 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022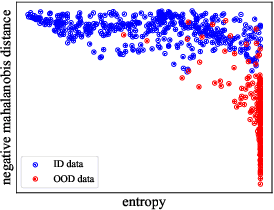
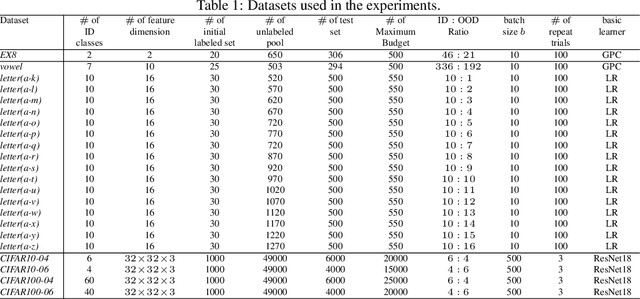
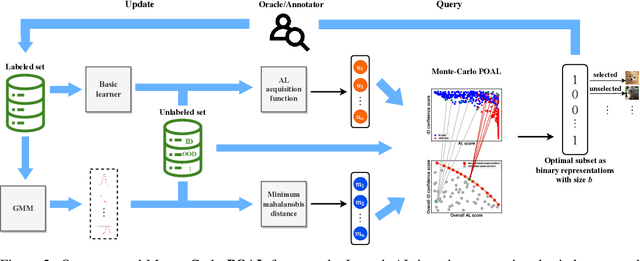
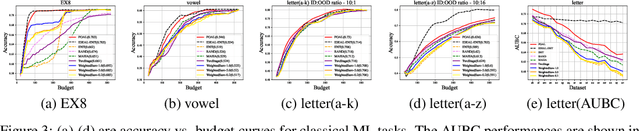
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
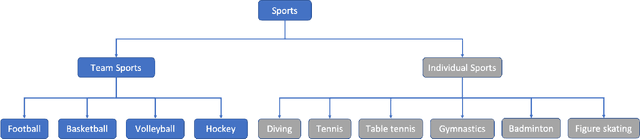
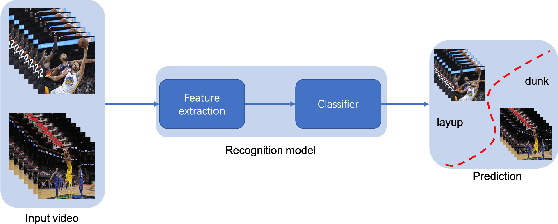
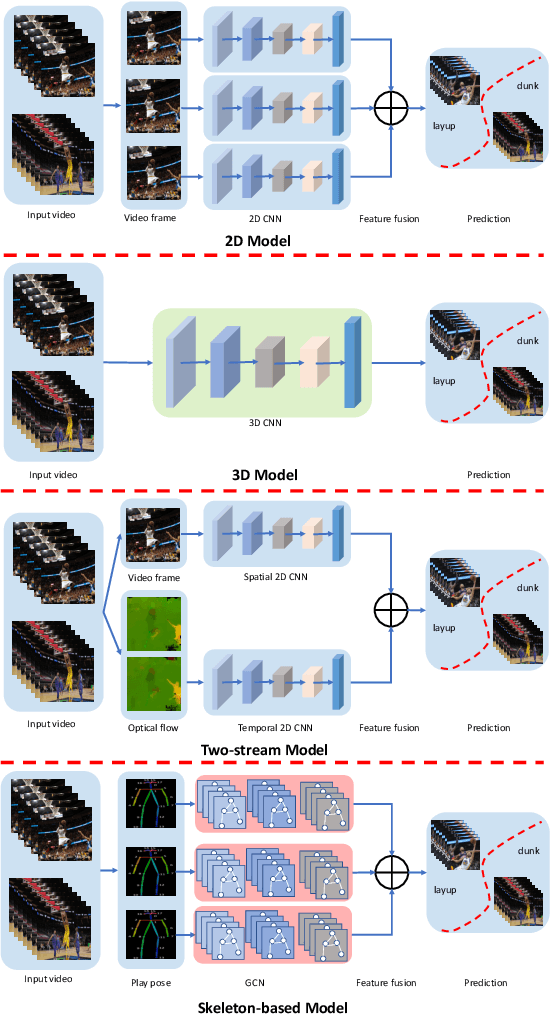
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Practical Strategies of Active Learning to Rank for Web Search
May 20, 2022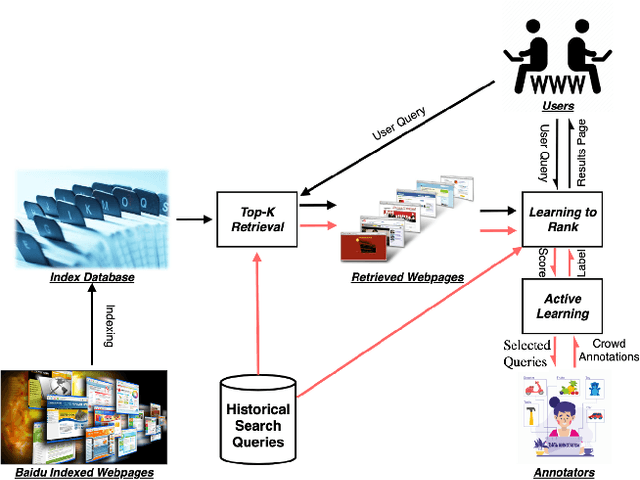
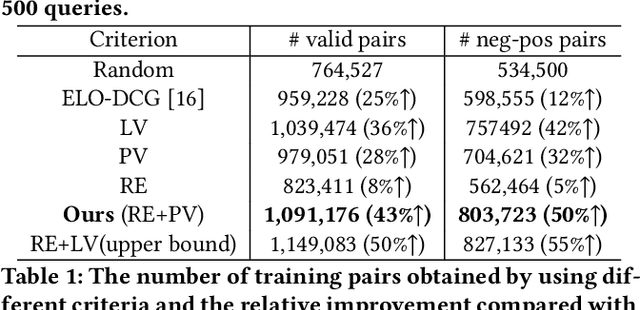
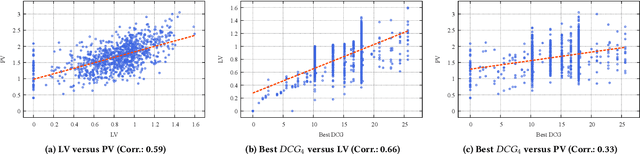
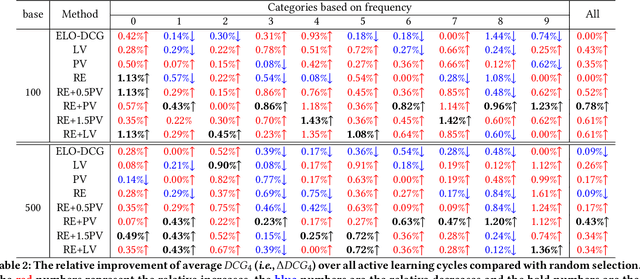
While China has become the biggest online market in the world with around 1 billion internet users, Baidu runs the world largest Chinese search engine serving more than hundreds of millions of daily active users and responding billions queries per day. To handle the diverse query requests from users at web-scale, Baidu has done tremendous efforts in understanding users' queries, retrieve relevant contents from a pool of trillions of webpages, and rank the most relevant webpages on the top of results. Among these components used in Baidu search, learning to rank (LTR) plays a critical role and we need to timely label an extremely large number of queries together with relevant webpages to train and update the online LTR models. To reduce the costs and time consumption of queries/webpages labeling, we study the problem of Activ Learning to Rank (active LTR) that selects unlabeled queries for annotation and training in this work. Specifically, we first investigate the criterion -- Ranking Entropy (RE) characterizing the entropy of relevant webpages under a query produced by a sequence of online LTR models updated by different checkpoints, using a Query-By-Committee (QBC) method. Then, we explore a new criterion namely Prediction Variances (PV) that measures the variance of prediction results for all relevant webpages under a query. Our empirical studies find that RE may favor low-frequency queries from the pool for labeling while PV prioritizing high-frequency queries more. Finally, we combine these two complementary criteria as the sample selection strategies for active learning. Extensive experiments with comparisons to baseline algorithms show that the proposed approach could train LTR models achieving higher Discounted Cumulative Gain (i.e., the relative improvement {\Delta}DCG4=1.38%) with the same budgeted labeling efforts.
