 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Scaling Law for Large Language Models
Apr 27, 2024Recently, Large Language Models (LLMs) are widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed as Scaling Laws, have discovered that the loss of LLMs scales as power laws with model size, computational budget, and dataset size. However, the performance of LLMs throughout the training process remains untouched. In this paper, we propose the novel concept of Temporal Scaling Law and study the loss of LLMs from the temporal dimension. We first investigate the imbalance of loss on each token positions and develop a reciprocal-law across model scales and training stages. We then derive the temporal scaling law by studying the temporal patterns of the reciprocal-law parameters. Results on both in-distribution (IID) data and out-of-distribution (OOD) data demonstrate that our temporal scaling law accurately predicts the performance of LLMs in future training stages. Moreover, the temporal scaling law reveals that LLMs learn uniformly on different token positions, despite the loss imbalance. Experiments on pre-training LLMs in various scales show that this phenomenon verifies the default training paradigm for generative language models, in which no re-weighting strategies are attached during training. Overall, the temporal scaling law provides deeper insight into LLM pre-training.
FedSI: Federated Subnetwork Inference for Efficient Uncertainty Quantification
Apr 24, 2024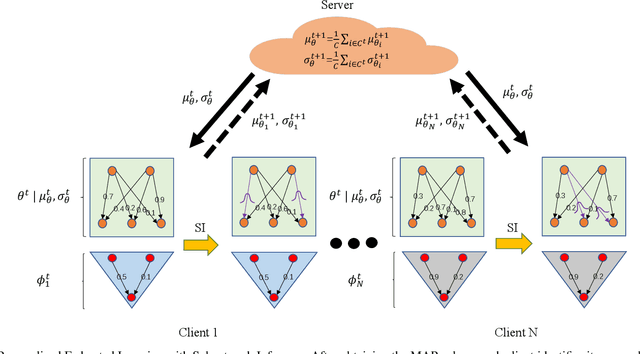
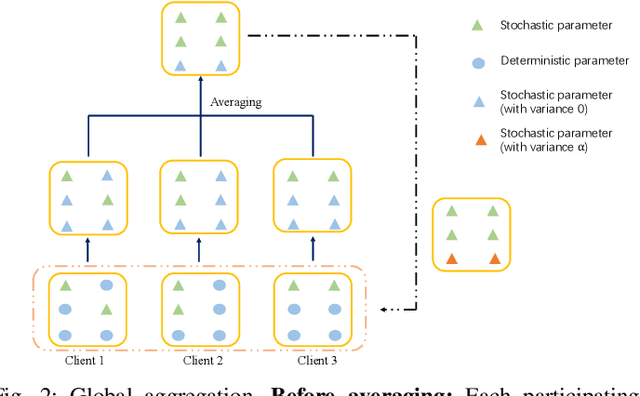
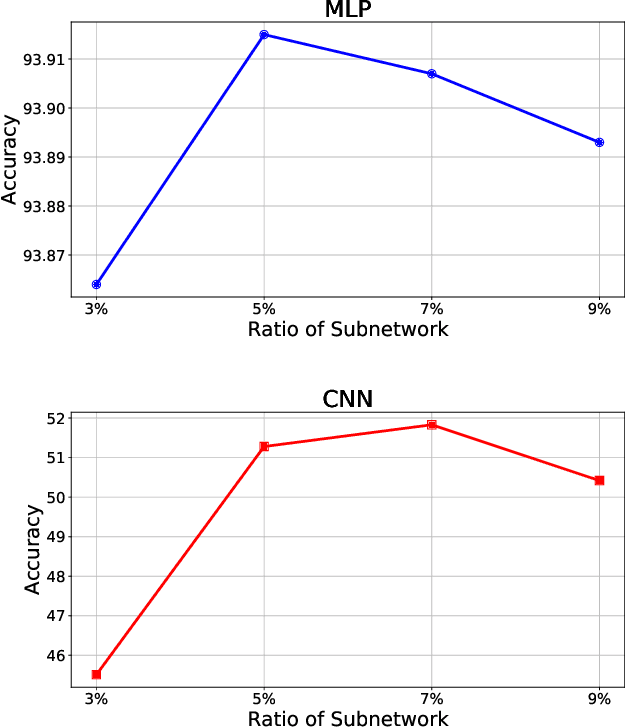
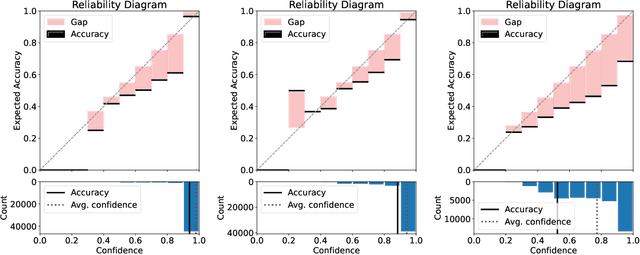
While deep neural networks (DNNs) based personalized federated learning (PFL) is demanding for addressing data heterogeneity and shows promising performance, existing methods for federated learning (FL) suffer from efficient systematic uncertainty quantification. The Bayesian DNNs-based PFL is usually questioned of either over-simplified model structures or high computational and memory costs. In this paper, we introduce FedSI, a novel Bayesian DNNs-based subnetwork inference PFL framework. FedSI is simple and scalable by leveraging Bayesian methods to incorporate systematic uncertainties effectively. It implements a client-specific subnetwork inference mechanism, selects network parameters with large variance to be inferred through posterior distributions, and fixes the rest as deterministic ones. FedSI achieves fast and scalable inference while preserving the systematic uncertainties to the fullest extent. Extensive experiments on three different benchmark datasets demonstrate that FedSI outperforms existing Bayesian and non-Bayesian FL baselines in heterogeneous FL scenarios.
Device-Free 3D Drone Localization in RIS-Assisted mmWave MIMO Networks
Apr 23, 2024



