 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiral RoPE: Rotate Your Rotary Positional Embeddings in the 2D Plane
Feb 03, 2026Rotary Position Embedding (RoPE) is the de facto positional encoding in large language models due to its ability to encode relative positions and support length extrapolation. When adapted to vision transformers, the standard axial formulation decomposes two-dimensional spatial positions into horizontal and vertical components, implicitly restricting positional encoding to axis-aligned directions. We identify this directional constraint as a fundamental limitation of the standard axial 2D RoPE, which hinders the modeling of oblique spatial relationships that naturally exist in natural images. To overcome this limitation, we propose Spiral RoPE, a simple yet effective extension that enables multi-directional positional encoding by partitioning embedding channels into multiple groups associated with uniformly distributed directions. Each group is rotated according to the projection of the patch position onto its corresponding direction, allowing spatial relationships to be encoded beyond the horizontal and vertical axes. Across a wide range of vision tasks including classification, segmentation, and generation, Spiral RoPE consistently improves performance. Qualitative analysis of attention maps further show that Spiral RoPE exhibits more concentrated activations on semantically relevant objects and better respects local object boundaries, highlighting the importance of multi-directional positional encoding in vision transformers.
MME-RAG: Multi-Manager-Expert Retrieval-Augmented Generation for Fine-Grained Entity Recognition in Task-Oriented Dialogues
Nov 15, 2025Fine-grained entity recognition is crucial for reasoning and decision-making in task-oriented dialogues, yet current large language models (LLMs) continue to face challenges in domain adaptation and retrieval controllability. We introduce MME-RAG, a Multi-Manager-Expert Retrieval-Augmented Generation framework that decomposes entity recognition into two coordinated stages: type-level judgment by lightweight managers and span-level extraction by specialized experts. Each expert is supported by a KeyInfo retriever that injects semantically aligned, few-shot exemplars during inference, enabling precise and domain-adaptive extraction without additional training. Experiments on CrossNER, MIT-Movie, MIT-Restaurant, and our newly constructed multi-domain customer-service dataset demonstrate that MME-RAG performs better than recent baselines in most domains. Ablation studies further show that both the hierarchical decomposition and KeyInfo-guided retrieval are key drivers of robustness and cross-domain generalization, establishing MME-RAG as a scalable and interpretable solution for adaptive dialogue understanding.
When Deepfake Detection Meets Graph Neural Network:a Unified and Lightweight Learning Framework
Aug 07, 2025The proliferation of generative video models has made detecting AI-generated and manipulated videos an urgent challenge. Existing detection approaches often fail to generalize across diverse manipulation types due to their reliance on isolated spatial, temporal, or spectral information, and typically require large models to perform well. This paper introduces SSTGNN, a lightweight Spatial-Spectral-Temporal Graph Neural Network framework that represents videos as structured graphs, enabling joint reasoning over spatial inconsistencies, temporal artifacts, and spectral distortions. SSTGNN incorporates learnable spectral filters and temporal differential modeling into a graph-based architecture, capturing subtle manipulation traces more effectively. Extensive experiments on diverse benchmark datasets demonstrate that SSTGNN not only achieves superior performance in both in-domain and cross-domain settings, but also offers strong robustness against unseen manipulations. Remarkably, SSTGNN accomplishes these results with up to 42.4$\times$ fewer parameters than state-of-the-art models, making it highly lightweight and scalable for real-world deployment.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
IDA-Bench: Evaluating LLMs on Interactive Guided Data Analysis
May 23, 2025Large Language Models (LLMs) show promise as data analysis agents, but existing benchmarks overlook the iterative nature of the field, where experts' decisions evolve with deeper insights of the dataset. To address this, we introduce IDA-Bench, a novel benchmark evaluating LLM agents in multi-round interactive scenarios. Derived from complex Kaggle notebooks, tasks are presented as sequential natural language instructions by an LLM-simulated user. Agent performance is judged by comparing its final numerical output to the human-derived baseline. Initial results show that even state-of-the-art coding agents (like Claude-3.7-thinking) succeed on < 50% of the tasks, highlighting limitations not evident in single-turn tests. This work underscores the need to improve LLMs' multi-round capabilities for building more reliable data analysis agents, highlighting the necessity of achieving a balance between instruction following and reasoning.
MAIN: Mutual Alignment Is Necessary for instruction tuning
Apr 17, 2025Instruction tuning has enabled large language models (LLMs) to achieve remarkable performance, but its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that high-quality instruction-response pairs are not defined by the individual quality of each component, but by the extent of their alignment with each other. To address this, we propose a Mutual Alignment Framework (MAIN) that ensures coherence between the instruction and response through mutual constraints. Experiments demonstrate that models such as LLaMA and Mistral, fine-tuned within this framework, outperform traditional methods across multiple benchmarks. This approach underscores the critical role of instruction-response alignment in enabling scalable and high-quality instruction tuning for LLMs.
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
Mar 03, 2025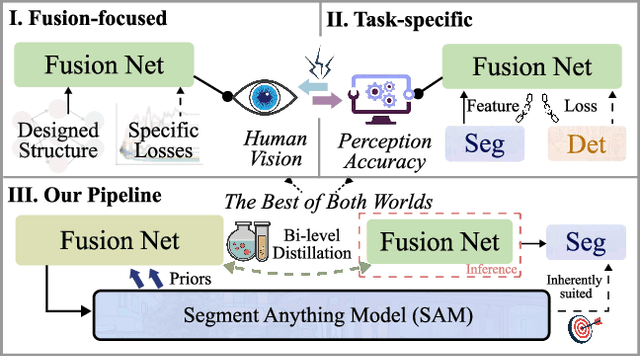
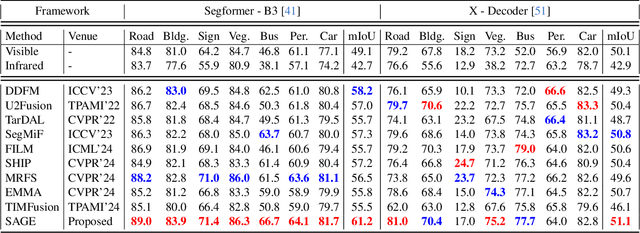

