 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022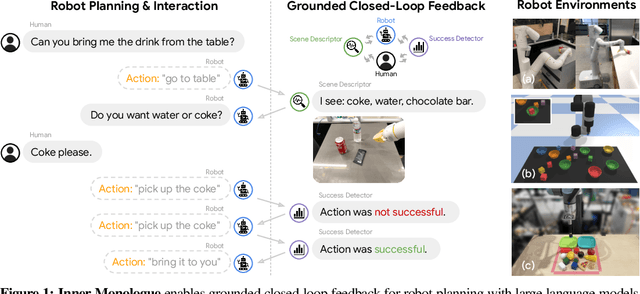
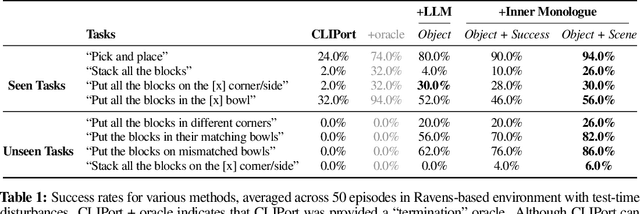


Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Learning Iterative Reasoning through Energy Minimization
Jun 30, 2022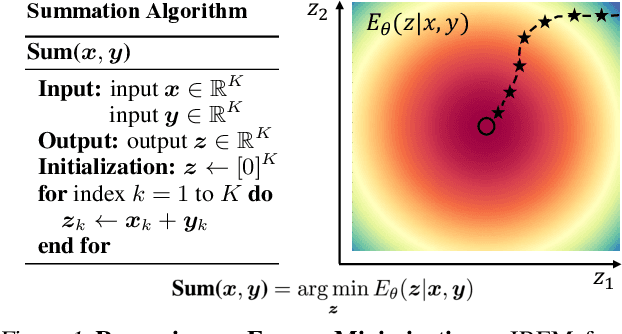
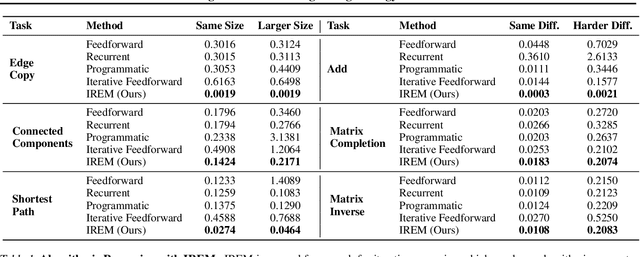
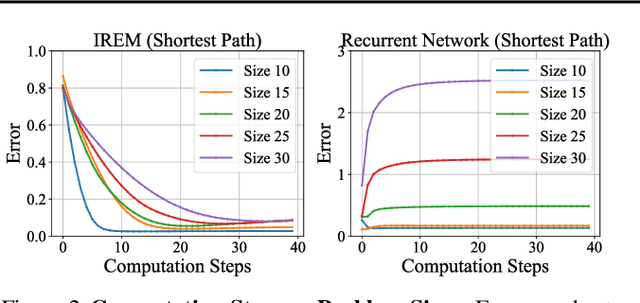
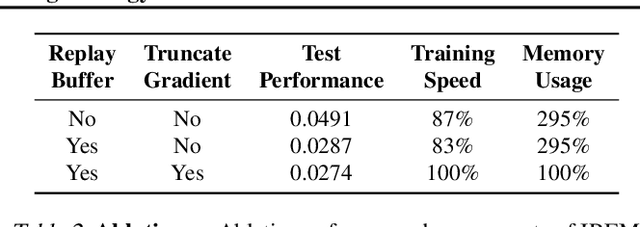
Deep learning has excelled on complex pattern recognition tasks such as image classification and object recognition. However, it struggles with tasks requiring nontrivial reasoning, such as algorithmic computation. Humans are able to solve such tasks through iterative reasoning -- spending more time thinking about harder tasks. Most existing neural networks, however, exhibit a fixed computational budget controlled by the neural network architecture, preventing additional computational processing on harder tasks. In this work, we present a new framework for iterative reasoning with neural networks. We train a neural network to parameterize an energy landscape over all outputs, and implement each step of the iterative reasoning as an energy minimization step to find a minimal energy solution. By formulating reasoning as an energy minimization problem, for harder problems that lead to more complex energy landscapes, we may then adjust our underlying computational budget by running a more complex optimization procedure. We empirically illustrate that our iterative reasoning approach can solve more accurate and generalizable algorithmic reasoning tasks in both graph and continuous domains. Finally, we illustrate that our approach can recursively solve algorithmic problems requiring nested reasoning
