 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Quantifying Speaker Embedding Phonological Rule Interactions in Accented Speech Synthesis
Jan 20, 2026Many spoken languages, including English, exhibit wide variation in dialects and accents, making accent control an important capability for flexible text-to-speech (TTS) models. Current TTS systems typically generate accented speech by conditioning on speaker embeddings associated with specific accents. While effective, this approach offers limited interpretability and controllability, as embeddings also encode traits such as timbre and emotion. In this study, we analyze the interaction between speaker embeddings and linguistically motivated phonological rules in accented speech synthesis. Using American and British English as a case study, we implement rules for flapping, rhoticity, and vowel correspondences. We propose the phoneme shift rate (PSR), a novel metric quantifying how strongly embeddings preserve or override rule-based transformations. Experiments show that combining rules with embeddings yields more authentic accents, while embeddings can attenuate or overwrite rules, revealing entanglement between accent and speaker identity. Our findings highlight rules as a lever for accent control and a framework for evaluating disentanglement in speech generation.
Interpretable Modeling of Articulatory Temporal Dynamics from real-time MRI for Phoneme Recognition
Sep 19, 2025



Real-time Magnetic Resonance Imaging (rtMRI) visualizes vocal tract action, offering a comprehensive window into speech articulation. However, its signals are high dimensional and noisy, hindering interpretation. We investigate compact representations of spatiotemporal articulatory dynamics for phoneme recognition from midsagittal vocal tract rtMRI videos. We compare three feature types: (1) raw video, (2) optical flow, and (3) six linguistically-relevant regions of interest (ROIs) for articulator movements. We evaluate models trained independently on each representation, as well as multi-feature combinations. Results show that multi-feature models consistently outperform single-feature baselines, with the lowest phoneme error rate (PER) of 0.34 obtained by combining ROI and raw video. Temporal fidelity experiments demonstrate a reliance on fine-grained articulatory dynamics, while ROI ablation studies reveal strong contributions from tongue and lips. Our findings highlight how rtMRI-derived features provide accuracy and interpretability, and establish strategies for leveraging articulatory data in speech processing.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025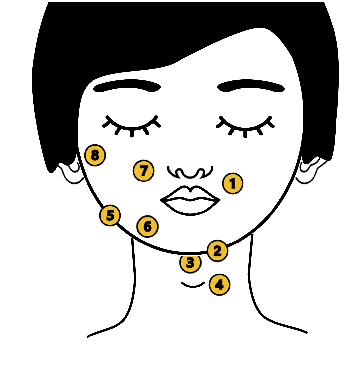

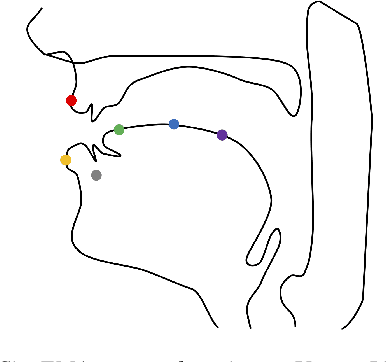
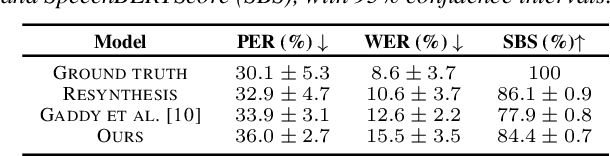
We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.
A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images
Feb 16, 2021
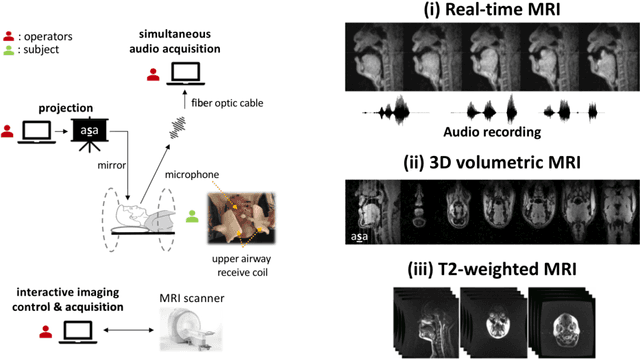
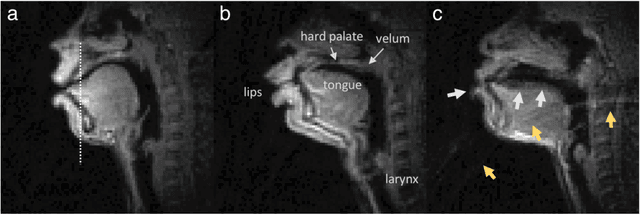
Real-time magnetic resonance imaging (RT-MRI) of human speech production is enabling significant advances in speech science, linguistics, bio-inspired speech technology development, and clinical applications. Easy access to RT-MRI is however limited, and comprehensive datasets with broad access are needed to catalyze research across numerous domains. The imaging of the rapidly moving articulators and dynamic airway shaping during speech demands high spatio-temporal resolution and robust reconstruction methods. Further, while reconstructed images have been published, to-date there is no open dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. Such datasets could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically-relevant biomarkers. The present dataset offers a unique corpus of 2D sagittal-view RT-MRI videos along with synchronized audio for 75 subjects performing linguistically motivated speech tasks, alongside the corresponding first-ever public domain raw RT-MRI data. The dataset also includes 3D volumetric vocal tract MRI during sustained speech sounds and high-resolution static anatomical T2-weighted upper airway MRI for each subject.