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
May 20, 2022



With the increasing diversity of ML infrastructures nowadays, distributed training over heterogeneous computing systems is desired to facilitate the production of big models. Mixture-of-Experts (MoE) models have been proposed to lower the cost of training subject to the overall size of models/data through gating and parallelism in a divide-and-conquer fashion. While DeepSpeed has made efforts in carrying out large-scale MoE training over heterogeneous infrastructures, the efficiency of training and inference could be further improved from several system aspects, including load balancing, communication/computation efficiency, and memory footprint limits. In this work, we present SE-MoE that proposes Elastic MoE training with 2D prefetch and Fusion communication over Hierarchical storage, so as to enjoy efficient parallelisms in various types. For scalable inference in a single node, especially when the model size is larger than GPU memory, SE-MoE forms the CPU-GPU memory jointly into a ring of sections to load the model, and executes the computation tasks across the memory sections in a round-robin manner for efficient inference. We carried out extensive experiments to evaluate SE-MoE, where SE-MoE successfully trains a Unified Feature Optimization (UFO) model with a Sparsely-Gated Mixture-of-Experts model of 12B parameters in 8 days on 48 A100 GPU cards. The comparison against the state-of-the-art shows that SE-MoE outperformed DeepSpeed with 33% higher throughput (tokens per second) in training and 13% higher throughput in inference in general. Particularly, under unbalanced MoE Tasks, e.g., UFO, SE-MoE achieved 64% higher throughput with 18% lower memory footprints. The code of the framework will be released on: https://github.com/PaddlePaddle/Paddle.
A Comparative Survey of Deep Active Learning
Mar 25, 2022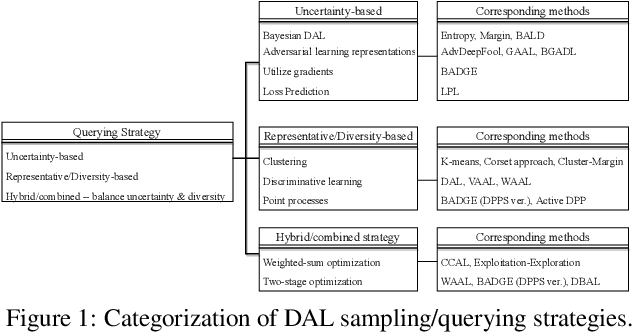
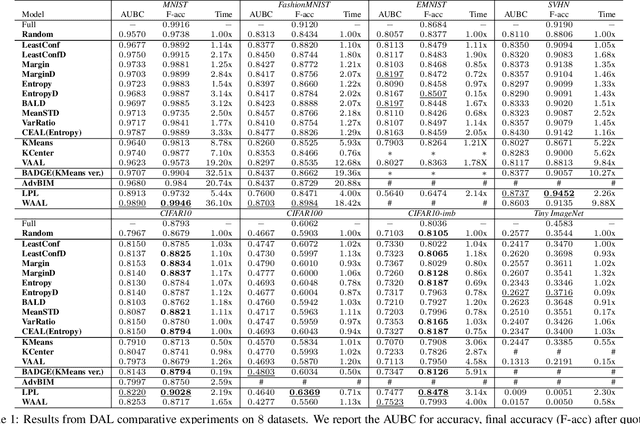
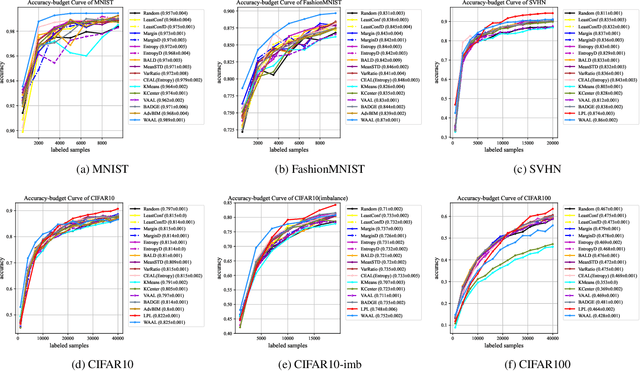
Active Learning (AL) is a set of techniques for reducing labeling cost by sequentially selecting data samples from a large unlabeled data pool for labeling. Meanwhile, Deep Learning (DL) is data-hungry, and the performance of DL models scales monotonically with more training data. Therefore, in recent years, Deep Active Learning (DAL) has risen as feasible solutions for maximizing model performance while minimizing the expensive labeling cost. Abundant methods have sprung up and literature reviews of DAL have been presented before. However, the performance comparison of different branches of DAL methods under various tasks is still insufficient and our work fills this gap. In this paper, we survey and categorize DAL-related work and construct comparative experiments across frequently used datasets and DAL algorithms. Additionally, we explore some factors (e.g., batch size, number of epochs in the training process) that influence the efficacy of DAL, which provides better references for researchers to design their own DAL experiments or carry out DAL-related applications. We construct a DAL toolkit, DeepAL+, by re-implementing many highly-cited DAL-related methods, and it will be released to the public.
PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
Dec 14, 2021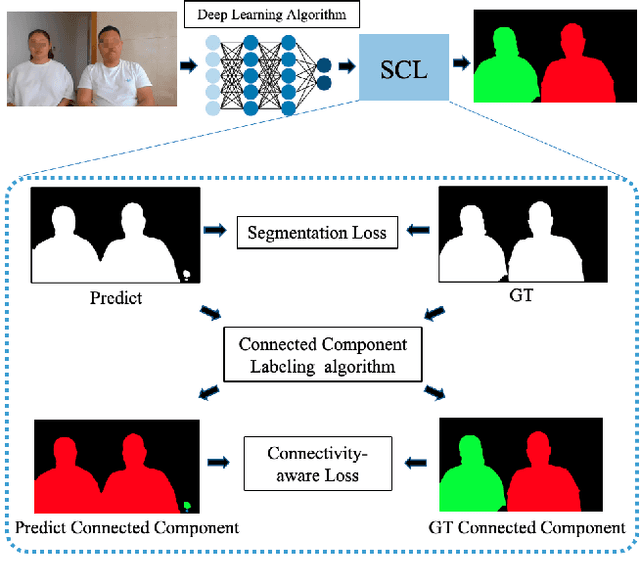


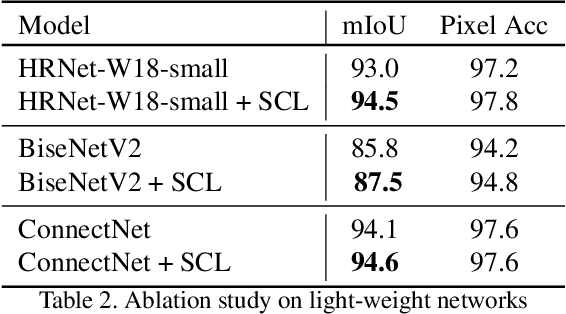
As the COVID-19 pandemic rampages across the world, the demands of video conferencing surge. To this end, real-time portrait segmentation becomes a popular feature to replace backgrounds of conferencing participants. While feature-rich datasets, models and algorithms have been offered for segmentation that extract body postures from life scenes, portrait segmentation has yet not been well covered in a video conferencing context. To facilitate the progress in this field, we introduce an open-source solution named PP-HumanSeg. This work is the first to construct a large-scale video portrait dataset that contains 291 videos from 23 conference scenes with 14K fine-labeled frames and extensions to multi-camera teleconferencing. Furthermore, we propose a novel Semantic Connectivity-aware Learning (SCL) for semantic segmentation, which introduces a semantic connectivity-aware loss to improve the quality of segmentation results from the perspective of connectivity. And we propose an ultra-lightweight model with SCL for practical portrait segmentation, which achieves the best trade-off between IoU and the speed of inference. Extensive evaluations on our dataset demonstrate the superiority of SCL and our model. The source code is available at https://github.com/PaddlePaddle/PaddleSeg.