Multi-Game Decision Transformers
May 30, 2022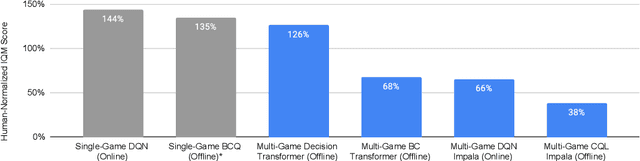

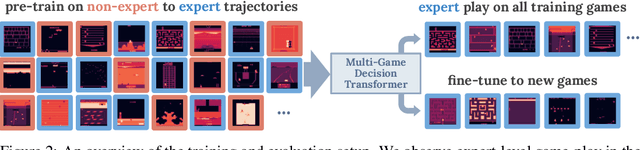
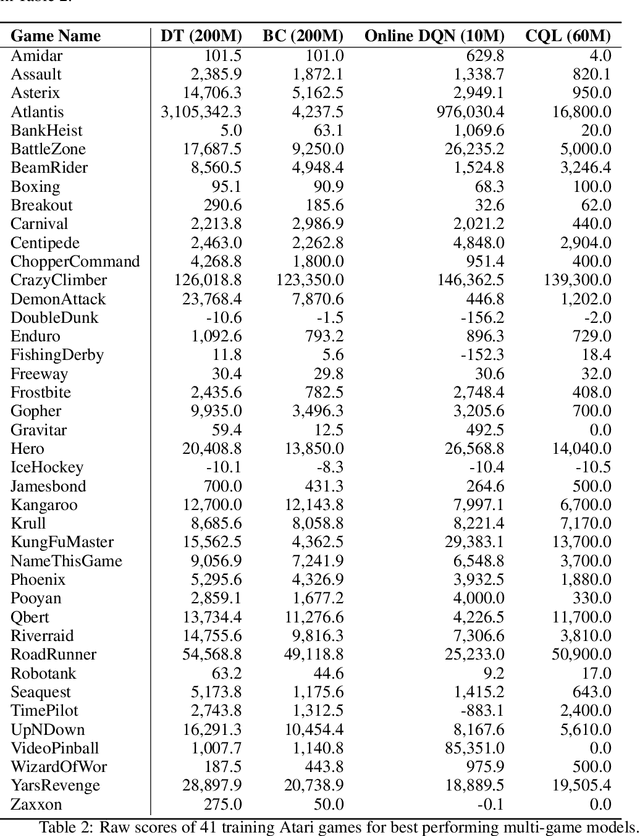
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
Blocks Assemble! Learning to Assemble with Large-Scale Structured Reinforcement Learning
Apr 12, 2022

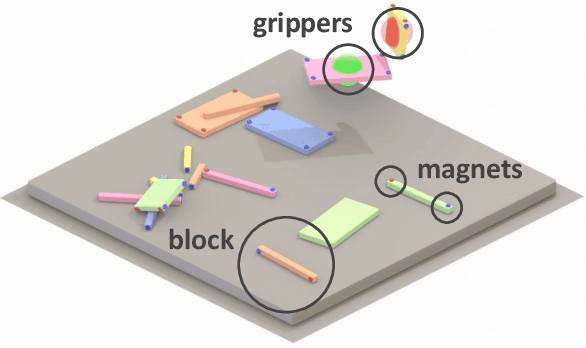

Assembly of multi-part physical structures is both a valuable end product for autonomous robotics, as well as a valuable diagnostic task for open-ended training of embodied intelligent agents. We introduce a naturalistic physics-based environment with a set of connectable magnet blocks inspired by children's toy kits. The objective is to assemble blocks into a succession of target blueprints. Despite the simplicity of this objective, the compositional nature of building diverse blueprints from a set of blocks leads to an explosion of complexity in structures that agents encounter. Furthermore, assembly stresses agents' multi-step planning, physical reasoning, and bimanual coordination. We find that the combination of large-scale reinforcement learning and graph-based policies -- surprisingly without any additional complexity -- is an effective recipe for training agents that not only generalize to complex unseen blueprints in a zero-shot manner, but even operate in a reset-free setting without being trained to do so. Through extensive experiments, we highlight the importance of large-scale training, structured representations, contributions of multi-task vs. single-task learning, as well as the effects of curriculums, and discuss qualitative behaviors of trained agents.