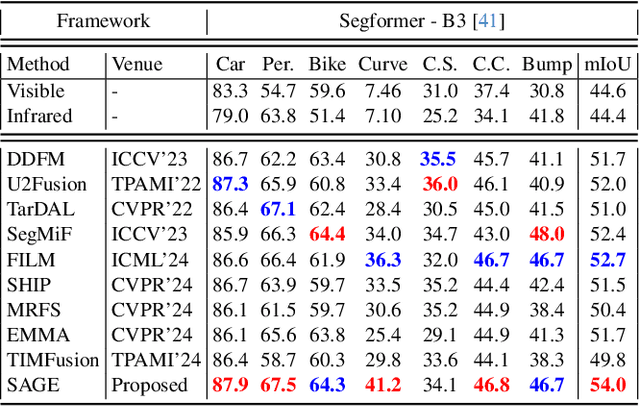
Multi-modality image fusion, particularly infrared and visible image fusion, plays a crucial role in integrating diverse modalities to enhance scene understanding. Early research primarily focused on visual quality, yet challenges remain in preserving fine details, making it difficult to adapt to subsequent tasks. Recent approaches have shifted towards task-specific design, but struggle to achieve the ``The Best of Both Worlds'' due to inconsistent optimization goals. To address these issues, we propose a novel method that leverages the semantic knowledge from the Segment Anything Model (SAM) to Grow the quality of fusion results and Establish downstream task adaptability, namely SAGE. Specifically, we design a Semantic Persistent Attention (SPA) Module that efficiently maintains source information via the persistent repository while extracting high-level semantic priors from SAM. More importantly, to eliminate the impractical dependence on SAM during inference, we introduce a bi-level optimization-driven distillation mechanism with triplet losses, which allow the student network to effectively extract knowledge at the feature, pixel, and contrastive semantic levels, thereby removing reliance on the cumbersome SAM model. Extensive experiments show that our method achieves a balance between high-quality visual results and downstream task adaptability while maintaining practical deployment efficiency.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
GeAR: Generation Augmented Retrieval
Jan 06, 2025



Document retrieval techniques form the foundation for the development of large-scale information systems. The prevailing methodology is to construct a bi-encoder and compute the semantic similarity. However, such scalar similarity is difficult to reflect enough information and impedes our comprehension of the retrieval results. In addition, this computational process mainly emphasizes the global semantics and ignores the fine-grained semantic relationship between the query and the complex text in the document. In this paper, we propose a new method called $\textbf{Ge}$neration $\textbf{A}$ugmented $\textbf{R}$etrieval ($\textbf{GeAR}$) that incorporates well-designed fusion and decoding modules. This enables GeAR to generate the relevant text from documents based on the fused representation of the query and the document, thus learning to "focus on" the fine-grained information. Also when used as a retriever, GeAR does not add any computational burden over bi-encoders. To support the training of the new framework, we have introduced a pipeline to efficiently synthesize high-quality data by utilizing large language models. GeAR exhibits competitive retrieval and localization performance across diverse scenarios and datasets. Moreover, the qualitative analysis and the results generated by GeAR provide novel insights into the interpretation of retrieval results. The code, data, and models will be released after completing technical review to facilitate future research.
Structured Diffusion Models with Mixture of Gaussians as Prior Distribution
Oct 24, 2024



We propose a class of structured diffusion models, in which the prior distribution is chosen as a mixture of Gaussians, rather than a standard Gaussian distribution. The specific mixed Gaussian distribution, as prior, can be chosen to incorporate certain structured information of the data. We develop a simple-to-implement training procedure that smoothly accommodates the use of mixed Gaussian as prior. Theory is provided to quantify the benefits of our proposed models, compared to the classical diffusion models. Numerical experiments with synthetic, image and operational data are conducted to show comparative advantages of our model. Our method is shown to be robust to mis-specifications and in particular suits situations where training resources are limited or faster training in real time is desired.