 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Massive MIMO with 1-Bit Radio-over-Fiber Fronthaul: Uplink Spectral Efficiency and Power Control
Jun 25, 2026We analyze the uplink spectral efficiency achievable in a distributed multiple-input multiple-output (D-MIMO) architecture employing a 1-bit radio-over-fiber fronthaul. This architecture eliminates the need for local oscillators at the access points, hence enabling coherent-phase transmission without costly over-the-air synchronization. With this fronthaul architecture, the uplink signal at the central processing unit is a dithered, oversampled, and 1-bit quantized version of the passband signal received at the access points. This makes some of the conventional spectral-efficiency expressions used in the D-MIMO literature not directly applicable for two key reasons: the nonlinearity of the input-output relation and the practical unavailability of minimum mean square error (MMSE) channel estimates. To address this issue, we propose novel achievable-rate expressions that do not require MMSE channel estimates and rely on the Bussgang decomposition to linearize the input-output relation. We use these expressions to determine the optimal signal-to-dither ratio (SDR) that maximizes the achievable rates in both single- and multiuser scenarios and to assess the impact of oversampling. We then use one of the proposed achievable-rate expressions to investigate the max-min fairness problem when the access points cannot maintain the optimal SDR because of limitations in their dynamic range.
Online Conformal Compression for Zero-Delay Communication with Distortion Guarantees
Mar 11, 2025We investigate a lossy source compression problem in which both the encoder and decoder are equipped with a pre-trained sequence predictor. We propose an online lossy compression scheme that, under a 0-1 loss distortion function, ensures a deterministic, per-sequence upper bound on the distortion (outage) level for any time instant. The outage guarantees apply irrespective of any assumption on the distribution of the sequences to be encoded or on the quality of the predictor at the encoder and decoder. The proposed method, referred to as online conformal compression (OCC), is built upon online conformal prediction--a novel method for constructing confidence intervals for arbitrary predictors. Numerical results show that OCC achieves a compression rate comparable to that of an idealized scheme in which the encoder, with hindsight, selects the optimal subset of symbols to describe to the decoder, while satisfying the overall outage constraint.
EVM Analysis of Distributed Massive MIMO with 1-Bit Radio-Over-Fiber Fronthaul
May 29, 2024We analyze the uplink performance of a distributed massive multiple-input multiple-output (MIMO) architecture in which the remotely located access points (APs) are connected to a central processing unit via a fiber-optical fronthaul carrying a dithered and 1-bit quantized version of the received radio-frequency (RF) signal. The innovative feature of the proposed architecture is that no down-conversion is performed at the APs. This eliminates the need to equip the APs with local oscillators, which may be difficult to synchronize. Under the assumption that a constraint is imposed on the amount of data that can be exchanged across the fiber-optical fronthaul, we investigate the tradeoff between spatial oversampling, defined in terms of the total number of APs, and temporal oversampling, defined in terms of the oversampling factor selected at the central processing unit, to facilitate the recovery of the transmitted signal from 1-bit samples of the RF received signal. Using the so-called error-vector magnitude (EVM) as performance metric, we shed light on the optimal design of the dither signal, and quantify, for a given number of APs, the minimum fronthaul rate required for our proposed distributed massive MIMO architecture to outperform a standard co-located massive MIMO architecture in terms of EVM.
Timely Status Updates in Slotted ALOHA Network With Energy Harvesting
Apr 29, 2024



We investigate the age of information (AoI) in a scenario where energy-harvesting devices send status updates to a gateway following the slotted ALOHA protocol and receive no feedback. We let the devices adjust the transmission probabilities based on their current battery level. Using a Markovian analysis, we derive analytically the average AoI. We further provide an approximate analysis for accurate and easy-to-compute approximations of both the average AoI and the age-violation probability (AVP), i.e., the probability that the AoI exceeds a given threshold. We also analyze the average throughput. Via numerical results, we investigate two baseline strategies: transmit a new update whenever possible to exploit every opportunity to reduce the AoI, and transmit only when sufficient energy is available to increase the chance of successful decoding. The two strategies are beneficial for low and high update-generation rates, respectively. We show that an optimized policy that balances the two strategies outperforms them significantly in terms of both AoI metrics and throughput. Finally, we show the benefit of decoding multiple packets in a slot using successive interference cancellation and adapting the transmission probability based on both the current battery level and the time elapsed since the last transmission.