Bi-Manual Manipulation and Attachment via Sim-to-Real Reinforcement Learning
Mar 15, 2022
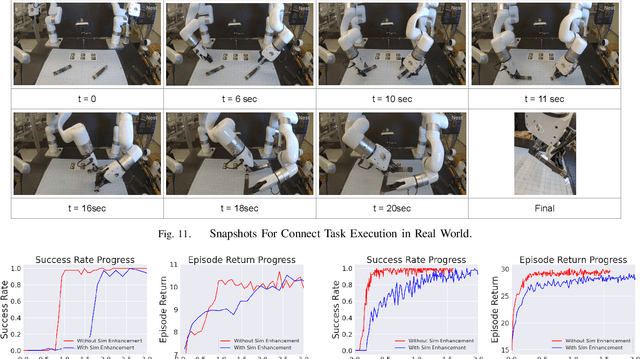
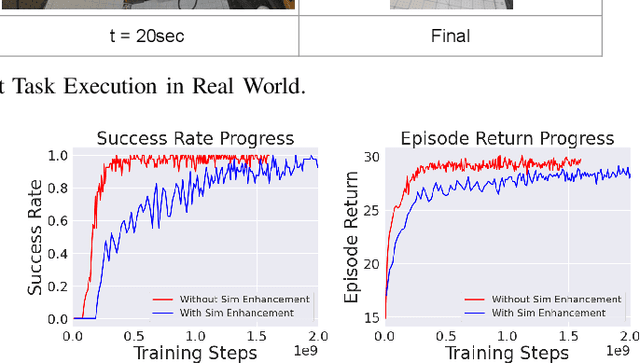
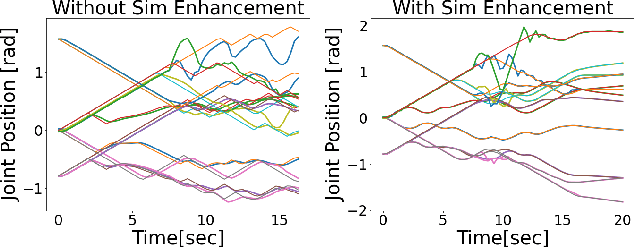
Most successes in robotic manipulation have been restricted to single-arm robots, which limits the range of solvable tasks to pick-and-place, insertion, and objects rearrangement. In contrast, dual and multi arm robot platforms unlock a rich diversity of problems that can be tackled, such as laundry folding and executing cooking skills. However, developing controllers for multi-arm robots is complexified by a number of unique challenges, such as the need for coordinated bimanual behaviors, and collision avoidance amongst robots. Given these challenges, in this work we study how to solve bi-manual tasks using reinforcement learning (RL) trained in simulation, such that the resulting policies can be executed on real robotic platforms. Our RL approach results in significant simplifications due to using real-time (4Hz) joint-space control and directly passing unfiltered observations to neural networks policies. We also extensively discuss modifications to our simulated environment which lead to effective training of RL policies. In addition to designing control algorithms, a key challenge is how to design fair evaluation tasks for bi-manual robots that stress bimanual coordination, while removing orthogonal complicating factors such as high-level perception. In this work, we design a Connect Task, where the aim is for two robot arms to pick up and attach two blocks with magnetic connection points. We validate our approach with two xArm6 robots and 3D printed blocks with magnetic attachments, and find that our system has 100% success rate at picking up blocks, and 65% success rate at the Connect Task.
