 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-Flow: Speech Enhancement Robust to Multiple Distortions based on Flow Matching in Latent Space and Diffusion Transformers
Mar 23, 2026Recent advances in generative models, such as diffusion and flow matching, have shown strong performance in audio tasks. However, speech enhancement (SE) models are typically trained on limited datasets and evaluated under narrow conditions, limiting real-world applicability. To address this, we propose DiT-Flow, a flow matching-based SE framework built on the latent Diffusion Transformer (DiT) backbone and trained for robustness across diverse distortions, including noise, reverberation, and compression. DiT-Flow operates on compact variational auto-encoders (VAEs)-derived latent features. We validated our approach on StillSonicSet, a synthetic yet acoustically realistic dataset composed of LibriSpeech, FSD50K, FMA, and 90 Matterport3D scenes. Experiments show that DiT-Flow consistently outperforms state-of-the-art generative SE models, demonstrating the effectiveness of flow matching in multi-condition speech enhancement. Despite ongoing efforts to expand synthetic data realism, a persistent bottleneck in SE is the inevitable mismatch between training and deployment conditions. By integrating LoRA with the MoE framework, we achieve both parameter-efficient and high-performance training for DiT-Flow robust to multiple distortions with using 4.9% percentage of the total parameters to obtain a better performance on five unseen distortions.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 28, 2022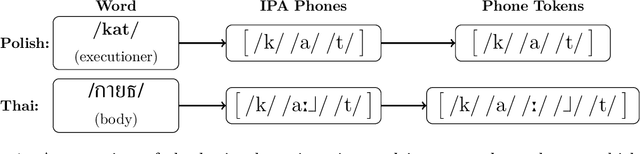
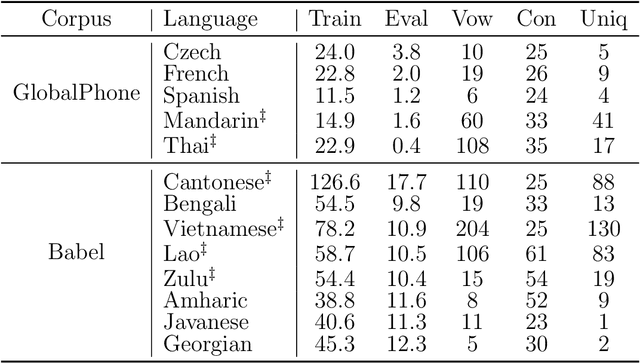
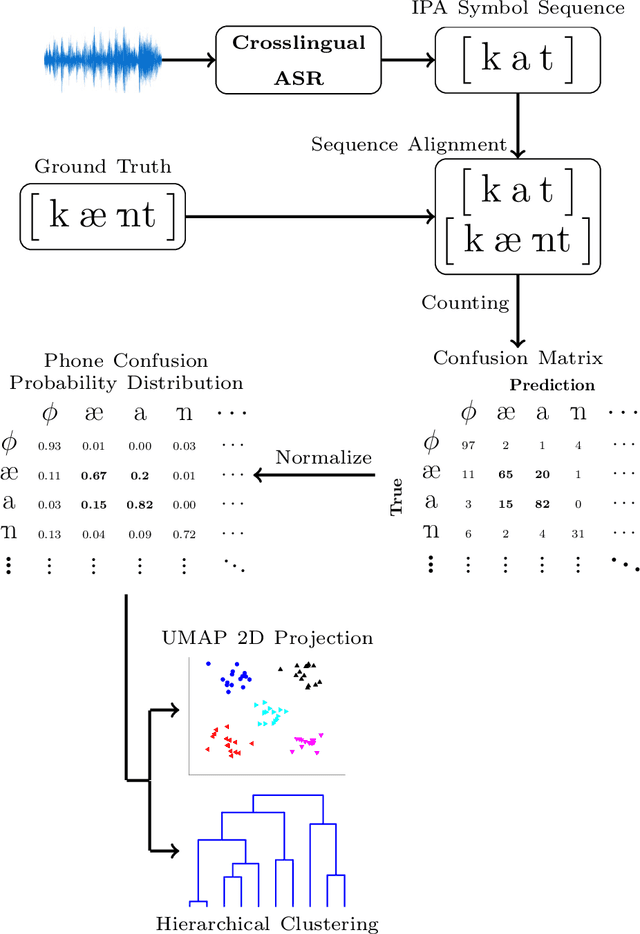
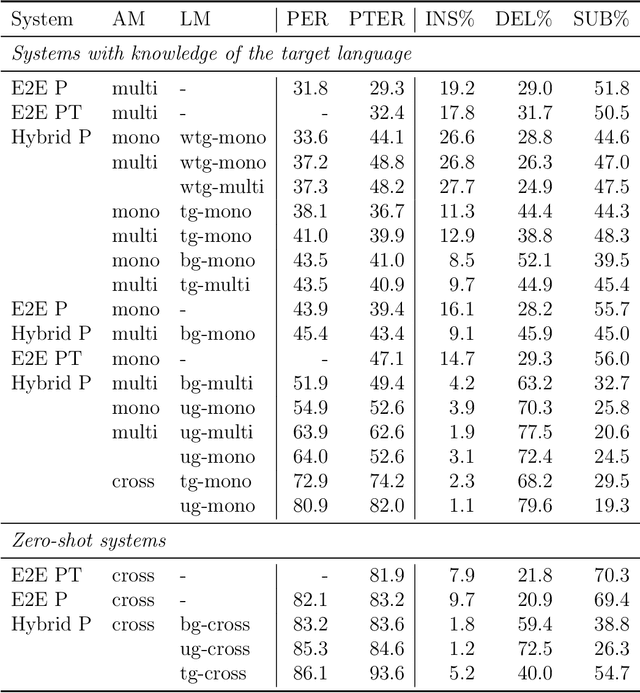
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.