 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-Transcriber: A Robust End-to-End Framework for Multi-Speaker Speech Transcription
Jun 01, 2026Recent advances in Automatic Speech Recognition (ASR) and Large Language Models (LLMs) have significantly improved speech understanding capabilities. However, multi-speaker speech transcription remains challenging task, constrained by highly similar speaker voices, rapid turn-taking transitions, overlapping utterances and inaccurate speaker boundary segmentation. These challenges become particularly pronounced in real-world conversational audio, where speaker dynamics and acoustic conditions are highly variable. This technical report presents SoulX-Transcriber, a unified multi-speaker transcription system that jointly models speaker diarization (SD) and ASR within an LLM-based framework. SoulX-Transcriber adopts a two-stage training strategy to improve both speaker discrimination and transcription robustness. In the first stage, speaker-aware multi-task continuous pre-training enhances speaker representation learning and boundary perception. In the second stage, supervised fine-tuning further optimizes the model for accurate end-to-end speaker-attributed transcription under complex multi-speaker conditions. SoulX-Transcriber delivers strong performance and robustness across multiple public benchmarks, including AliMeeting, AISHELL-4, and AMI, while maintaining high adaptability to multi-domain scenarios.
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
WenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Automatic Prosody Prediction for Chinese Speech Synthesis using BLSTM-RNN and Embedding Features
Nov 02, 2015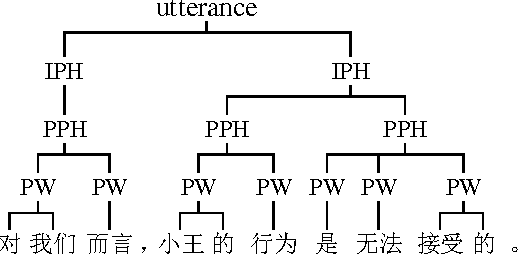
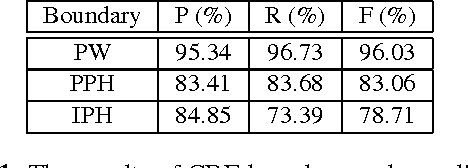
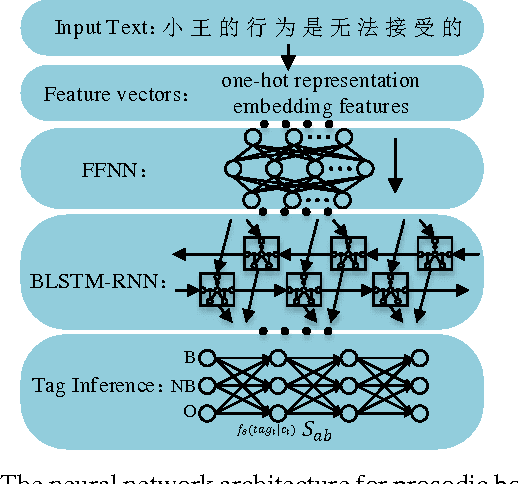

Prosody affects the naturalness and intelligibility of speech. However, automatic prosody prediction from text for Chinese speech synthesis is still a great challenge and the traditional conditional random fields (CRF) based method always heavily relies on feature engineering. In this paper, we propose to use neural networks to predict prosodic boundary labels directly from Chinese characters without any feature engineering. Experimental results show that stacking feed-forward and bidirectional long short-term memory (BLSTM) recurrent network layers achieves superior performance over the CRF-based method. The embedding features learned from raw text further enhance the performance.