SenseMag: Enabling Low-Cost Traffic Monitoring using Non-invasive Magnetic Sensing
Oct 24, 2021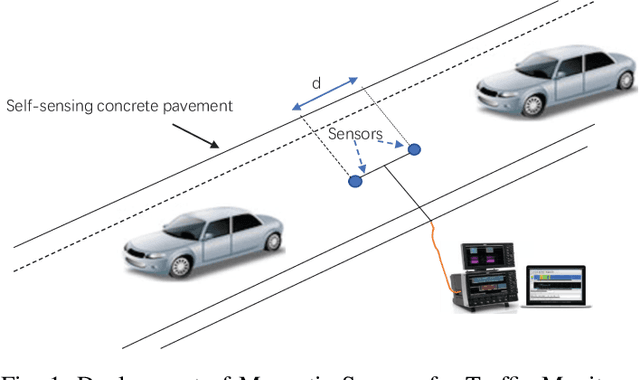

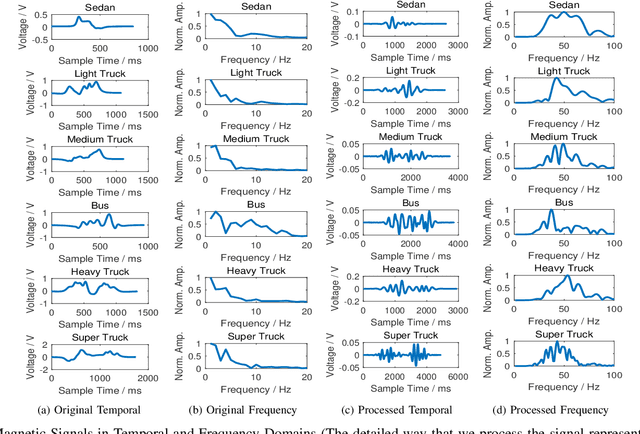
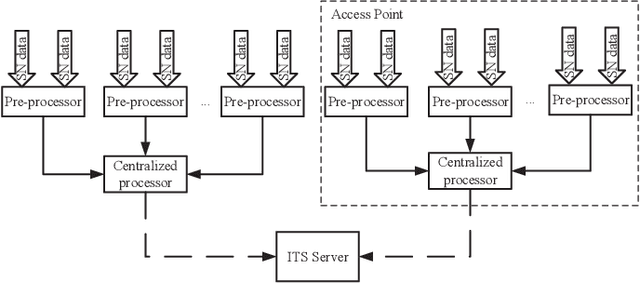
The operation and management of intelligent transportation systems (ITS), such as traffic monitoring, relies on real-time data aggregation of vehicular traffic information, including vehicular types (e.g., cars, trucks, and buses), in the critical roads and highways. While traditional approaches based on vehicular-embedded GPS sensors or camera networks would either invade drivers' privacy or require high deployment cost, this paper introduces a low-cost method, namely SenseMag, to recognize the vehicular type using a pair of non-invasive magnetic sensors deployed on the straight road section. SenseMag filters out noises and segments received magnetic signals by the exact time points that the vehicle arrives or departs from every sensor node. Further, SenseMag adopts a hierarchical recognition model to first estimate the speed/velocity, then identify the length of vehicle using the predicted speed, sampling cycles, and the distance between the sensor nodes. With the vehicle length identified and the temporal/spectral features extracted from the magnetic signals, SenseMag classify the types of vehicles accordingly. Some semi-automated learning techniques have been adopted for the design of filters, features, and the choice of hyper-parameters. Extensive experiment based on real-word field deployment (on the highways in Shenzhen, China) shows that SenseMag significantly outperforms the existing methods in both classification accuracy and the granularity of vehicle types (i.e., 7 types by SenseMag versus 4 types by the existing work in comparisons). To be specific, our field experiment results validate that SenseMag is with at least $90\%$ vehicle type classification accuracy and less than 5\% vehicle length classification error.
