 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Once, Deploy Anywhere: Realize Data-Efficient Dynamic Object Manipulation
Aug 19, 2025Realizing generalizable dynamic object manipulation is important for enhancing manufacturing efficiency, as it eliminates specialized engineering for various scenarios. To this end, imitation learning emerges as a promising paradigm, leveraging expert demonstrations to teach a policy manipulation skills. Although the generalization of an imitation learning policy can be improved by increasing demonstrations, demonstration collection is labor-intensive. To address this problem, this paper investigates whether strong generalization in dynamic object manipulation is achievable with only a few demonstrations. Specifically, we develop an entropy-based theoretical framework to quantify the optimization of imitation learning. Based on this framework, we propose a system named Generalizable Entropy-based Manipulation (GEM). Extensive experiments in simulated and real tasks demonstrate that GEM can generalize across diverse environment backgrounds, robot embodiments, motion dynamics, and object geometries. Notably, GEM has been deployed in a real canteen for tableware collection. Without any in-scene demonstration, it achieves a success rate of over 97% across more than 10,000 operations.
BOOD: Boundary-based Out-Of-Distribution Data Generation
Aug 01, 2025


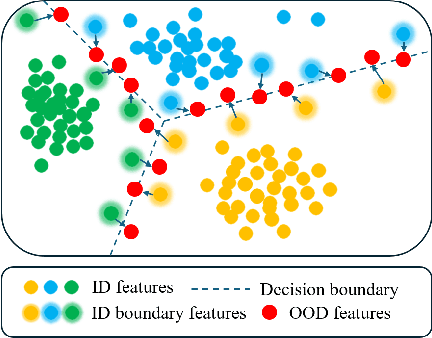
Harnessing the power of diffusion models to synthesize auxiliary training data based on latent space features has proven effective in enhancing out-of-distribution (OOD) detection performance. However, extracting effective features outside the in-distribution (ID) boundary in latent space remains challenging due to the difficulty of identifying decision boundaries between classes. This paper proposes a novel framework called Boundary-based Out-Of-Distribution data generation (BOOD), which synthesizes high-quality OOD features and generates human-compatible outlier images using diffusion models. BOOD first learns a text-conditioned latent feature space from the ID dataset, selects ID features closest to the decision boundary, and perturbs them to cross the decision boundary to form OOD features. These synthetic OOD features are then decoded into images in pixel space by a diffusion model. Compared to previous works, BOOD provides a more training efficient strategy for synthesizing informative OOD features, facilitating clearer distinctions between ID and OOD data. Extensive experimental results on common benchmarks demonstrate that BOOD surpasses the state-of-the-art method significantly, achieving a 29.64% decrease in average FPR95 (40.31% vs. 10.67%) and a 7.27% improvement in average AUROC (90.15% vs. 97.42%) on the CIFAR-100 dataset.
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Jul 17, 2025Recent advancements in vision-language models (VLMs) have improved performance by increasing the number of visual tokens, which are often significantly longer than text tokens. However, we observe that most real-world scenarios do not require such an extensive number of visual tokens. While the performance drops significantly in a small subset of OCR-related tasks, models still perform accurately in most other general VQA tasks with only 1/4 resolution. Therefore, we propose to dynamically process distinct samples with different resolutions, and present a new paradigm for visual token compression, namely, VisionThink. It starts with a downsampled image and smartly decides whether it is sufficient for problem solving. Otherwise, the model could output a special token to request the higher-resolution image. Compared to existing Efficient VLM methods that compress tokens using fixed pruning ratios or thresholds, VisionThink autonomously decides whether to compress tokens case by case. As a result, it demonstrates strong fine-grained visual understanding capability on OCR-related tasks, and meanwhile saves substantial visual tokens on simpler tasks. We adopt reinforcement learning and propose the LLM-as-Judge strategy to successfully apply RL to general VQA tasks. Moreover, we carefully design a reward function and penalty mechanism to achieve a stable and reasonable image resize call ratio. Extensive experiments demonstrate the superiority, efficiency, and effectiveness of our method. Our code is available at https://github.com/dvlab-research/VisionThink.