In this paper, we investigate the potential of reconfigurable intelligent surfaces (RISs) in facilitating passive/device-free three-dimensional (3D) drone localization within existing cellular infrastructure operating at millimeter-wave (mmWave) frequencies and employing multiple antennas at the transceivers. The developed localization system operates in the bi-static mode without requiring direct communication between the drone and the base station. We analyze the theoretical performance limits via Fisher information analysis and Cram\'er Rao lower bounds (CRLBs). Furthermore, we develop a low-complexity yet effective drone localization algorithm based on coordinate gradient descent and examine the impact of factors such as radar cross section (RCS) of the drone and training overhead on system performance. It is demonstrated that integrating RIS yields significant benefits over its RIS-free counterpart, as evidenced by both theoretical analyses and numerical simulations.
Integrated Communication, Localization, and Sensing in 6G D-MIMO Networks
Mar 28, 2024



Future generations of mobile networks call for concurrent sensing and communication functionalities in the same hardware and/or spectrum. Compared to communication, sensing services often suffer from limited coverage, due to the high path loss of the reflected signal and the increased infrastructure requirements. To provide a more uniform quality of service, distributed multiple input multiple output (D-MIMO) systems deploy a large number of distributed nodes and efficiently control them, making distributed integrated sensing and communications (ISAC) possible. In this paper, we investigate ISAC in D-MIMO through the lens of different design architectures and deployments, revealing both conflicts and synergies. In addition, simulation and demonstration results reveal both opportunities and challenges towards the implementation of ISAC in D-MIMO.
PYRA: Parallel Yielding Re-Activation for Training-Inference Efficient Task Adaptation
Mar 14, 2024



Recently, the scale of transformers has grown rapidly, which introduces considerable challenges in terms of training overhead and inference efficiency in the scope of task adaptation. Existing works, namely Parameter-Efficient Fine-Tuning (PEFT) and model compression, have separately investigated the challenges. However, PEFT cannot guarantee the inference efficiency of the original backbone, especially for large-scale models. Model compression requires significant training costs for structure searching and re-training. Consequently, a simple combination of them cannot guarantee accomplishing both training efficiency and inference efficiency with minimal costs. In this paper, we propose a novel Parallel Yielding Re-Activation (PYRA) method for such a challenge of training-inference efficient task adaptation. PYRA first utilizes parallel yielding adaptive weights to comprehensively perceive the data distribution in downstream tasks. A re-activation strategy for token modulation is then applied for tokens to be merged, leading to calibrated token features. Extensive experiments demonstrate that PYRA outperforms all competing methods under both low compression rate and high compression rate, demonstrating its effectiveness and superiority in maintaining both training efficiency and inference efficiency for large-scale foundation models. Our code will be released to the public.
