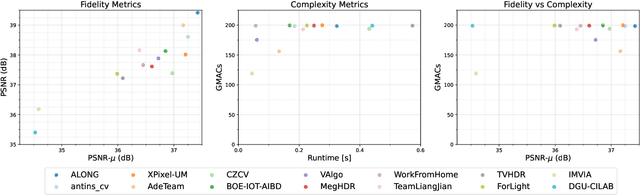
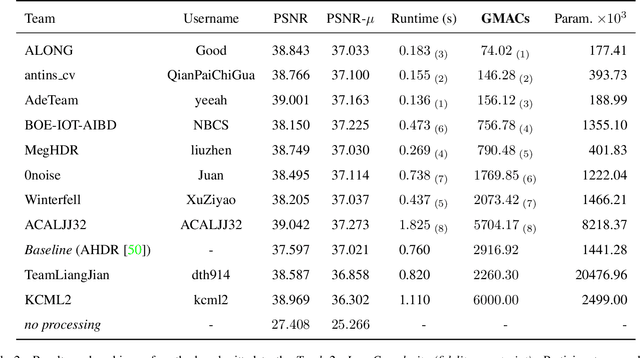
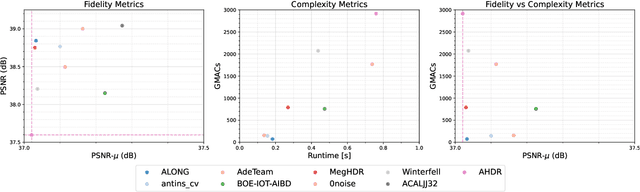
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
A Survey on Neural Open Information Extraction: Current Status and Future Directions
May 24, 2022
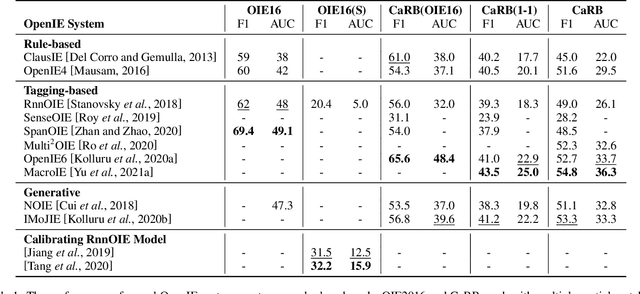
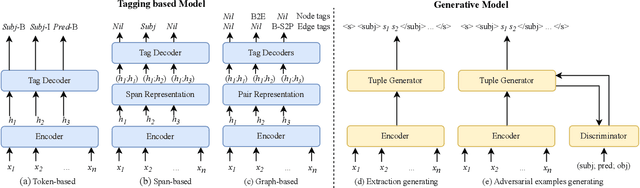
Open Information Extraction (OpenIE) facilitates domain-independent discovery of relational facts from large corpora. The technique well suits many open-world natural language understanding scenarios, such as automatic knowledge base construction, open-domain question answering, and explicit reasoning. Thanks to the rapid development in deep learning technologies, numerous neural OpenIE architectures have been proposed and achieve considerable performance improvement. In this survey, we provide an extensive overview of the-state-of-the-art neural OpenIE models, their key design decisions, strengths and weakness. Then, we discuss limitations of current solutions and the open issues in OpenIE problem itself. Finally we list recent trends that could help expand its scope and applicability, setting up promising directions for future research in OpenIE. To our best knowledge, this paper is the first review on this specific topic.