Pre-Trained Language Models for Interactive Decision-Making
Feb 03, 2022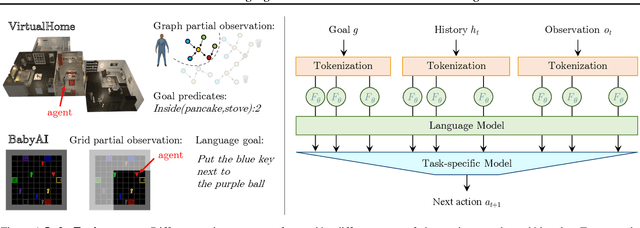
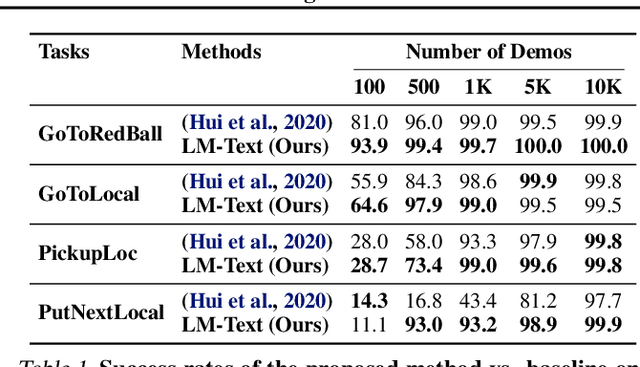
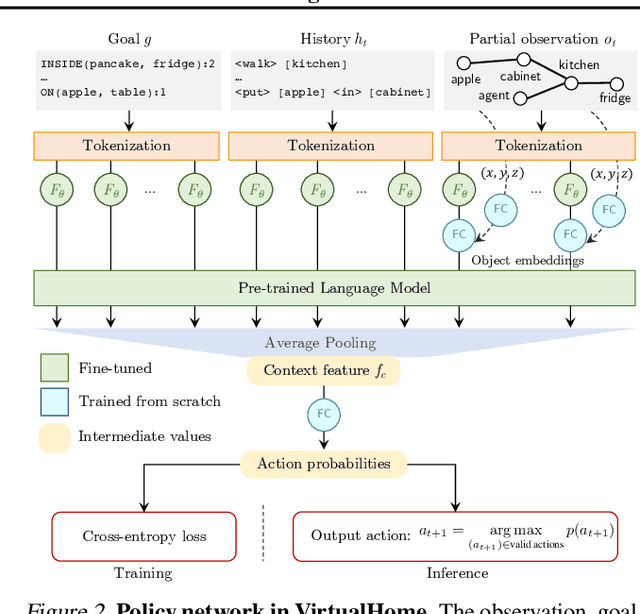
Language model (LM) pre-training has proven useful for a wide variety of language processing tasks, but can such pre-training be leveraged for more general machine learning problems? We investigate the effectiveness of language modeling to scaffold learning and generalization in autonomous decision-making. We describe a framework for imitation learning in which goals and observations are represented as a sequence of embeddings, and translated into actions using a policy network initialized with a pre-trained transformer LM. We demonstrate that this framework enables effective combinatorial generalization across different environments, such as VirtualHome and BabyAI. In particular, for test tasks involving novel goals or novel scenes, initializing policies with language models improves task completion rates by 43.6% in VirtualHome. We hypothesize and investigate three possible factors underlying the effectiveness of LM-based policy initialization. We find that sequential representations (vs. fixed-dimensional feature vectors) and the LM objective (not just the transformer architecture) are both important for generalization. Surprisingly, however, the format of the policy inputs encoding (e.g. as a natural language string vs. an arbitrary sequential encoding) has little influence. Together, these results suggest that language modeling induces representations that are useful for modeling not just language, but also goals and plans; these representations can aid learning and generalization even outside of language processing.