DreamComposer++: Empowering Diffusion Models with Multi-View Conditions for 3D Content Generation
Jul 03, 2025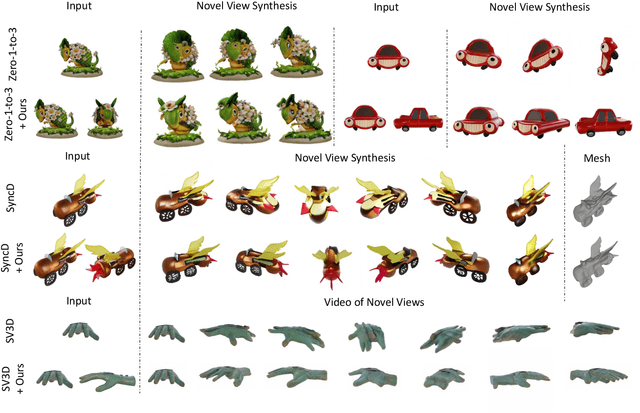
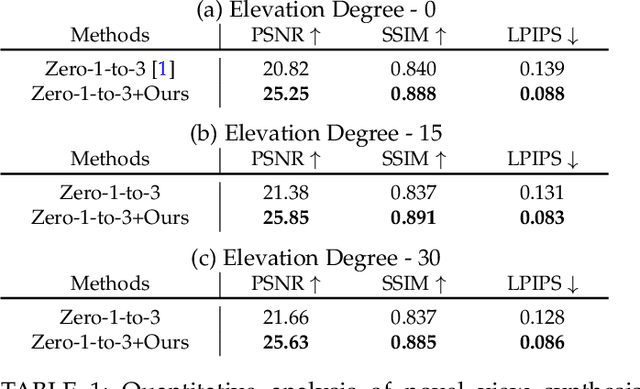
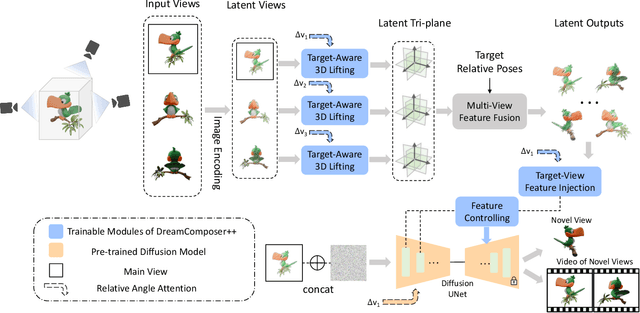

Recent advancements in leveraging pre-trained 2D diffusion models achieve the generation of high-quality novel views from a single in-the-wild image. However, existing works face challenges in producing controllable novel views due to the lack of information from multiple views. In this paper, we present DreamComposer++, a flexible and scalable framework designed to improve current view-aware diffusion models by incorporating multi-view conditions. Specifically, DreamComposer++ utilizes a view-aware 3D lifting module to extract 3D representations of an object from various views. These representations are then aggregated and rendered into the latent features of target view through the multi-view feature fusion module. Finally, the obtained features of target view are integrated into pre-trained image or video diffusion models for novel view synthesis. Experimental results demonstrate that DreamComposer++ seamlessly integrates with cutting-edge view-aware diffusion models and enhances their abilities to generate controllable novel views from multi-view conditions. This advancement facilitates controllable 3D object reconstruction and enables a wide range of applications.
LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans
Jul 03, 2025
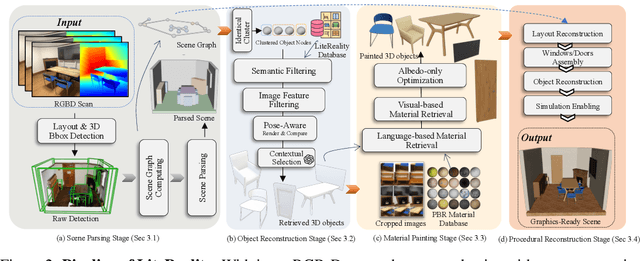
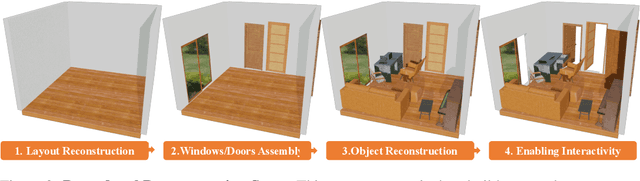
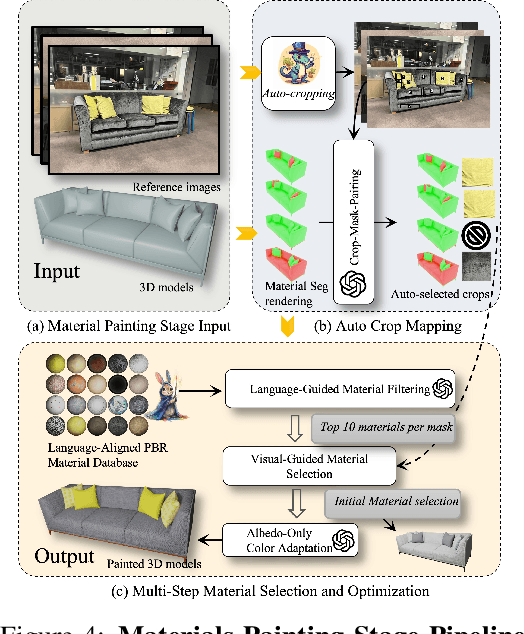
We propose LiteReality, a novel pipeline that converts RGB-D scans of indoor environments into compact, realistic, and interactive 3D virtual replicas. LiteReality not only reconstructs scenes that visually resemble reality but also supports key features essential for graphics pipelines -- such as object individuality, articulation, high-quality physically based rendering materials, and physically based interaction. At its core, LiteReality first performs scene understanding and parses the results into a coherent 3D layout and objects with the help of a structured scene graph. It then reconstructs the scene by retrieving the most visually similar 3D artist-crafted models from a curated asset database. Next, the Material Painting module enhances realism by recovering high-quality, spatially varying materials. Finally, the reconstructed scene is integrated into a simulation engine with basic physical properties to enable interactive behavior. The resulting scenes are compact, editable, and fully compatible with standard graphics pipelines, making them suitable for applications in AR/VR, gaming, robotics, and digital twins. In addition, LiteReality introduces a training-free object retrieval module that achieves state-of-the-art similarity performance on the Scan2CAD benchmark, along with a robust material painting module capable of transferring appearances from images of any style to 3D assets -- even under severe misalignment, occlusion, and poor lighting. We demonstrate the effectiveness of LiteReality on both real-life scans and public datasets. Project page: https://litereality.github.io; Video: https://www.youtube.com/watch?v=ecK9m3LXg2c
Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
Jul 03, 2025Video generation models have demonstrated remarkable performance, yet their broader adoption remains constrained by slow inference speeds and substantial computational costs, primarily due to the iterative nature of the denoising process. Addressing this bottleneck is essential for democratizing advanced video synthesis technologies and enabling their integration into real-world applications. This work proposes EasyCache, a training-free acceleration framework for video diffusion models. EasyCache introduces a lightweight, runtime-adaptive caching mechanism that dynamically reuses previously computed transformation vectors, avoiding redundant computations during inference. Unlike prior approaches, EasyCache requires no offline profiling, pre-computation, or extensive parameter tuning. We conduct comprehensive studies on various large-scale video generation models, including OpenSora, Wan2.1, and HunyuanVideo. Our method achieves leading acceleration performance, reducing inference time by up to 2.1-3.3$\times$ compared to the original baselines while maintaining high visual fidelity with a significant up to 36% PSNR improvement compared to the previous SOTA method. This improvement makes our EasyCache a efficient and highly accessible solution for high-quality video generation in both research and practical applications. The code is available at https://github.com/H-EmbodVis/EasyCache.