Truncated tensor Schatten p-norm based approach for spatiotemporal traffic data imputation with complicated missing patterns
May 19, 2022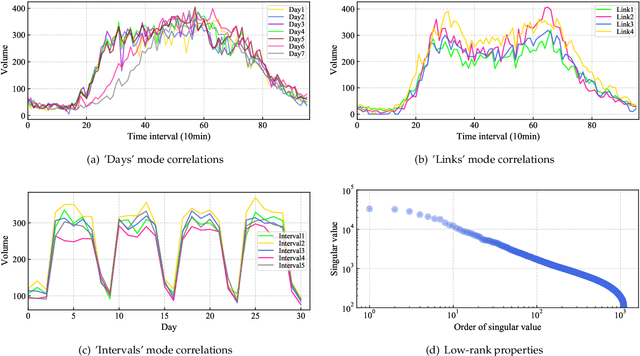
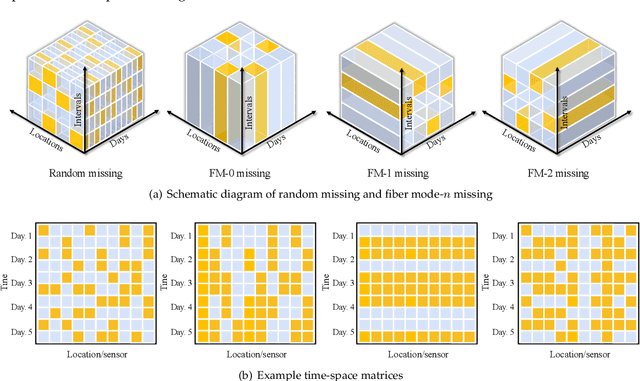
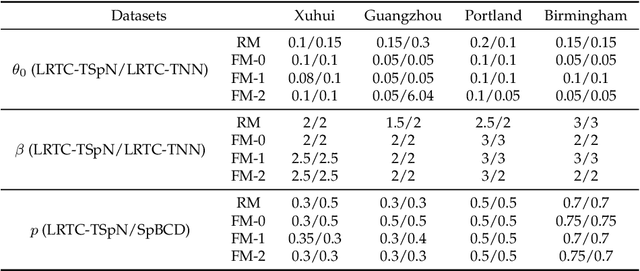
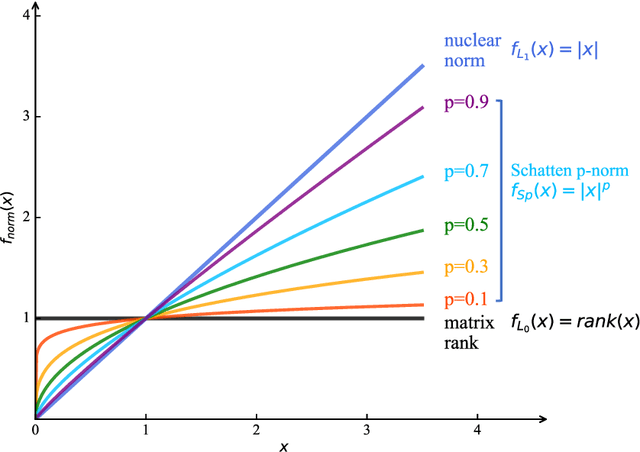
Rapid advances in sensor, wireless communication, cloud computing and data science have brought unprecedented amount of data to assist transportation engineers and researchers in making better decisions. However, traffic data in reality often has corrupted or incomplete values due to detector and communication malfunctions. Data imputation is thus required to ensure the effectiveness of downstream data-driven applications. To this end, numerous tensor-based methods treating the imputation problem as the low-rank tensor completion (LRTC) have been attempted in previous works. To tackle rank minimization, which is at the core of the LRTC, most of aforementioned methods utilize the tensor nuclear norm (NN) as a convex surrogate for the minimization. However, the over-relaxation issue in NN refrains it from desirable performance in practice. In this paper, we define an innovative nonconvex truncated Schatten p-norm for tensors (TSpN) to approximate tensor rank and impute missing spatiotemporal traffic data under the LRTC framework. We model traffic data into a third-order tensor structure of (time intervals,locations (sensors),days) and introduce four complicated missing patterns, including random missing and three fiber-like missing cases according to the tensor mode-n fibers. Despite nonconvexity of the objective function in our model, we derive the global optimal solutions by integrating the alternating direction method of multipliers (ADMM) with generalized soft-thresholding (GST). In addition, we design a truncation rate decay strategy to deal with varying missing rate scenarios. Comprehensive experiments are finally conducted using real-world spatiotemporal datasets, which demonstrate that the proposed LRTC-TSpN method performs well under various missing cases, meanwhile outperforming other SOTA tensor-based imputation models in almost all scenarios.