Integrated Communication, Localization, and Sensing in 6G D-MIMO Networks
Mar 28, 2024



Future generations of mobile networks call for concurrent sensing and communication functionalities in the same hardware and/or spectrum. Compared to communication, sensing services often suffer from limited coverage, due to the high path loss of the reflected signal and the increased infrastructure requirements. To provide a more uniform quality of service, distributed multiple input multiple output (D-MIMO) systems deploy a large number of distributed nodes and efficiently control them, making distributed integrated sensing and communications (ISAC) possible. In this paper, we investigate ISAC in D-MIMO through the lens of different design architectures and deployments, revealing both conflicts and synergies. In addition, simulation and demonstration results reveal both opportunities and challenges towards the implementation of ISAC in D-MIMO.
Secure Aggregation is Not Private Against Membership Inference Attacks
Mar 26, 2024Secure aggregation (SecAgg) is a commonly-used privacy-enhancing mechanism in federated learning, affording the server access only to the aggregate of model updates while safeguarding the confidentiality of individual updates. Despite widespread claims regarding SecAgg's privacy-preserving capabilities, a formal analysis of its privacy is lacking, making such presumptions unjustified. In this paper, we delve into the privacy implications of SecAgg by treating it as a local differential privacy (LDP) mechanism for each local update. We design a simple attack wherein an adversarial server seeks to discern which update vector a client submitted, out of two possible ones, in a single training round of federated learning under SecAgg. By conducting privacy auditing, we assess the success probability of this attack and quantify the LDP guarantees provided by SecAgg. Our numerical results unveil that, contrary to prevailing claims, SecAgg offers weak privacy against membership inference attacks even in a single training round. Indeed, it is difficult to hide a local update by adding other independent local updates when the updates are of high dimension. Our findings underscore the imperative for additional privacy-enhancing mechanisms, such as noise injection, in federated learning.
A TDD Distributed MIMO Testbed Using a 1-Bit Radio-Over-Fiber Fronthaul Architecture
Mar 26, 2024We present the uplink and downlink of a time-division duplex distributed multiple-input multiple-output (D-MIMO) testbed, based on a 1-bit radio-over-fiber architecture, which is low-cost and scalable. The proposed architecture involves a central unit (CU) that is equipped with 1-bit digital-to-analog and analog-to-digital converters, operating at 10 GS/s. The CU is connected to multiple single-antenna remote radio heads (RRHs) via optical fibers, over which a binary RF waveform is transmitted. In the uplink, a binary RF waveform is generated at the RRHs by a comparator, whose inputs are the received RF signal and a suitably designed dither signal. In the downlink, a binary RF waveform is generated at the CU via bandpass sigma-delta modulation. Our measurement results show that low error-vector magnitude (EVM) can be achieved in both the uplink and the downlink, despite 1-bit sampling at the CU. Specifically, for point-to-point over-cable transmission between a single user equipment (UE) and a CU equipped with a single RRH, we report, for a 10 MBd signal using single-carrier 16QAM modulation, an EVM of 3.3% in the downlink, and of 4.5% in the uplink. We then consider a CU connected to 3 RRHs serving over the air 2 UEs, and show that, after over-the-air reciprocity calibration, a downlink zero-forcing precoder designed on the basis of uplink channel estimates at the CU, achieves an EVM of 6.4% and 10.9% at UE 1 and UE 2, respectively. Finally, we investigate the ability of the proposed architecture to support orthogonal frequency-division multiplexing (OFDM) waveforms, and its robustness against both in-band and out-of-band interference.
Generalization Bounds: Perspectives from Information Theory and PAC-Bayes
Sep 08, 2023A fundamental question in theoretical machine learning is generalization. Over the past decades, the PAC-Bayesian approach has been established as a flexible framework to address the generalization capabilities of machine learning algorithms, and design new ones. Recently, it has garnered increased interest due to its potential applicability for a variety of learning algorithms, including deep neural networks. In parallel, an information-theoretic view of generalization has developed, wherein the relation between generalization and various information measures has been established. This framework is intimately connected to the PAC-Bayesian approach, and a number of results have been independently discovered in both strands. In this monograph, we highlight this strong connection and present a unified treatment of generalization. We present techniques and results that the two perspectives have in common, and discuss the approaches and interpretations that differ. In particular, we demonstrate how many proofs in the area share a modular structure, through which the underlying ideas can be intuited. We pay special attention to the conditional mutual information (CMI) framework; analytical studies of the information complexity of learning algorithms; and the application of the proposed methods to deep learning. This monograph is intended to provide a comprehensive introduction to information-theoretic generalization bounds and their connection to PAC-Bayes, serving as a foundation from which the most recent developments are accessible. It is aimed broadly towards researchers with an interest in generalization and theoretical machine learning.