AgFlow: Fast Model Selection of Penalized PCA via Implicit Regularization Effects of Gradient Flow
Oct 07, 2021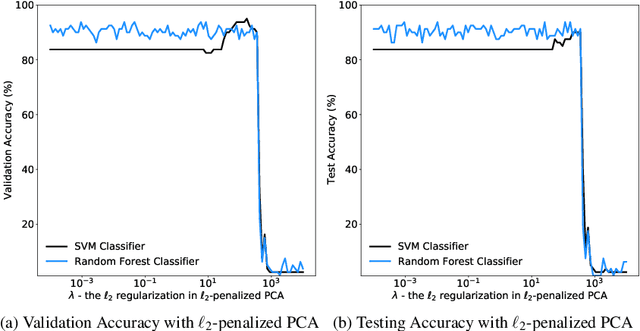
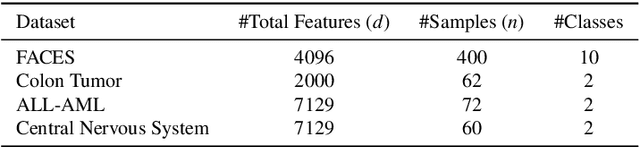
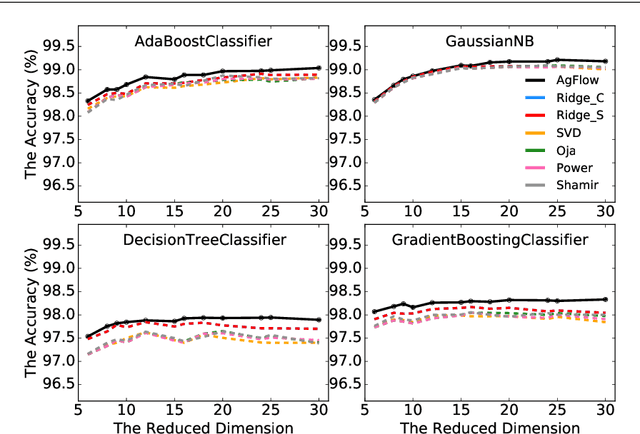
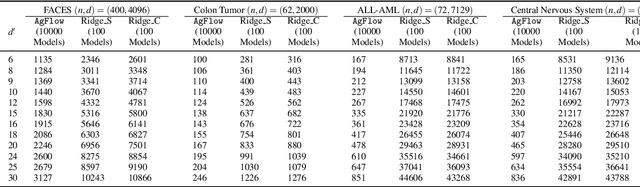
Principal component analysis (PCA) has been widely used as an effective technique for feature extraction and dimension reduction. In the High Dimension Low Sample Size (HDLSS) setting, one may prefer modified principal components, with penalized loadings, and automated penalty selection by implementing model selection among these different models with varying penalties. The earlier work [1, 2] has proposed penalized PCA, indicating the feasibility of model selection in $L_2$- penalized PCA through the solution path of Ridge regression, however, it is extremely time-consuming because of the intensive calculation of matrix inverse. In this paper, we propose a fast model selection method for penalized PCA, named Approximated Gradient Flow (AgFlow), which lowers the computation complexity through incorporating the implicit regularization effect introduced by (stochastic) gradient flow [3, 4] and obtains the complete solution path of $L_2$-penalized PCA under varying $L_2$-regularization. We perform extensive experiments on real-world datasets. AgFlow outperforms existing methods (Oja [5], Power [6], and Shamir [7] and the vanilla Ridge estimators) in terms of computation costs.
Exploring the Common Principal Subspace of Deep Features in Neural Networks
Oct 06, 2021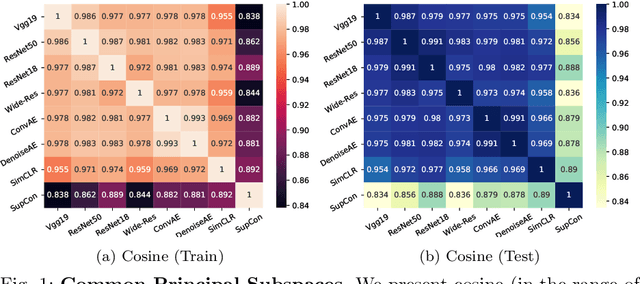

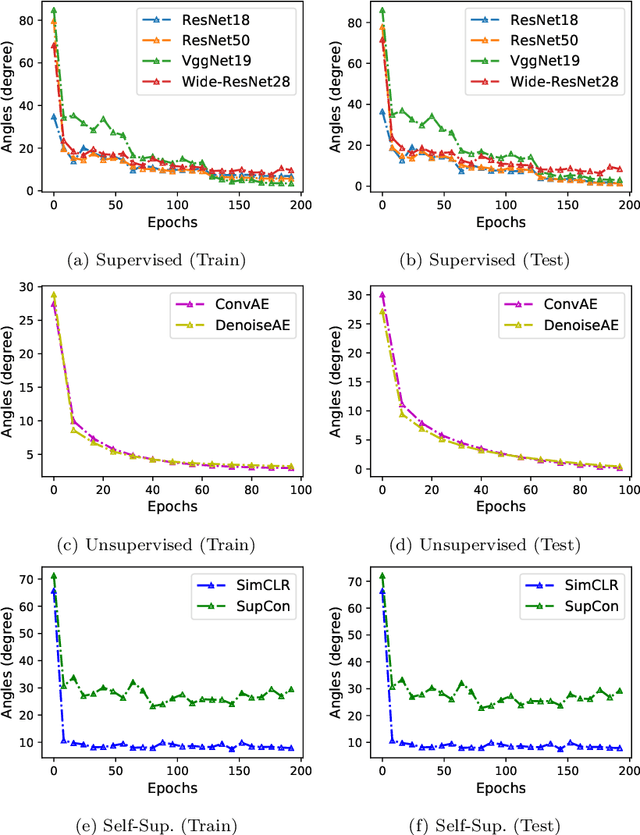
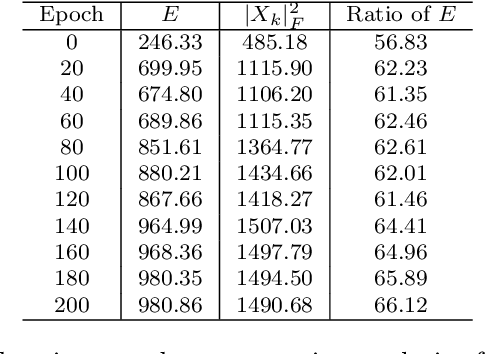
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features
Do What Nature Did To Us: Evolving Plastic Recurrent Neural Networks For Task Generalization
