 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-YOLOX: A High Precision Detector for Object Detection in Satellite Remote Sensing Images
Feb 05, 2025



Automatic object detection by satellite remote sensing images is of great significance for resource exploration and natural disaster assessment. To solve existing problems in remote sensing image detection, this article proposes an improved YOLOX model for satellite remote sensing image automatic detection. This model is named RS-YOLOX. To strengthen the feature learning ability of the network, we used Efficient Channel Attention (ECA) in the backbone network of YOLOX and combined the Adaptively Spatial Feature Fusion (ASFF) with the neck network of YOLOX. To balance the numbers of positive and negative samples in training, we used the Varifocal Loss function. Finally, to obtain a high-performance remote sensing object detector, we combined the trained model with an open-source framework called Slicing Aided Hyper Inference (SAHI). This work evaluated models on three aerial remote sensing datasets (DOTA-v1.5, TGRS-HRRSD, and RSOD). Our comparative experiments demonstrate that our model has the highest accuracy in detecting objects in remote sensing image datasets.
ST$^3$: Accelerating Multimodal Large Language Model by Spatial-Temporal Visual Token Trimming
Dec 28, 2024



Multimodal large language models (MLLMs) enhance their perceptual capabilities by integrating visual and textual information. However, processing the massive number of visual tokens incurs a significant computational cost. Existing analysis of the MLLM attention mechanisms remains shallow, leading to coarse-grain token pruning strategies that fail to effectively balance speed and accuracy. In this paper, we conduct a comprehensive investigation of MLLM attention mechanisms with LLaVA. We find that numerous visual tokens and partial attention computations are redundant during the decoding process. Based on this insight, we propose Spatial-Temporal Visual Token Trimming ($\textbf{ST}^{3}$), a framework designed to accelerate MLLM inference without retraining. $\textbf{ST}^{3}$ consists of two primary components: 1) Progressive Visual Token Pruning (\textbf{PVTP}), which eliminates inattentive visual tokens across layers, and 2) Visual Token Annealing (\textbf{VTA}), which dynamically reduces the number of visual tokens in each layer as the generated tokens grow. Together, these techniques deliver around $\mathbf{2\times}$ faster inference with only about $\mathbf{30\%}$ KV cache memory compared to the original LLaVA, while maintaining consistent performance across various datasets. Crucially, $\textbf{ST}^{3}$ can be seamlessly integrated into existing pre-trained MLLMs, providing a plug-and-play solution for efficient inference.
Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers
Dec 22, 2024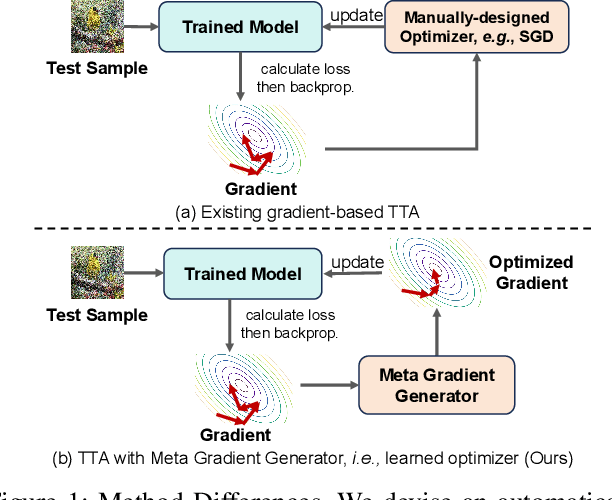
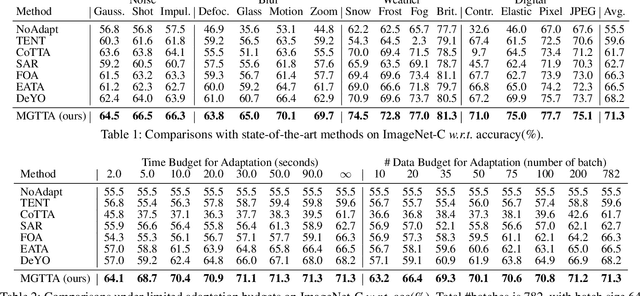
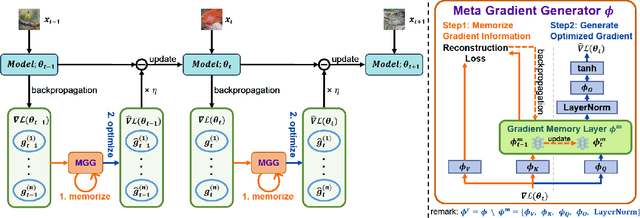
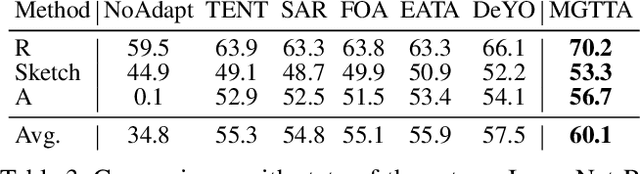
Test-time adaptation (TTA) aims to fine-tune a trained model online using unlabeled testing data to adapt to new environments or out-of-distribution data, demonstrating broad application potential in real-world scenarios. However, in this optimization process, unsupervised learning objectives like entropy minimization frequently encounter noisy learning signals. These signals produce unreliable gradients, which hinder the model ability to converge to an optimal solution quickly and introduce significant instability into the optimization process. In this paper, we seek to resolve these issues from the perspective of optimizer design. Unlike prior TTA using manually designed optimizers like SGD, we employ a learning-to-optimize approach to automatically learn an optimizer, called Meta Gradient Generator (MGG). Specifically, we aim for MGG to effectively utilize historical gradient information during the online optimization process to optimize the current model. To this end, in MGG, we design a lightweight and efficient sequence modeling layer -- gradient memory layer. It exploits a self-supervised reconstruction loss to compress historical gradient information into network parameters, thereby enabling better memorization ability over a long-term adaptation process. We only need a small number of unlabeled samples to pre-train MGG, and then the trained MGG can be deployed to process unseen samples. Promising results on ImageNet-C, R, Sketch, and A indicate that our method surpasses current state-of-the-art methods with fewer updates, less data, and significantly shorter adaptation iterations. Compared with a previous SOTA method SAR, we achieve 7.4% accuracy improvement and 4.2 times faster adaptation speed on ImageNet-C.
* 3 figures, 11 tables
GUI Agents: A Survey
Dec 18, 2024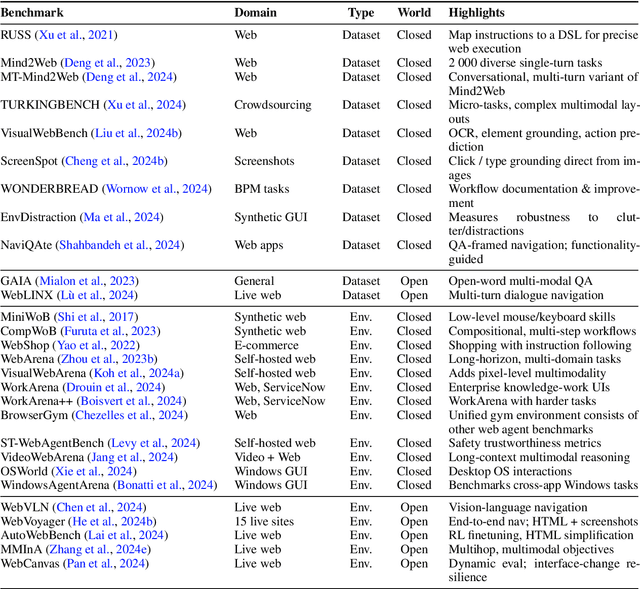
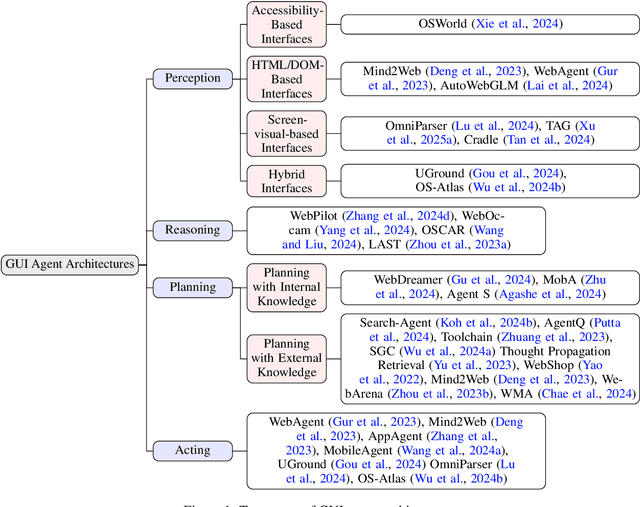