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
Jan 18, 2022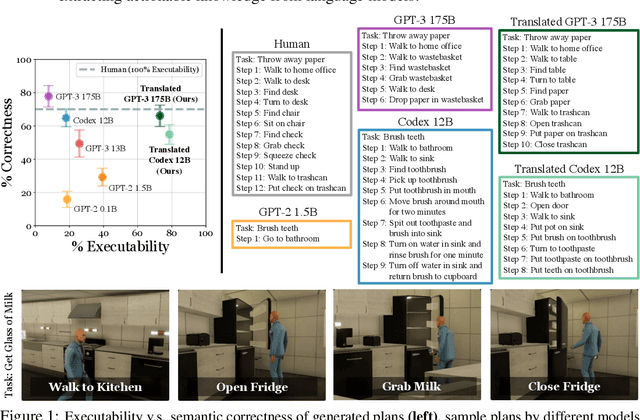
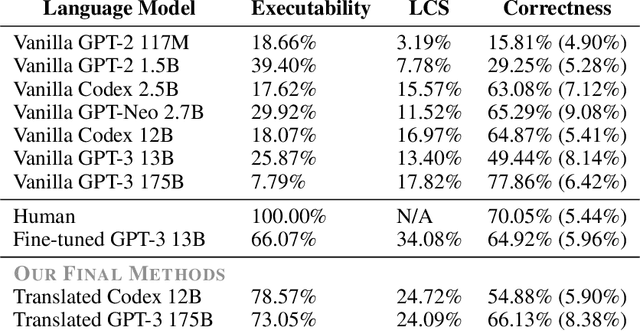
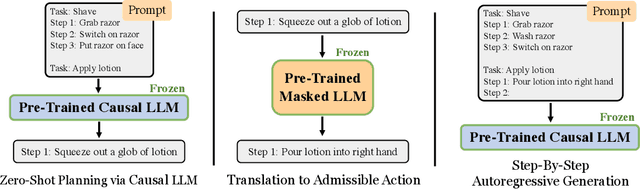
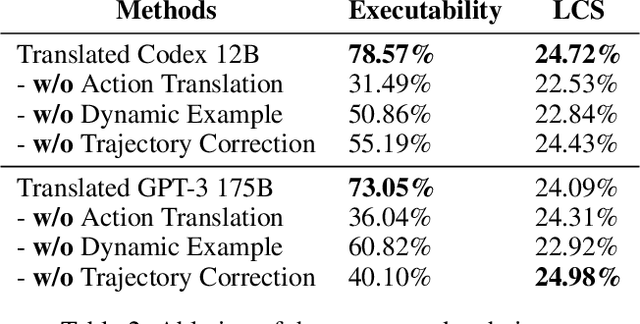
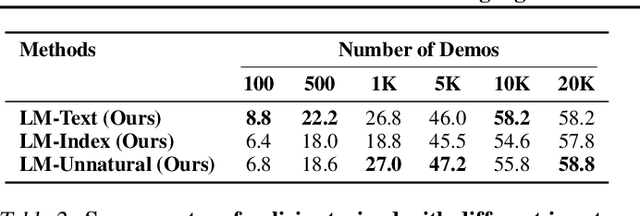
Can world knowledge learned by large language models (LLMs) be used to act in interactive environments? In this paper, we investigate the possibility of grounding high-level tasks, expressed in natural language (e.g. "make breakfast"), to a chosen set of actionable steps (e.g. "open fridge"). While prior work focused on learning from explicit step-by-step examples of how to act, we surprisingly find that if pre-trained LMs are large enough and prompted appropriately, they can effectively decompose high-level tasks into low-level plans without any further training. However, the plans produced naively by LLMs often cannot map precisely to admissible actions. We propose a procedure that conditions on existing demonstrations and semantically translates the plans to admissible actions. Our evaluation in the recent VirtualHome environment shows that the resulting method substantially improves executability over the LLM baseline. The conducted human evaluation reveals a trade-off between executability and correctness but shows a promising sign towards extracting actionable knowledge from language models. Website at https://huangwl18.github.io/language-planner
Generalization in Dexterous Manipulation via Geometry-Aware Multi-Task Learning
Nov 04, 2021
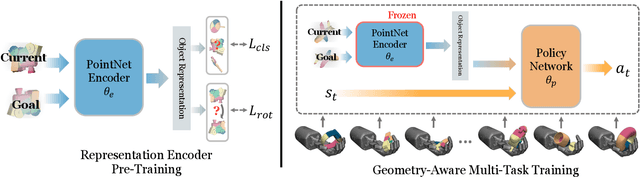
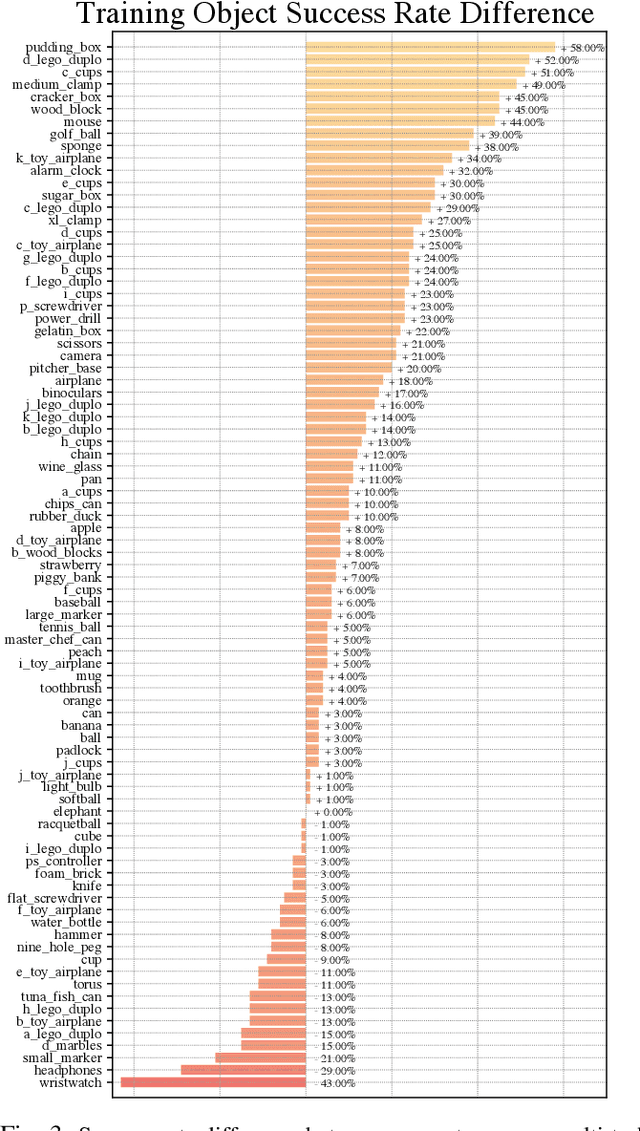
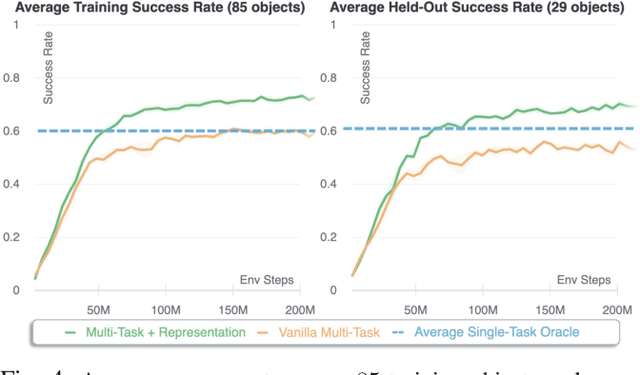