FocalClick-XL: Towards Unified and High-quality Interactive Segmentation
Jun 17, 2025Interactive segmentation enables users to extract binary masks of target objects through simple interactions such as clicks, scribbles, and boxes. However, existing methods often support only limited interaction forms and struggle to capture fine details. In this paper, we revisit the classical coarse-to-fine design of FocalClick and introduce significant extensions. Inspired by its multi-stage strategy, we propose a novel pipeline, FocalClick-XL, to address these challenges simultaneously. Following the emerging trend of large-scale pretraining, we decompose interactive segmentation into meta-tasks that capture different levels of information -- context, object, and detail -- assigning a dedicated subnet to each level.This decomposition allows each subnet to undergo scaled pretraining with independent data and supervision, maximizing its effectiveness. To enhance flexibility, we share context- and detail-level information across different interaction forms as common knowledge while introducing a prompting layer at the object level to encode specific interaction types. As a result, FocalClick-XL achieves state-of-the-art performance on click-based benchmarks and demonstrates remarkable adaptability to diverse interaction formats, including boxes, scribbles, and coarse masks. Beyond binary mask generation, it is also capable of predicting alpha mattes with fine-grained details, making it a versatile and powerful tool for interactive segmentation.
TGDPO: Harnessing Token-Level Reward Guidance for Enhancing Direct Preference Optimization
Jun 17, 2025Recent advancements in reinforcement learning from human feedback have shown that utilizing fine-grained token-level reward models can substantially enhance the performance of Proximal Policy Optimization (PPO) in aligning large language models. However, it is challenging to leverage such token-level reward as guidance for Direct Preference Optimization (DPO), since DPO is formulated as a sequence-level bandit problem. To address this challenge, this work decomposes the sequence-level PPO into a sequence of token-level proximal policy optimization problems and then frames the problem of token-level PPO with token-level reward guidance, from which closed-form optimal token-level policy and the corresponding token-level reward can be derived. Using the obtained reward and Bradley-Terry model, this work establishes a framework of computable loss functions with token-level reward guidance for DPO, and proposes a practical reward guidance based on the induced DPO reward. This formulation enables different tokens to exhibit varying degrees of deviation from reference policy based on their respective rewards. Experiment results demonstrate that our method achieves substantial performance improvements over DPO, with win rate gains of up to 7.5 points on MT-Bench, 6.2 points on AlpacaEval 2, and 4.3 points on Arena-Hard. Code is available at https://github.com/dvlab-research/TGDPO.
PlayerOne: Egocentric World Simulator
Jun 11, 2025We introduce PlayerOne, the first egocentric realistic world simulator, facilitating immersive and unrestricted exploration within vividly dynamic environments. Given an egocentric scene image from the user, PlayerOne can accurately construct the corresponding world and generate egocentric videos that are strictly aligned with the real scene human motion of the user captured by an exocentric camera. PlayerOne is trained in a coarse-to-fine pipeline that first performs pretraining on large-scale egocentric text-video pairs for coarse-level egocentric understanding, followed by finetuning on synchronous motion-video data extracted from egocentric-exocentric video datasets with our automatic construction pipeline. Besides, considering the varying importance of different components, we design a part-disentangled motion injection scheme, enabling precise control of part-level movements. In addition, we devise a joint reconstruction framework that progressively models both the 4D scene and video frames, ensuring scene consistency in the long-form video generation. Experimental results demonstrate its great generalization ability in precise control of varying human movements and worldconsistent modeling of diverse scenarios. It marks the first endeavor into egocentric real-world simulation and can pave the way for the community to delve into fresh frontiers of world modeling and its diverse applications.
LayerFlow: A Unified Model for Layer-aware Video Generation
Jun 04, 2025We present LayerFlow, a unified solution for layer-aware video generation. Given per-layer prompts, LayerFlow generates videos for the transparent foreground, clean background, and blended scene. It also supports versatile variants like decomposing a blended video or generating the background for the given foreground and vice versa. Starting from a text-to-video diffusion transformer, we organize the videos for different layers as sub-clips, and leverage layer embeddings to distinguish each clip and the corresponding layer-wise prompts. In this way, we seamlessly support the aforementioned variants in one unified framework. For the lack of high-quality layer-wise training videos, we design a multi-stage training strategy to accommodate static images with high-quality layer annotations. Specifically, we first train the model with low-quality video data. Then, we tune a motion LoRA to make the model compatible with static frames. Afterward, we train the content LoRA on the mixture of image data with high-quality layered images along with copy-pasted video data. During inference, we remove the motion LoRA thus generating smooth videos with desired layers.