 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cross-Modality Modeling for Time Series Analytics: A Survey in the LLM Era
May 05, 2025The proliferation of edge devices has generated an unprecedented volume of time series data across different domains, motivating various well-customized methods. Recently, Large Language Models (LLMs) have emerged as a new paradigm for time series analytics by leveraging the shared sequential nature of textual data and time series. However, a fundamental cross-modality gap between time series and LLMs exists, as LLMs are pre-trained on textual corpora and are not inherently optimized for time series. Many recent proposals are designed to address this issue. In this survey, we provide an up-to-date overview of LLMs-based cross-modality modeling for time series analytics. We first introduce a taxonomy that classifies existing approaches into four groups based on the type of textual data employed for time series modeling. We then summarize key cross-modality strategies, e.g., alignment and fusion, and discuss their applications across a range of downstream tasks. Furthermore, we conduct experiments on multimodal datasets from different application domains to investigate effective combinations of textual data and cross-modality strategies for enhancing time series analytics. Finally, we suggest several promising directions for future research. This survey is designed for a range of professionals, researchers, and practitioners interested in LLM-based time series modeling.
Efficient Multivariate Time Series Forecasting via Calibrated Language Models with Privileged Knowledge Distillation
May 04, 2025Multivariate time series forecasting (MTSF) endeavors to predict future observations given historical data, playing a crucial role in time series data management systems. With advancements in large language models (LLMs), recent studies employ textual prompt tuning to infuse the knowledge of LLMs into MTSF. However, the deployment of LLMs often suffers from low efficiency during the inference phase. To address this problem, we introduce TimeKD, an efficient MTSF framework that leverages the calibrated language models and privileged knowledge distillation. TimeKD aims to generate high-quality future representations from the proposed cross-modality teacher model and cultivate an effective student model. The cross-modality teacher model adopts calibrated language models (CLMs) with ground truth prompts, motivated by the paradigm of Learning Under Privileged Information (LUPI). In addition, we design a subtractive cross attention (SCA) mechanism to refine these representations. To cultivate an effective student model, we propose an innovative privileged knowledge distillation (PKD) mechanism including correlation and feature distillation. PKD enables the student to replicate the teacher's behavior while minimizing their output discrepancy. Extensive experiments on real data offer insight into the effectiveness, efficiency, and scalability of the proposed TimeKD.
A Survey on Neural Open Information Extraction: Current Status and Future Directions
May 24, 2022
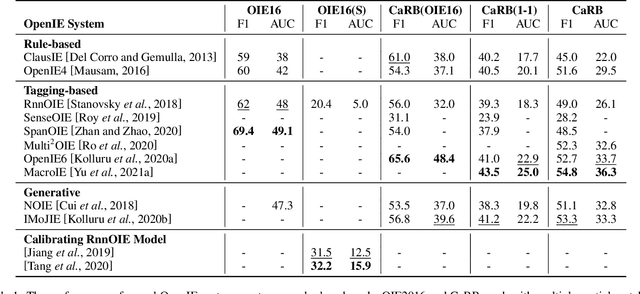
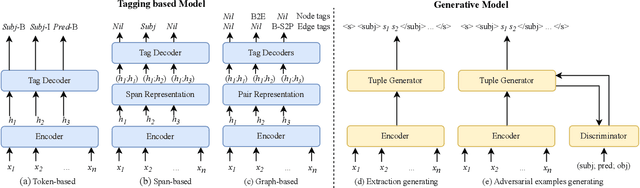
Open Information Extraction (OpenIE) facilitates domain-independent discovery of relational facts from large corpora. The technique well suits many open-world natural language understanding scenarios, such as automatic knowledge base construction, open-domain question answering, and explicit reasoning. Thanks to the rapid development in deep learning technologies, numerous neural OpenIE architectures have been proposed and achieve considerable performance improvement. In this survey, we provide an extensive overview of the-state-of-the-art neural OpenIE models, their key design decisions, strengths and weakness. Then, we discuss limitations of current solutions and the open issues in OpenIE problem itself. Finally we list recent trends that could help expand its scope and applicability, setting up promising directions for future research in OpenIE. To our best knowledge, this paper is the first review on this specific topic.