Dexterous manipulation of arbitrary objects, a fundamental daily task for humans, has been a grand challenge for autonomous robotic systems. Although data-driven approaches using reinforcement learning can develop specialist policies that discover behaviors to control a single object, they often exhibit poor generalization to unseen ones. In this work, we show that policies learned by existing reinforcement learning algorithms can in fact be generalist when combined with multi-task learning and a well-chosen object representation. We show that a single generalist policy can perform in-hand manipulation of over 100 geometrically-diverse real-world objects and generalize to new objects with unseen shape or size. Interestingly, we find that multi-task learning with object point cloud representations not only generalizes better but even outperforms the single-object specialist policies on both training as well as held-out test objects. Video results at https://huangwl18.github.io/geometry-dex
Unsupervised Learning of Compositional Energy Concepts
Nov 04, 2021
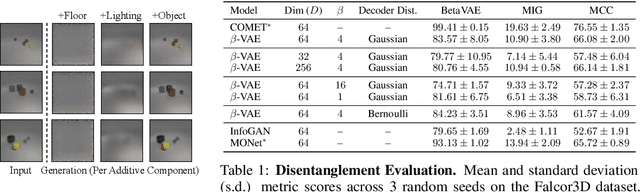
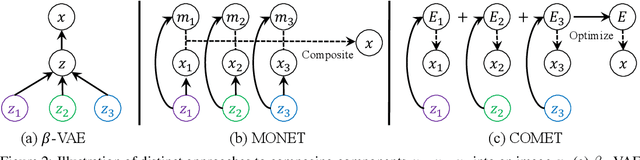
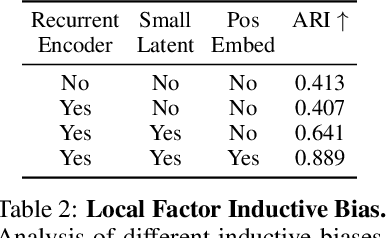
Humans are able to rapidly understand scenes by utilizing concepts extracted from prior experience. Such concepts are diverse, and include global scene descriptors, such as the weather or lighting, as well as local scene descriptors, such as the color or size of a particular object. So far, unsupervised discovery of concepts has focused on either modeling the global scene-level or the local object-level factors of variation, but not both. In this work, we propose COMET, which discovers and represents concepts as separate energy functions, enabling us to represent both