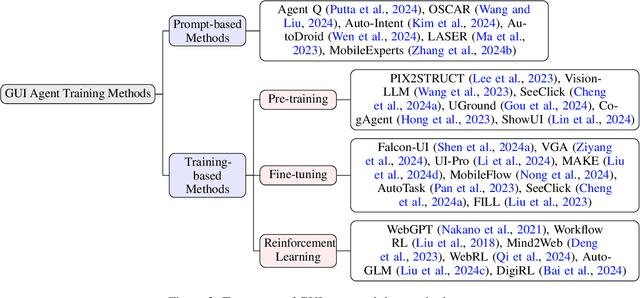
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
F-SE-LSTM: A Time Series Anomaly Detection Method with Frequency Domain Information
Dec 03, 2024



With the development of society, time series anomaly detection plays an important role in network and IoT services. However, most existing anomaly detection methods directly analyze time series in the time domain and cannot distinguish some relatively hidden anomaly sequences. We attempt to analyze the impact of frequency on time series from a frequency domain perspective, thus proposing a new time series anomaly detection method called F-SE-LSTM. This method utilizes two sliding windows and fast Fourier transform (FFT) to construct a frequency matrix. Simultaneously, Squeeze-and-Excitation Networks (SENet) and Long Short-Term Memory (LSTM) are employed to extract frequency-related features within and between periods. Through comparative experiments on multiple datasets such as Yahoo Webscope S5 and Numenta Anomaly Benchmark, the results demonstrate that the frequency matrix constructed by F-SE-LSTM exhibits better discriminative ability than ordinary time domain and frequency domain data. Furthermore, F-SE-LSTM outperforms existing state-of-the-art deep learning anomaly detection methods in terms of anomaly detection capability and execution efficiency.
A Survey of Medical Vision-and-Language Applications and Their Techniques
Nov 19, 2024