Machine Unlearning: Taxonomy, Metrics, Applications, Challenges, and Prospects
Mar 13, 2024Personal digital data is a critical asset, and governments worldwide have enforced laws and regulations to protect data privacy. Data users have been endowed with the right to be forgotten of their data. In the course of machine learning (ML), the forgotten right requires a model provider to delete user data and its subsequent impact on ML models upon user requests. Machine unlearning emerges to address this, which has garnered ever-increasing attention from both industry and academia. While the area has developed rapidly, there is a lack of comprehensive surveys to capture the latest advancements. Recognizing this shortage, we conduct an extensive exploration to map the landscape of machine unlearning including the (fine-grained) taxonomy of unlearning algorithms under centralized and distributed settings, debate on approximate unlearning, verification and evaluation metrics, challenges and solutions for unlearning under different applications, as well as attacks targeting machine unlearning. The survey concludes by outlining potential directions for future research, hoping to serve as a guide for interested scholars.
ELAA Near-Field Localization and Sensing with Partial Blockage Detection
Feb 24, 2024



High-frequency communication systems bring extremely large aperture arrays (ELAA) and large bandwidths, integrating localization and (bi-static) sensing functions without extra infrastructure. Such systems are likely to operate in the near-field (NF), where the performance of localization and sensing is degraded if a simplified far-field channel model is considered. However, when taking advantage of the additional geometry information in the NF, e.g., the encapsulated information in the wavefront, localization and sensing performance can be improved. In this work, we formulate a joint synchronization, localization, and sensing problem in the NF. Considering the array size could be much larger than an obstacle, the effect of partial blockage (i.e., a portion of antennas are blocked) is investigated, and a blockage detection algorithm is proposed. The simulation results show that blockage greatly impacts performance for certain positions, and the proposed blockage detection algorithm can mitigate this impact by identifying the blocked antennas.
INSTRAUG: Automatic Instruction Augmentation for Multimodal Instruction Fine-tuning
Feb 22, 2024Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
Bring Your Own Character: A Holistic Solution for Automatic Facial Animation Generation of Customized Characters
Feb 21, 2024Animating virtual characters has always been a fundamental research problem in virtual reality (VR). Facial animations play a crucial role as they effectively convey emotions and attitudes of virtual humans. However, creating such facial animations can be challenging, as current methods often involve utilization of expensive motion capture devices or significant investments of time and effort from human animators in tuning animation parameters. In this paper, we propose a holistic solution to automatically animate virtual human faces. In our solution, a deep learning model was first trained to retarget the facial expression from input face images to virtual human faces by estimating the blendshape coefficients. This method offers the flexibility of generating animations with characters of different appearances and blendshape topologies. Second, a practical toolkit was developed using Unity 3D, making it compatible with the most popular VR applications. The toolkit accepts both image and video as input to animate the target virtual human faces and enables users to manipulate the animation results. Furthermore, inspired by the spirit of Human-in-the-loop (HITL), we leveraged user feedback to further improve the performance of the model and toolkit, thereby increasing the customization properties to suit user preferences. The whole solution, for which we will make the code public, has the potential to accelerate the generation of facial animations for use in VR applications.
Weakly Augmented Variational Autoencoder in Time Series Anomaly Detection
Jan 07, 2024Due to their unsupervised training and uncertainty estimation, deep Variational Autoencoders (VAEs) have become powerful tools for reconstruction-based Time Series Anomaly Detection (TSAD). Existing VAE-based TSAD methods, either statistical or deep, tune meta-priors to estimate the likelihood probability for effectively capturing spatiotemporal dependencies in the data. However, these methods confront the challenge of inherent data scarcity, which is often the case in anomaly detection tasks. Such scarcity easily leads to latent holes, discontinuous regions in latent space, resulting in non-robust reconstructions on these discontinuous spaces. We propose a novel generative framework that combines VAEs with self-supervised learning (SSL) to address this issue.