global concepts as well as objects under a unified framework. COMET discovers energy functions through recomposing the input image, which we find captures independent factors without additional supervision. Sample generation in COMET is formulated as an optimization process on underlying energy functions, enabling us to generate images with permuted and composed concepts. Finally, discovered visual concepts in COMET generalize well, enabling us to compose concepts between separate modalities of images as well as with other concepts discovered by a separate instance of COMET trained on a different dataset. Code and data available at https://energy-based-model.github.io/comet/.
The Neural MMO Platform for Massively Multiagent Research
Oct 14, 2021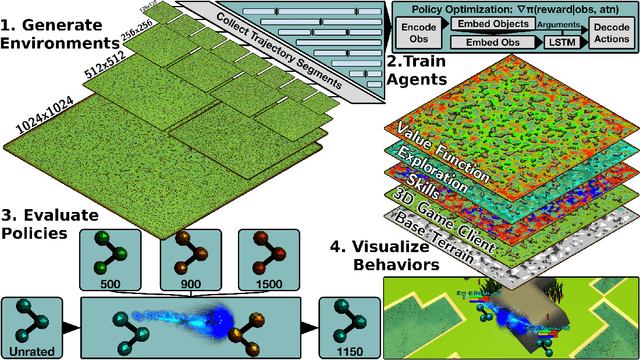
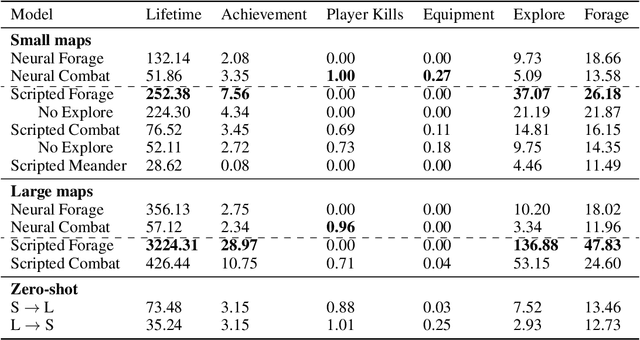


Neural MMO is a computationally accessible research platform that combines large agent populations, long time horizons, open-ended tasks, and modular game systems. Existing environments feature subsets of these properties, but Neural MMO is the first to combine them all. We present Neural MMO as free and open source software with active support, ongoing development, documentation, and additional training, logging, and visualization tools to help users adapt to this new setting. Initial baselines on the platform demonstrate that agents trained in large populations explore more and learn a progression of skills. We raise other more difficult problems such as many-team cooperation as open research questions which Neural MMO is well-suited to answer. Finally, we discuss current limitations of the platform, potential mitigations, and plans for continued development.