Medical vision-and-language models (MVLMs) have attracted substantial interest due to their capability to offer a natural language interface for interpreting complex medical data. Their applications are versatile and have the potential to improve diagnostic accuracy and decision-making for individual patients while also contributing to enhanced public health monitoring, disease surveillance, and policy-making through more efficient analysis of large data sets. MVLMS integrate natural language processing with medical images to enable a more comprehensive and contextual understanding of medical images alongside their corresponding textual information. Unlike general vision-and-language models trained on diverse, non-specialized datasets, MVLMs are purpose-built for the medical domain, automatically extracting and interpreting critical information from medical images and textual reports to support clinical decision-making. Popular clinical applications of MVLMs include automated medical report generation, medical visual question answering, medical multimodal segmentation, diagnosis and prognosis and medical image-text retrieval. Here, we provide a comprehensive overview of MVLMs and the various medical tasks to which they have been applied. We conduct a detailed analysis of various vision-and-language model architectures, focusing on their distinct strategies for cross-modal integration/exploitation of medical visual and textual features. We also examine the datasets used for these tasks and compare the performance of different models based on standardized evaluation metrics. Furthermore, we highlight potential challenges and summarize future research trends and directions. The full collection of papers and codes is available at: https://github.com/YtongXie/Medical-Vision-and-Language-Tasks-and-Methodologies-A-Survey.
MICCAI-CDMRI 2023 QuantConn Challenge Findings on Achieving Robust Quantitative Connectivity through Harmonized Preprocessing of Diffusion MRI
Nov 14, 2024



White matter alterations are increasingly implicated in neurological diseases and their progression. International-scale studies use diffusion-weighted magnetic resonance imaging (DW-MRI) to qualitatively identify changes in white matter microstructure and connectivity. Yet, quantitative analysis of DW-MRI data is hindered by inconsistencies stemming from varying acquisition protocols. There is a pressing need to harmonize the preprocessing of DW-MRI datasets to ensure the derivation of robust quantitative diffusion metrics across acquisitions. In the MICCAI-CDMRI 2023 QuantConn challenge, participants were provided raw data from the same individuals collected on the same scanner but with two different acquisitions and tasked with preprocessing the DW-MRI to minimize acquisition differences while retaining biological variation. Submissions are evaluated on the reproducibility and comparability of cross-acquisition bundle-wise microstructure measures, bundle shape features, and connectomics. The key innovations of the QuantConn challenge are that (1) we assess bundles and tractography in the context of harmonization for the first time, (2) we assess connectomics in the context of harmonization for the first time, and (3) we have 10x additional subjects over prior harmonization challenge, MUSHAC and 100x over SuperMUDI. We find that bundle surface area, fractional anisotropy, connectome assortativity, betweenness centrality, edge count, modularity, nodal strength, and participation coefficient measures are most biased by acquisition and that machine learning voxel-wise correction, RISH mapping, and NeSH methods effectively reduce these biases. In addition, microstructure measures AD, MD, RD, bundle length, connectome density, efficiency, and path length are least biased by these acquisition differences.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024/019
LoRA-Contextualizing Adaptation of Large Multimodal Models for Long Document Understanding
Nov 02, 2024Large multimodal models (LMMs) have recently shown great progress in text-rich image understanding, yet they still struggle with complex, multi-page, visually-rich documents. Traditional methods using document parsers for retrieval-augmented generation suffer from performance and efficiency limitations, while directly presenting all pages to LMMs leads to inefficiencies, especially with lengthy documents. In this work, we present a novel framework named LoRA-Contextualizing Adaptation of Large multimodal models (LoCAL), which broadens the capabilities of any LMM to support long-document understanding. We demonstrate that LMMs can effectively serve as multimodal retrievers, fetching relevant pages to answer user questions based on these pages. LoCAL is implemented with two specific LMM adapters: one for evidence page retrieval and another for question answering. Empirical results show state-of-the-art performance on public benchmarks, demonstrating the effectiveness of LoCAL.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
TextLap: Customizing Language Models for Text-to-Layout Planning
Oct 09, 2024



Automatic generation of graphical layouts is crucial for many real-world applications, including designing posters, flyers, advertisements, and graphical user interfaces. Given the incredible ability of Large language models (LLMs) in both natural language understanding and generation, we believe that we could customize an LLM to help people create compelling graphical layouts starting with only text instructions from the user. We call our method TextLap (text-based layout planning). It uses a curated instruction-based layout planning dataset (InsLap) to customize LLMs as a graphic designer. We demonstrate the effectiveness of TextLap and show that it outperforms strong baselines, including GPT-4 based methods, for image generation and graphical design benchmarks.