Sep 29, 2021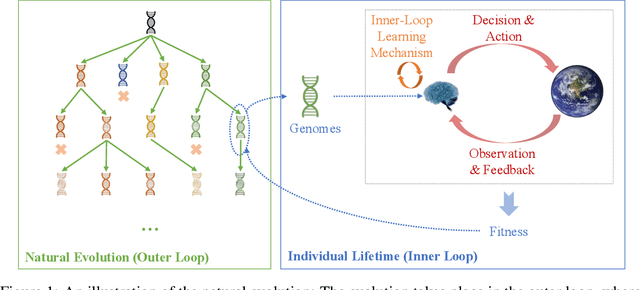
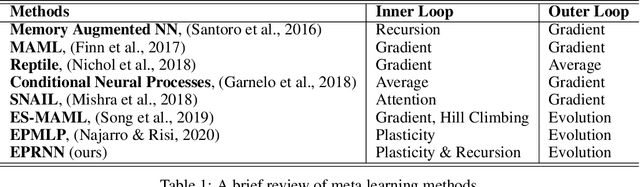
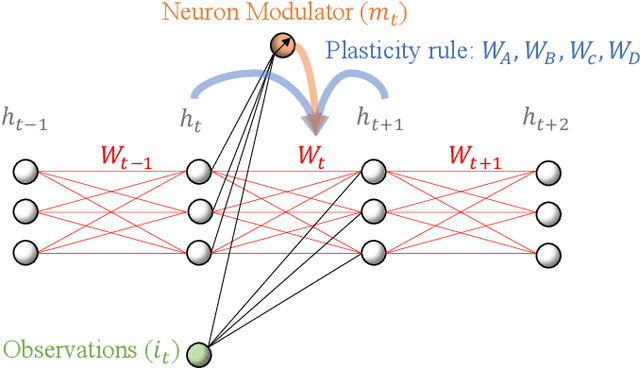

While artificial neural networks (ANNs) have been widely adopted in machine learning, researchers are increasingly obsessed by the gaps between ANNs and biological neural networks (BNNs). In this paper, we propose a framework named as Evolutionary Plastic Recurrent Neural Networks} (EPRNN). Inspired by BNN, EPRNN composes Evolution Strategies, Plasticity Rules, and Recursion-based Learning all in one meta learning framework for generalization to different tasks. More specifically, EPRNN incorporates with nested loops for meta learning -- an outer loop searches for optimal initial parameters of the neural network and learning rules; an inner loop adapts to specific tasks. In the inner loop of EPRNN, we effectively attain both long term memory and short term memory by forging plasticity with recursion-based learning mechanisms, both of which are believed to be responsible for memristance in BNNs. The inner-loop setting closely simulate that of BNNs, which neither query from any gradient oracle for optimization nor require the exact forms of learning objectives. To evaluate the performance of EPRNN, we carry out extensive experiments in two groups of tasks: Sequence Predicting, and Wheeled Robot Navigating. The experiment results demonstrate the unique advantage of EPRNN compared to state-of-the-arts based on plasticity and recursion while yielding comparably good performance against deep learning based approaches in the tasks. The experiment results suggest the potential of EPRNN to generalize to variety of tasks and encourage more efforts in plasticity and recursion based learning mechanisms.