Evaluated CMI Bounds for Meta Learning: Tightness and Expressiveness
Oct 12, 2022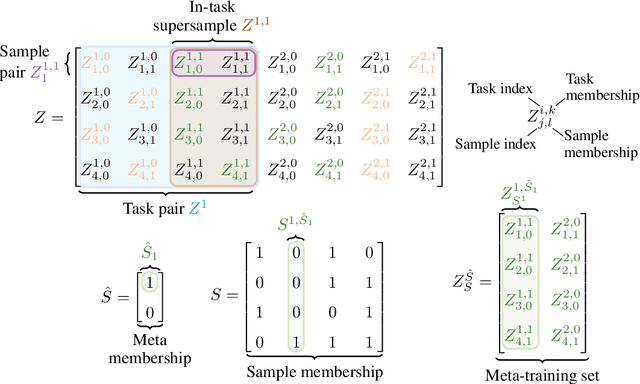
Recent work has established that the conditional mutual information (CMI) framework of Steinke and Zakynthinou (2020) is expressive enough to capture generalization guarantees in terms of algorithmic stability, VC dimension, and related complexity measures for conventional learning (Harutyunyan et al., 2021, Haghifam et al., 2021). Hence, it provides a unified method for establishing generalization bounds. In meta learning, there has so far been a divide between information-theoretic results and results from classical learning theory. In this work, we take a first step toward bridging this divide. Specifically, we present novel generalization bounds for meta learning in terms of the evaluated CMI (e-CMI). To demonstrate the expressiveness of the e-CMI framework, we apply our bounds to a representation learning setting, with $n$ samples from $\hat n$ tasks parameterized by functions of the form $f_i \circ h$. Here, each $f_i \in \mathcal F$ is a task-specific function, and $h \in \mathcal H$ is the shared representation. For this setup, we show that the e-CMI framework yields a bound that scales as $\sqrt{ \mathcal C(\mathcal H)/(n\hat n) + \mathcal C(\mathcal F)/n} $, where $\mathcal C(\cdot)$ denotes a complexity measure of the hypothesis class. This scaling behavior coincides with the one reported in Tripuraneni et al. (2020) using Gaussian complexity.
A New Family of Generalization Bounds Using Samplewise Evaluated CMI
Oct 12, 2022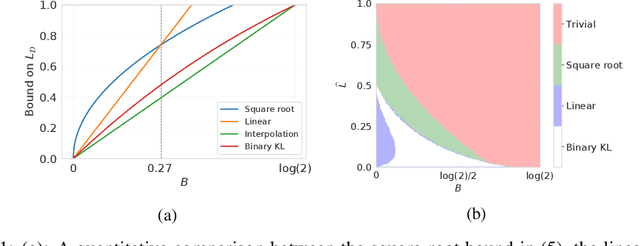

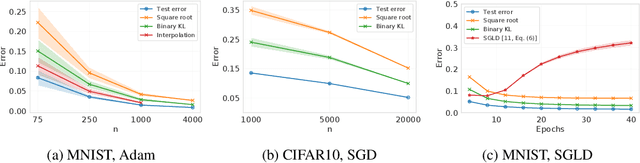
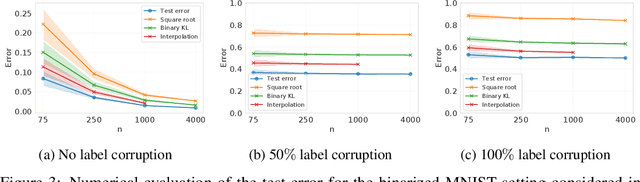
We present a new family of information-theoretic generalization bounds, in which the training loss and the population loss are compared through a jointly convex function. This function is upper-bounded in terms of the disintegrated, samplewise, evaluated conditional mutual information (CMI), an information measure that depends on the losses incurred by the selected hypothesis, rather than on the hypothesis itself, as is common in probably approximately correct (PAC)-Bayesian results. We demonstrate the generality of this framework by recovering and extending previously known information-theoretic bounds. Furthermore, using the evaluated CMI, we derive a samplewise, average version of Seeger's PAC-Bayesian bound, where the convex function is the binary KL divergence. In some scenarios, this novel bound results in a tighter characterization of the population loss of deep neural networks than previous bounds. Finally, we derive high-probability versions of some of these average bounds. We demonstrate the unifying nature of the evaluated CMI bounds by using them to recover average and high-probability generalization bounds for multiclass classification with finite Natarajan dimension.